A Guide to AI, Machine Learning, and Deep Learning Talks at Spark + AI 2019
by Jules Damji
To a good degree, this back-of-the-envelope flowchart, by Karen Hao of MIT Technology Review, charts to elucidate what constitutes the use of AI in the grand scheme of things.
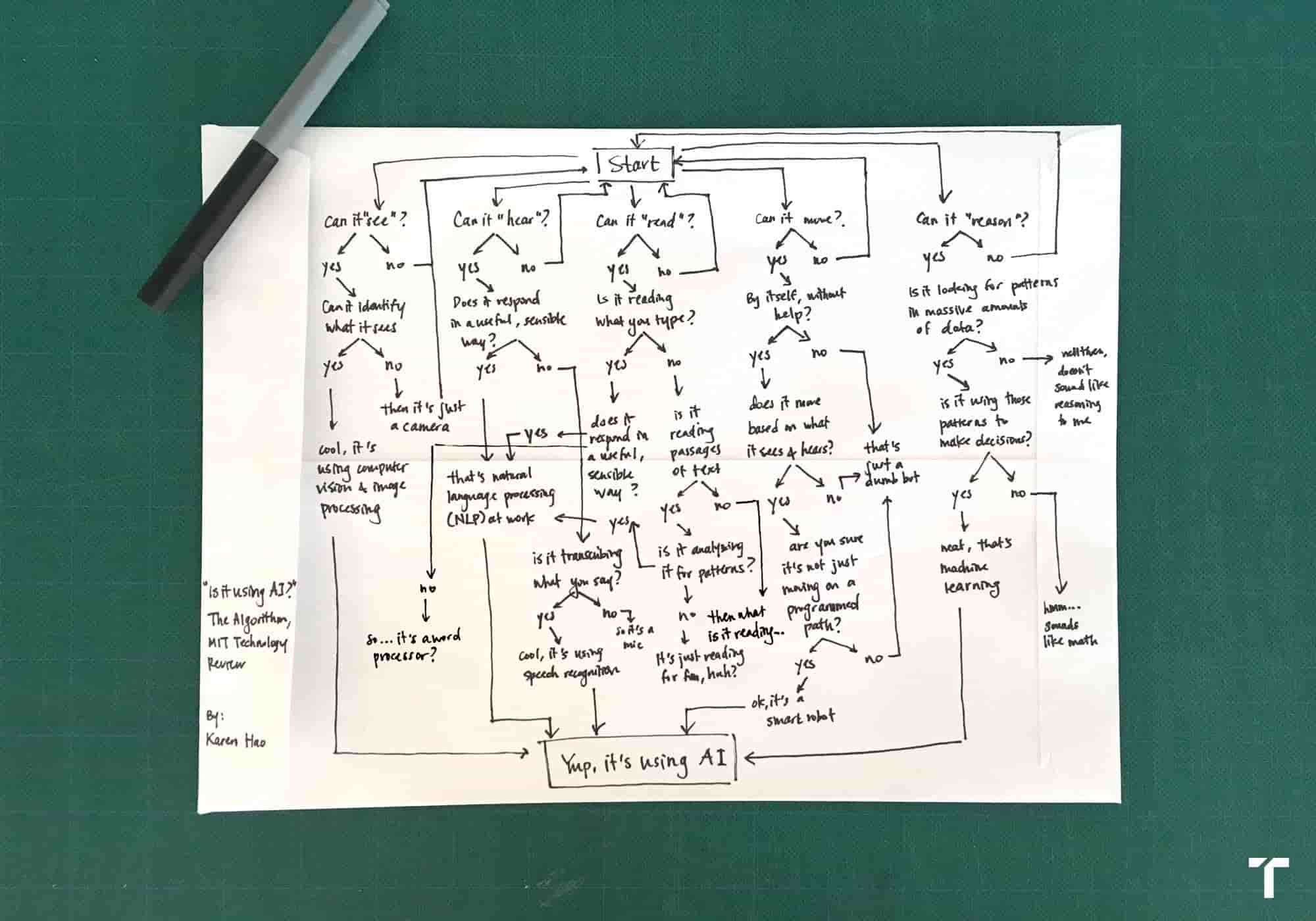
While many conferences may not have a flowchart to select sessions to identify what’s AI, the sessions, though, do speak to technical aspects that comprise AI in their use cases—be it machine learning or deep learning techniques used.
For Spark + AI Summit 2019, we have seen high-caliber technical talks as part of AI, Productionizing ML, and Deep Learning Techniques tracks. In this blog, we highlight a few talks that caught our eye, for they hold promise in their potential. It helps to have navigational guidance (of course, not as elaborate as the flowchart above).
AI Use Cases
So let’s start with a few AI use cases, especially in the realm of creative arts.
Generative Adversarial Networks (GANS) were introduced by Ian Goodfellow et. al. in 2014 paper. Since then its use has taken a creative form in generating digital drawings. J. Rosenbaum's talk, The Future of Art: Creepy, Frivolous and Beautiful Art Made with Machines, explores the effects of digital art. Looking at the uses of machine learning and how it impacts the future of art, he asks what is art like when artists and musicians work collaboratively with machines, its frivolity or beauty? A fascinating foray into digital drawings using GANs.
