Protecting the Securities Market with Predictive Fraud Detection
by Michael Ortega and Navin Albert
FINRA (Financial Industry Regulatory Authority), a regulatory body charged with protecting the U.S. securities market, spoke at the Spark + AI Summit on how they use Databricks Unified Analytics Platform to analyze up to a 100 billion stock market events per day for fraud detection and prevention. This is a summary of their story from Summit.
Interested in learning how to detect financial fraud with machine learning and Apache Spark? Watch our webinar on Detecting Financial Fraud at Scale with Machine Learning for a step-by-step walkthrough on how to build a financial fraud model at scale including a live demo.
Every investor in America relies on one thing: fair financial markets. FINRA is a regulatory body charged with protecting investors by ensuring that the U.S. securities industry operates in an honest and fair manner.
FINRA does this by running surveillance on 99% of the equity markets and around 70% of the options markets. For example, they look to curb fraudulent or unfair behavior such as collusion among various parties to manipulate the market in their favor. FINRA accomplishes this by capturing feeds of transaction data from the various securities markets and then running machine learning algorithms against the data to identify behavior that is indicative of something out of the ordinary or identify a known pattern of fraudulent behavior and then flag these anomalies and take action on them. However, prior to adopting Databricks, FINRA ran into numerous challenges.
The Challenge: Massive Data, Fragmented Teams
On the road to providing AI-powered fraud detection, FINRA faced a number of challenges including massive volumes of fragmented data, inadequate tooling, and siloed teams.
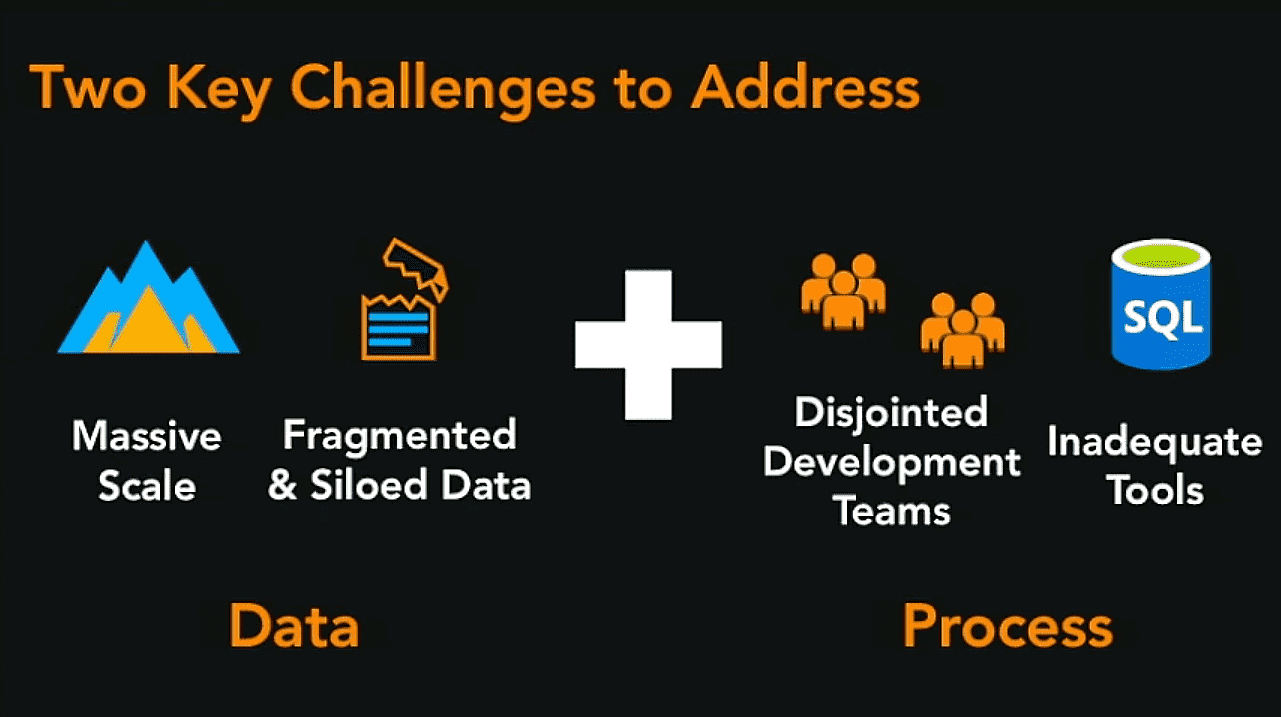
Fragmented Data - prior to using Databricks, due to the data being stored in disparate on-premise systems, it was highly complex and costly to build performant and reliable data pipelines that could scale to support the volumes of data they were ingesting— more than 100 billion events per day. It was nearly impossible to explore and visualize the data freely as they were locked down, and getting access involved cumbersome processes.
