MLflow v0.9.0 Features SQL Backend, Projects in Docker, and Customization in Python Models

Read Rise of the Data Lakehouse to explore why lakehouses are the data architecture of the future with the father of the data warehouse, Bill Inmon.
MLflow v0.9.0 was released today. It introduces a set of new features and community contributions, including SQL store for tracking server, support for MLflow projects in Docker containers, and simple customization in Python models. Additionally, this release adds a plugin scheme to customize MLflow backend store for tracking and artifacts.
Now available on PyPi and with docs online, you can install this new release with pip install mlflow as described in the MLflow quickstart guide.
In this post, we will elaborate on a set of MLflow v0.9.0 features:
- An efficient SQL compatible backend store for tracking scales experiments in the thousands.
- A plugin scheme for tracking artifacts extends backend store capabilities.
- Ability to run MLflow projects in Docker Containers allows extensibility and stronger isolation during execution.
- Ability to customize Python models injects post and preprocessing logic in a python_func model flavor.
SQL Backend Store for Tracking
For thousands of MLflow runs and experimental parameters, the default File store tracking server implementation does not scale. Thanks to the community contributions from Anderson Reyes, the SQLAlchemy store, an open-source SQL compatible store for Python, addresses this problem, providing scalable and performant store. Compatible with other SQL stores (such as MySQL, PostgreSQL, SQLite, and MS SQL), developers can connect to a local or remote store for persisting their experimental runs, parameters, and artifacts.
Logging Runtimes Performance
We compared the logging performance of MySQL-based SqlAlchemyStore against FileStore. The setup involved 1000 runs spread over five experiments running on a MacBook Pro with four cores on Intel i7 and 16GB of memory. (In a future blog, we plan to run this benchmark on a large EC2 machine expecting even better performance.)
Measuring logging performance averaging over thousands of operations, we saw about 3X speed-up when using a database-backed store, as shown in Fig.1.
Furthermore, we stress-tested with multiple clients scaling up to 10 concurrent clients logging metrics, params, and tags to the backend store. While both stores show a linear increase in runtimes per operation, the database-backed store continued to scale with large concurrent loads.
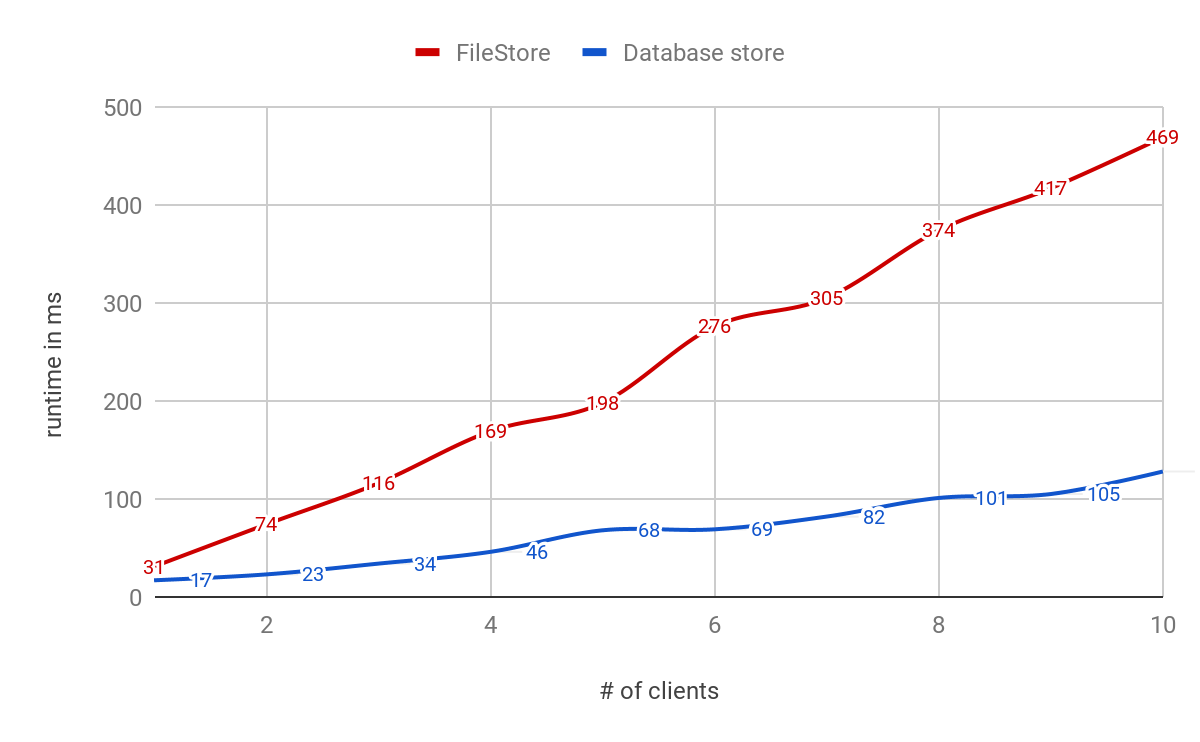
Search Runtime Performance
Performance of Search and Get APIs showed a significant performance boost. The following comparison shows search runtimes for the two store types over an increasing number of runs.