Leaving creative arts aside, AI has made headway into health sciences. For example, it’s not uncommon to read about AI-based applications using CNN-based deep learning techniques to identify objects within medical images. Fei Hu takes us into his journey and details how he uses a two-staged CNN-based model to detect mitosis, with a high degree of accuracy, in his talk: A distributed deep learning approach for the mitosis detection from big medical images.
Closely related to the above talk in technological advances in health sciences is Using Deep Learning on Apache Spark to Diagnose Thoracic Pathology from Chest X-rays session from Bala Chandrasekaran. He demonstrates how you can build an AI-based Radiologist system using Apache Spark and Analytics Zoo to detect pneumonia and other diseases from chest x-ray images.
On the drug discovery and design front, the process of rational drug design has been in place for many decades, using traditional machine learning based techniques. However, Peyvand Khademi covers some of the major areas where the new application of AI, Deep learning and ML-based techniques augment the process. Specifically, he covers a variety of drug safety-related AI and ML-based techniques in his talk: Assessing Drug Safety using AI. As part of these techniques, he uses hierarchical classification methodology to asses toxicity of a given compound.
For a big data practitioner interested in how AI is used in health sciences, these three talks will resonate.
Distributed Deep Learning Techniques
The recent release of Apache Spark 2.4 introduced a scheduler to support barrier execution mode for better integration with MPI-based programs, e.g., distributed deep learning frameworks such as TensorFlow and PyTorch. Two sessions speak at length about different strategies and schemes to do distributed training using Horovod.
Databricks’ Xiangrui Meng elaborates on Project Hydrogen, an Apache Spark initiative to bring state-of-the-art AI and Big Data solutions together. His session on Updates from Project Hydrogen: Unifying State-of-the-Art AI and Big Data in Apache Spark covers distributed training built atop Horovod and Distributed TensorFlow.
Likewise, Jim Dowling in his session, ROCm and Distributed Deep Learning on Spark and TensorFlow, also discusses a similar approach at doing distributed training using ROCm, the Radeon Open Ecosystem, which incorporates aspects of Project Hydrogen.
Both these talks will appeal to machine learning engineers who look at doing distributed training using TensorFlow or PyTorch.
Productionizing Machine Learning
Now, training a deep learning or machine model is one stage in a developmental lifecycle of the machine learning model. Another is experimentation, deployment, and productionizing of these models.
The next few sessions address some of the challenges in these stages.
Consider hyperparameters’ searching, tunning, and tracking of experiments with MLflow. Databricks’ Aaron Davidson elaborates in his talk the Best Practices for Hyperparameter Tuning with MLflow. Similarly, Kevin Kuo complements and demonstrates how this end-to-end lifecycle from development to deployment is achieved with MLflow in his talk: Streamlining AI prototyping and deployment with R and MLflow.
Continuing on the same lifecycle theme, Clemens Mewald in his talk TensorFlow Extended: An end-to-end machine learning platform for TensorFlow offers an insight into how to manage the end-to-end training and production of model management, versioning, and serving.
Coordinating and Managing at Massive Scale
Data and AI are all about scale—about productizing ML models, about coordination among functional groups, about managing data infrastructure that supports the ML code. Four talks seem to fit the bill that you as a data scientist, data engineer or an ML engineer will appreciate.
First is from Wai Chee Kuo of Zendesk, aptly titled The More the Merrier - Scaling Model Building Infrastructure at Zendesk. Kuo shares how close collaboration with different groups—product, data science, and engineering—is imperative and discusses how their scaling of infrastructure facilitates building and deploying 50,000 models a day!
Second, James Norman, lead engineer at Nike, reveals Enabling Data Scientists to Bring Their Models to Market. By reducing effort and friction of coordination with engineering to bring models to production, Nike is able to automate ML pipelines, job scheduling, A/B testing, and serving at scale. Find out how they do it in this session.
Third, the talk from Uber’s Anne Holler and Michael Mui on Michelangelo Using Spark MLlib Models in a Production Training and Serving Platform: Experiences and Extensions supports training, serving, and productionizing thousands of models in production. Most of its models are developed using Apache Spark MLlib.
Last, George Williams of Computing and Data Science at GSI Technology expands on vulnerabilities such as Spectre and Meltdown that plague many production servers. In his talk, Scaling ML-based Threat Detection For Production Cyber Attacks, he elaborates how to deploy models at scale using the ONXY machine learning open file format and the challenges in deploying ML-based cyber-threat detection at scale using Apache Spark.
Deep Learning Classes
And finally, if you’re new to TensorFlow or Keras and want to learn how to use Horovod for distributed training, you can enroll in a training course: Hands-on Deep Learning with Keras, Tensorflow, and Apache Spark.
What’s Next
While you may use a flowchart quickly to assess what’s AI, it’s well to take this guide if you are new to the conference. Of course, you may also peruse and pick sessions from the schedule too.
In the next blog, we will share our picks from sessions related to Developer, Deep Dives, and Structured Streaming and Continous Applications.
If you have not registered yet, use this code JulesPicks and get 15% discount. See you there!
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.