Inadequate ML Tools - FINRA used a series of tools and systems to develop their fraud models. In production, they used SQL rules which were highly complex requiring hundreds of pages of SQL statements with all sorts of subclauses. These queries were very difficult to develop, debug and had performance issues. Further, the code was not modular and could not be changed or improved very easily.
Siloed Teams - their disjointed analytics workflows resulted in a number of problems for FINRA including lack of code reuse and limited collaboration across data science and engineering teams. On a given project, the data scientist would first investigate the problem and then build and train their models in R or Python. Once the models were ready for production, the engineering team would then take that output from the data science team and rewrite it in SQL in order to deploy into production. This resulted in very long development cycles, and most importantly, highly inaccurate models that didn’t achieve the ultimate goal of identifying patterns of malicious behavior.
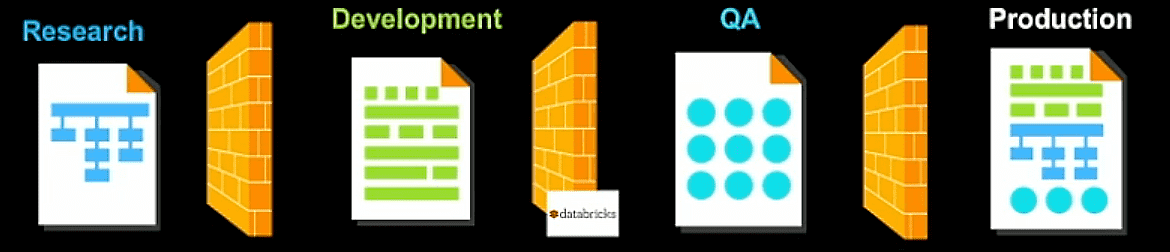
The Solution: Moving Towards a Unified, ML-driven Environment
FINRA's data teams knew they were running uphill with the inherent complexities of their legacy workflow. Databricks provides FINRA with a unified analytics platform that democratizes data and brings previously siloed teams together, cutting down the overall time to market, increasing the reusability of feature libraries, and improving operational efficiency.
"With Databricks, we have one cohesive end-to-end process with one single unified team working on protecting the securities markets." —Vincent Saulys, Senior Director, Advanced Surveillance Development, FINRA
As a fully managed cloud service, FINRA’s data science team is able to focus on higher-level issues related to the domain of machine learning rather than DevOps work. Provisioning compute clusters on-demand with a powerful cluster manager that offers auto-scaling and auto-termination for optimal operational efficiency, so they never have to worry about the various complexities that are under the hood.
The interactive workspace, with robust support for multiple programming languages including SQL, Scala, R, and Python, allows FINRA’s data scientists to overcome silos to iterate faster and collaborate better. The easy to use notebook interface and cluster manager has allowed all users of various disciplines to participate in developing machine learning models.