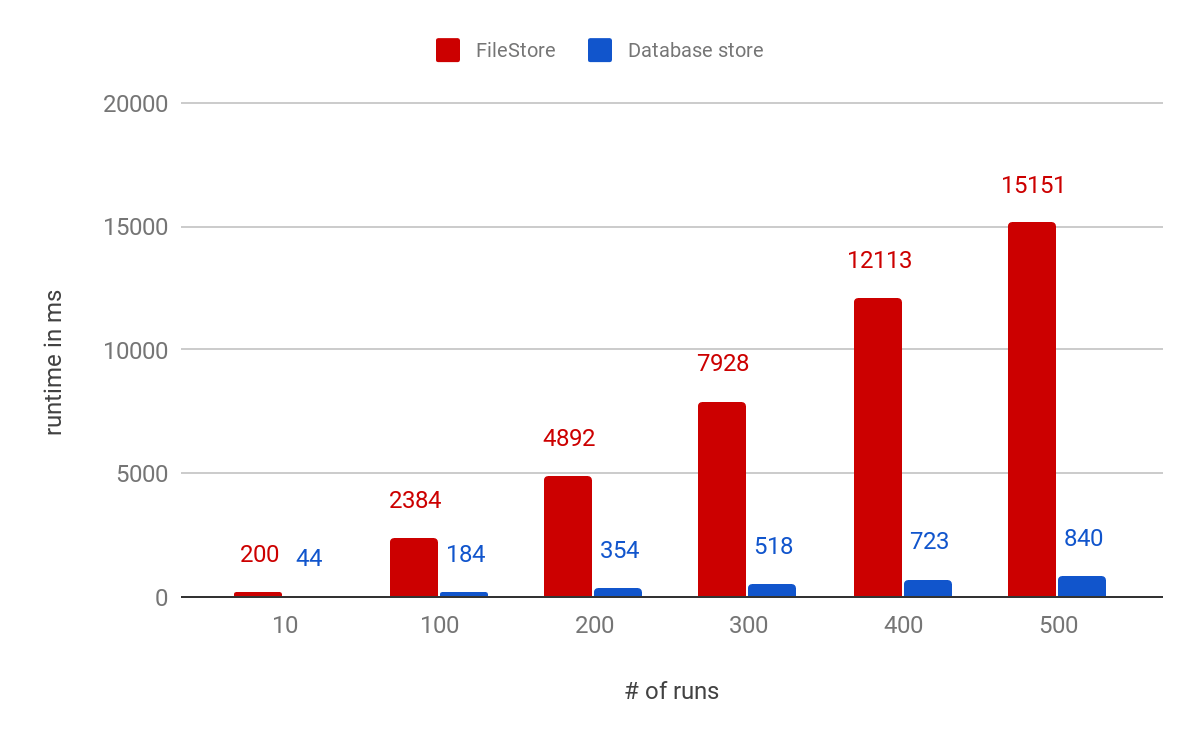 Fig.2 Search Runtime Performance
Fig.2 Search Runtime PerformanceFor more information about backend store setup and configuration, read the documentation on Tracking Storage.
Customized Plugins for Backend Store
Even though the internal MLflow pluggable architecture enables different backends for both tracking and artifact stores, it does not provide an ability to add new providers to plug in handlers for new backends.
