Learn about Apache Spark’s Memory Model and Spark’s State in the Cloud
by Wenchen Fan and Nicolas Poggi
Since Apache Spark 1.6, as part of the Project Tungsten, we started an ongoing effort to substantially improve the memory and CPU efficiency of Apache Spark’s backend execution and push performance closer to the limits of the modern hardware. This effort culminated in Apache Spark 2.0 with Catalyst optimizer and whole-stage code generation.
Because Spark framework and APIs have been evolving very rapidly, providing better performance with each subsequent release, cloud providers are challenged to stay abreast with production services in the cloud and on-premises. So how do they keep up with these offerings?
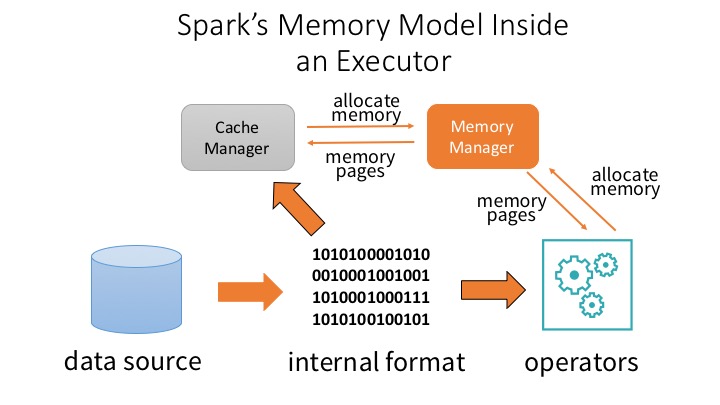
At the Data + AI Summit in Dublin, we will present talks on how Spark’s memory model has evolved and why it’s performant. We will also evaluate out-of-the-box support for Spark and compare the offerings, reliability, scalability, and price-performance from major PaaS providers. Here are our two talks that will cover these aspects of Spark:
Why should you attend these sessions? If you are a data architect or data engineer who wants to comprehend Spark’s underlying memory model or understand how to evaluate Spark offerings in the cloud, then attend our talks.
See you in Dublin!
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.