Introducing Built-in Image Data Source in Apache Spark 2.4

Introduction
With recent advances in deep learning frameworks for image classification and object detection, the demand for standard image processing in Apache Spark has never been greater. Image handling and preprocessing have their specific challenges - for example, images come in different formats (eg., jpeg, png, etc.), sizes, and color schemes, and there is no easy way to test for correctness (silent failures).
An image data source addresses many of these problems by providing the standard representation you can code against and abstracts from the details of a particular image representation.
Apache Spark 2.3 provided the ImageSchema.readImages API (see Microsoft’s post Image Data Support in Apache Spark), which was originally developed in the MMLSpark library. In Apache Spark 2.4, it’s much easier to use because it is now a built-in data source. Using the image data source, you can load images from directories and get a DataFrame with a single image column.
This blog post describes what an image data source is and demonstrates its use in Deep Learning Pipelines on the Databricks Unified Analytics Platform.
Image Import
Let’s examine how images can be read into Spark via image data source. In PySpark, you can import images as follows:
Similar APIs exist for Scala, Java, and R.
With an image data source, you can import a nested directory structure (for example, use a path like /path/to/dir/**). For more specific images, you can use partition discovery by specifying a path with a partition directory (that is, a path like /path/to/dir/date=2018-01-02/category=automobile).
Image Schema
Images are loaded as a DataFrame with a single column called “image.” It is a struct-type column with the following fields:
While most of the fields are self-explanatory, some deserve a bit of explanation:
nChannels: The number of color channels. Typical values are 1 for grayscale images, 3 for colored images (e.g., RGB), and 4 for colored images with alpha channel.
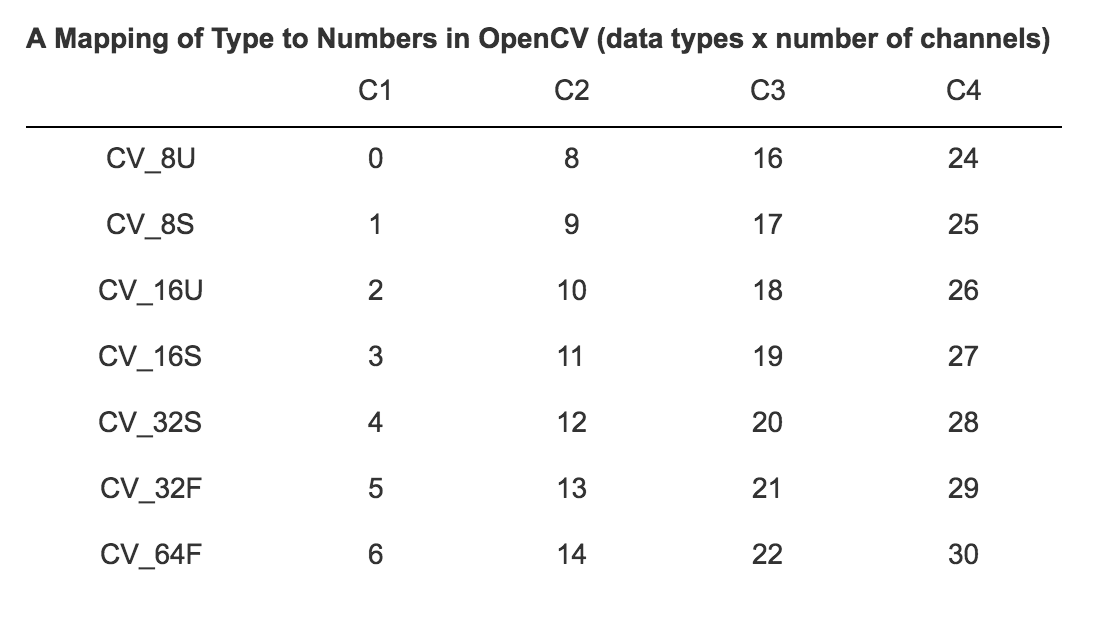
Mode: Integer flag that provides information on how to interpret the data field. It specifies the data type and channel order the data is stored in. The value of the field is expected (but not enforced) to map to one of the OpenCV types displayed below. OpenCV types are defined for 1, 2, 3, or 4 channels and several data types for the pixel values.
A Mapping of Type to Numbers in OpenCV (data types x number of channels):
data: Image data stored in a binary format. Image data is represented as a 3-dimensional array with the dimension shape (height, width, nChannels) and array values of type t specified by the mode field. The array is stored in row-major order.
Channel Order
Channel order specifies the ordering in which the colors are stored. For example, if you have a typical three channel image with red, blue, and green components, there are six possible orderings. Most libraries use either RGB or BGR. Three (four) channel OpenCV types are expected to be in BGR(A) order.
Your compact guide to modern analytics

Code Sample
Deep Learning Pipelines provides an easy way to get started with ML for using images. Starting from version 0.4, Deep Learning Pipelines uses the image schema described above as its image format, replacing former image schema format defined within the Deep Learning Pipelines project.
In this Python example, we use transfer learning to build a custom image classifier:
Note: For Deep Learning Pipelines developers, the new image schema changes the ordering of the color channels to BGR from RGB. To minimize confusion, some of the internal APIs now require you to specify the ordering explicitly.
What’s Next
It would be helpful if you could sample the returned DataFrame via df.sample, but sampling is not optimized. To improve this, we need to push down the sampling operator to the image data source so that it doesn’t need to read every image file. This feature will be added in DataSource V2 in the future.
New image features are planned for future releases in Apache Spark and Databricks, so stay tuned for updates. You can also try the deep learning example notebook in Databricks Runtime 5.0 ML.
Read More
For further reading on Image Data Source, and how to use it:
- Read our documentation on Image Data Source for Azure and AWS.
- Try the example notebook on Databricks Runtime 5.0 ML.
- Learn about Deep Learning Pipelines.
- Visit the Deep Learning Pipelines on GitHub.
Acknowledgments
Thanks to Denny Lee, Stephanie Bodoff, and Jules S. Damji for their contributions.