A proposal for MLflow Plugin System from the community contributors Andrew Crozier and Víctor Zabalza now enables you to register your store handlers with MLflow. This scheme is useful for a few reasons:
- Allows external contributors to package and publish their customized handlers
- Extends tracking capabilities and integration with stores available on other cloud platforms
- Provides an ability to provide a separate plugin for tracking and artifacts if desired
Central to this pluggable scheme is the notion of entrypoints, used effectively in other Python packages, for example, pytest, papermill, click etc. To integrate and provide your MLflow plugin handlers, say for tracking and artifacts, you will need to two class implementations: TrackingStoreRegistery and ArtifactStoreRegistery.
For a detail explanation on how to implement, register, and use this pluggable scheme for customizing backend store, read the proposal and its implementation details.
Projects in Docker Containers
Besides running MLflow projects within a Conda environment, with the help of community contributor Marcus Rehm, this release extends your ability to run MLflow projects within a Docker container. It has three advantages. First, it allows you to capture non-Python dependencies such as Java libraries. Second, it offers stronger isolation while running MLflow projects. And third, it opens avenues for future capabilities to add tools to MLflow for running other dockerized projects, for example, on Kubernetes clusters for scaling.
To run MLflow projects within Docker containers, you need two artifacts: Dockerfile and MLProject file. The Docker file expresses your dependencies how to build a Docker image, while the MLProject file specifies the Docker image name to use, the entry points, and default parameters to your model.
With two simple commands, you can run your MLflow project in a Docker container and view the runs’ results, as shown in the animation below. Take note that environment variable such as MLFLOW_TRACKING_URI is preserved in the container, so you can view its runs’ metrics in the MLflow UI.
docker build . -t mlflow-docker-examplemlflow run . -P alpha=0.5
https://www.youtube.com/watch?v=74HF2CRFY_4
Simple Python Model Customization
Often, ML developers want to build and deploy models that include custom inference logic (e.g., preprocessing, postprocessing or business logic) and data dependencies. Now you can create custom Python models using new MLflow model APIs.
To build a custom Python model, extend the mlflow.pyfunc.PythonModel class:
The load_context() method is used to load any artifacts (including other models!) that your model may need in order to make predictions. You define your model’s inference logic by overriding the predict() method.
The new custom models documentation demonstrates how PythonModel can be used to save XGBoost models with MLflow; check out the XGBoost example!
For more information about the new model customization features in MLflow, read the documentation on customized Python models.
Other Features and Bug Fixes
In addition to these features, several other new pieces of functionality are included in this release. Some items worthy of note are:
Features
- [CLI] Add CLI commands for runs: now you can list, delete, restore, and describe runs through the CLI (#720, @DorIndivo)
- [CLI] The run command now can take
--experiment-nameas an argument, as an alternative to the--experiment-idargument. You can also choose to set the _EXPERIMENT_NAME_ENV_VAR environment variable instead of passing in the value explicitly. (#889, #894, @mparke) - [R] Support for HTTP authentication to the Tracking Server in the R client. Now you can connect to secure Tracking Servers using credentials set in environment variables, or provide custom plugins for setting the credentials. As an example, this release contains a Databricks plugin that can detect existing Databricks credentials to allow you to connect to the Databricks Tracking Server. (#938, #959, #992, @tomasatdatabricks)
- [Models] PyTorch model persistence improvements to allow persisting definitions and dependencies outside the immediate scope:
- Add a code_paths parameter to
mlflow.pytorch.save_model()andmlflow.pytorch.log_model()to allow external module dependencies to be specified as paths to python files. (#842, @dbczumar). - Improve mlflow.pytorch.save_model to capture class definitions from notebooks and the main scope (#851, #861, @dbczumar)
- Add a code_paths parameter to
The full list of changes, bug fixes, and contributions from the community can be found in the 0.9.0 Changelog. We welcome more input on [email protected] or by filing issues on GitHub. For real-time questions about MLflow, we also offer a Slack channel. Finally, you can follow @MLflow on Twitter for the latest news.
Credits
We want to thank the following contributors for updates, doc changes, and contributions in MLflow 0.9.0: Aaron Davidson, Ahmad Faiyaz, Anderson Reyes, Andrew Crozier, Corey Zumar, DorIndivo, Dmytro Aleksandrov, Hanyu Cui, Jim Thompson, Kevin Kuo, Kevin Yuen, Matei Zaharia, Marcus Rehm, Mani Parkhe, Maitiú Ó Ciaráin, Mohamed Laradji, Siddharth Murching, Stephanie Bodoff, Sue Ann Hong, Taneli Mielikäinen, Tomas Nykodym, Víctor Zabalza, 4n4nd