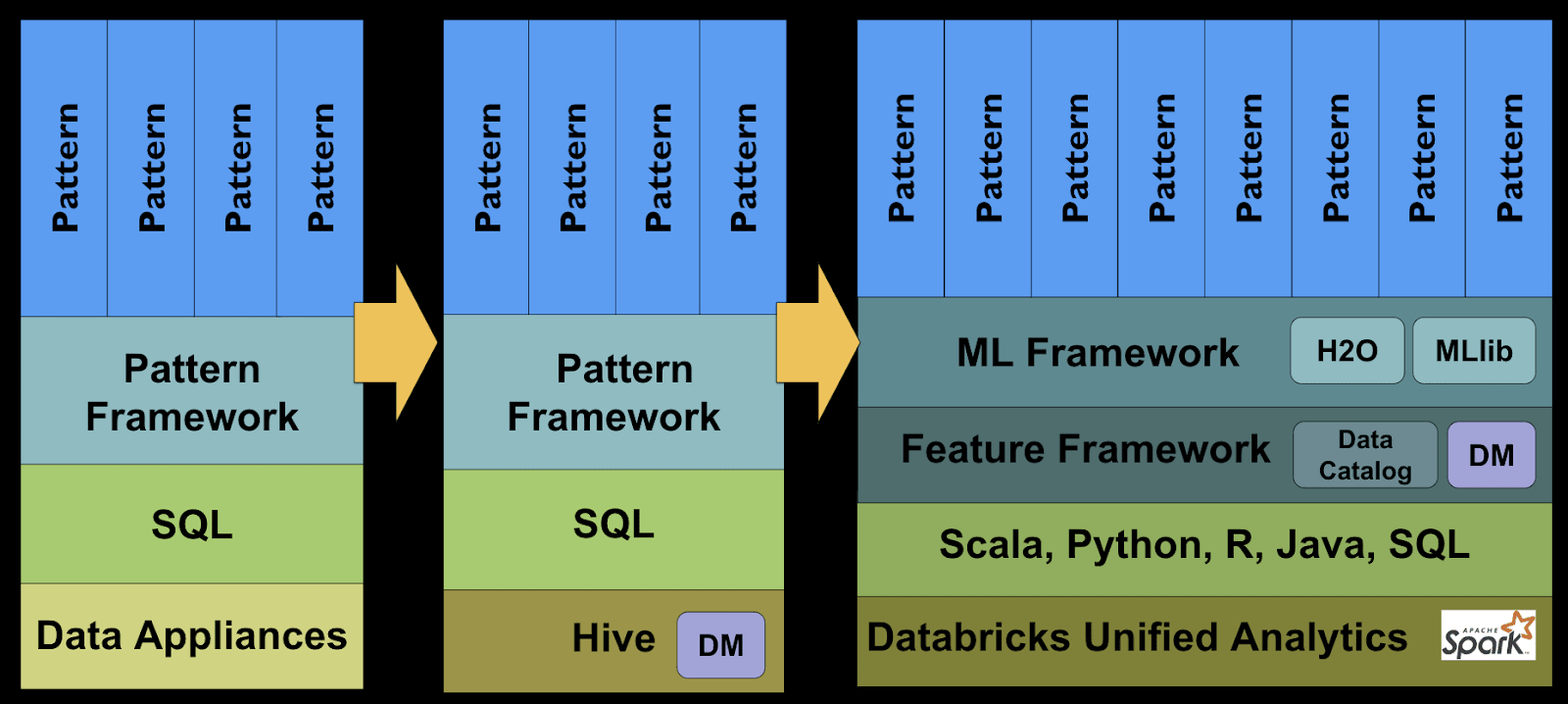
To build a machine-learning model, FINRA had to develop a Feature Framework. The SQL patterns were split into simple functions that can be used repeatedly on various models. The resulting ML models developed was so modular, features could be changed or modified anytime. This was difficult or almost impossible to do with large complex SQL statements. Further human feedback and additional features were used to improve the models over time.
This has removed the barriers to leverage machine learning in their environment, reducing the overall time-to-market required on ingest and prepare data; and build, train, and deploy models to detect anomalous patterns that can impact traders.
The Impact
Databricks has had a very positive impact on FINRA. For one, the development process for new machine learning models has been streamlined with collaborative workspaces for data ingest, model development and training. This allows developers and data scientists to do more experimentation and iteration, resulting in better and more accurate models deployed much more easily into production.
The biggest gains have been from a direct result of the significant reduction in time and resources spent on DevOps work. This has allowed FINRA’s data teams to focus on their areas of expertise without getting bogged down with low-level tasks to support the infrastructure. As a result, they have been able to shift their investments towards solving business problems and away from the necessities of getting data enabled for machine learning.
What's Next
At FINRA, data is the business! Data is not just a representation of what may happen in securities markets, but it is what actually happens. Moving forward, Databricks will continue to be the cornerstone of FINRA's analytics strategy — empowering them to use machine learning and advanced analytic techniques to find better and more accurate ways to identify anomalies in data and curb malicious trading behavior.
Learn More
- Watch the webinar on Detecting Financial Fraud at Scale with Machine Learning
- Watch FINRA's keynote from Spark + AI Summit 2018
- Learn more about Databricks for Financial Services
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.