Making Apache Spark the Fastest Open Source Streaming Engine
We started building Structured Streaming in Apache Spark one year ago as a new, simpler way to develop continuous applications. Not only does this new way make it easy to build end-to-end streaming applications by exposing a single API to write streaming queries as you would write batch queries, but it also handles streaming complexities by ensuring exactly-once-semantics, doing incremental stateful aggregations, and providing data consistency across sources and sinks.
Best-in-Class Performance
As we showed this morning at Spark Summit 2017, Structured Streaming is not only the simplest-to-use streaming engine, but for many workloads is also the fastest!
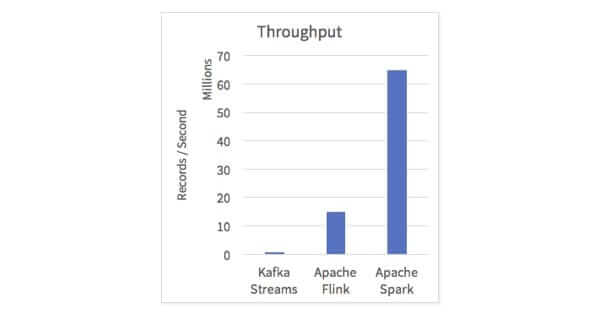
By leveraging all of the work done on the Catalyst query optimizer and the Tungsten execution engine, Structured Streaming brings the efficiency of Spark SQL to real-time streaming. In our benchmarks, we showed 5x or better throughput than other popular streaming engines on the widely used Yahoo! Streaming Benchmark.
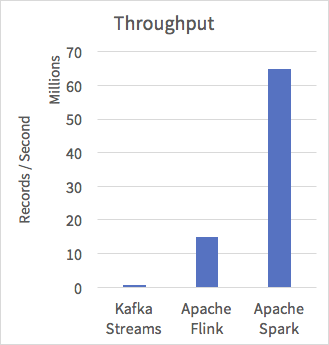
The above shows a comparison when running a modified version of the benchmark that generates the data in the framework. We ran on a similar setup, using 10 r3.xlarge machines (40 cores) running Spark 2.2.0-RC3. To let you reproduce these results, we will shortly release a blog with full source code runnable on Databricks. Note that for Kafka Streams, the data is still read from persistent storage as this is the only mode that is supported.
Best-in-Class Latency
Of course, throughput is only one metric for evaluating a streaming engine. Latency is also important for time-sensitive applications. Up until now, the minimum possible latency has been bounded by the microbatch-based architecture of Spark Streaming.
However, from the beginning, we carefully designed the API of Structured Streaming to be agnostic to the underlying execution engine, eliminating the concept of batching in the API. At Databricks, we have also been working to remove batching in the engine. Today, we are excited to propose a new extension, continuous processing, that also eliminates micro-batches from execution. As we demonstrated at Spark Summit this morning, this new execution mode lets users achieve sub-millisecond end-to-end latency for many important workloads -- with no change to their Spark application.
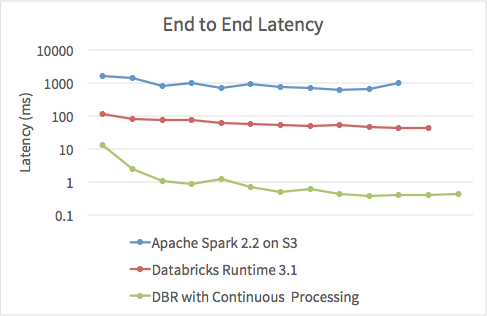
We have already built a working first version of continuous processing, and look forward to working with the community to contribute this extension to Apache Spark.
Efficient Streaming in the Cloud
Databricks customers can access the latest and greatest streaming features through the Databricks Runtime 3.0 beta, which includes the following new features from Apache Spark:
- Support for arbitrary complex stateful processing using [flat]MapGroupsWithState, allowing developers to write customized stateful aggregations such as sessionization or joining two streams.
- Support for reading and writing data in streaming or batch to/from Apache Kafka, giving developers ability to publish transformed streams to subsequent stages in a complex data pipeline upstream or update dashboards in real time.
- Support for production monitoring and alert management, providing engineers ways to survey metrics, inspect query progress, and write advanced monitoring applications with third-party alerting platforms.
In addition to the upstream improvements, Databricks Runtime 3.0 has optimized Structured Streaming specifically for the cloud deployments, including the following enhancements for running cloud workloads:
- Drastically reduce costs by combining the Once Trigger mode with the Databricks Job Scheduler.
- Easily monitor production streaming jobs with integrated throughput and latency metrics.
- Additionally support another source of streaming data from Amazon Kinesis.
Ready for Production
Finally, we are excited to announce that we at Databricks now consider Structured Streaming to be production ready and it is fully supported. At Databricks, our customers have already been using Structured Streaming and in the last month alone processed over 3 trillion records.
Read More
To explain how we and our customers employ Structured Streaming at scale, we have penned a half dozen blogs that cover many of the key aspects of Structured Streaming:
- Real-time Streaming ETL with Structured Streaming in Apache Spark 2.1
- Working with Complex Data Formats with Structured Streaming in Apache Spark 2.1
- Processing Data in Apache Kafka with Structured Streaming in Apache Spark 2.2
- Event-time Aggregation and Watermarking in Apache Spark’s Structured Streaming
- Taking Apache Spark’s Structured Structured Streaming to Production
- Once Trigger mode with the Databricks Job Scheduler

