Democratizing Financial Time Series Analysis with Databricks

Try this notebook in Databricks
Introduction
The role of data scientists, data engineers, and analysts at financial institutions includes (but is not limited to) protecting hundreds of billions of dollars worth of assets and protecting investors from trillion-dollar impacts, say from a flash crash. One of the biggest technical challenges underlying these problems is scaling time series manipulation. Tick data, alternative data sets such as geospatial or transactional data, and fundamental economic data are examples of the rich data sources available to financial institutions, all of which are naturally indexed by timestamp. Solving business problems in finance such as risk, fraud, and compliance ultimately rests on being able to aggregate and analyze thousands of time series in parallel. Older technologies, which are RDBMS-based, do not easily scale when analyzing trading strategies or conducting regulatory analyses over years of historical data. Moreover, many existing time series technologies use specialized languages instead of standard SQL or Python-based APIs.
Fortunately, Apache Spark™ contains plenty of built-in functionality such as windowing which naturally parallelizes time-series operations. Moreover, Koalas, an open-source project that allows you to execute distributed Machine Learning queries via Apache Spark using the familiar pandas syntax, helps extend this power to data scientists and analysts.
In this blog, we will show how to build time series functions on hundreds of thousands of tickers in parallel. Next, we demonstrate how to modularize functions in a local IDE and create rich time-series feature sets with Databricks Connect. Lastly, if you are a pandas user looking to scale data preparation which feeds into financial anomaly detection or other statistical analyses, we use a market manipulation example to show how Koalas makes scaling transparent to the typical data science workflow.
Set-Up Time Series Data Sources
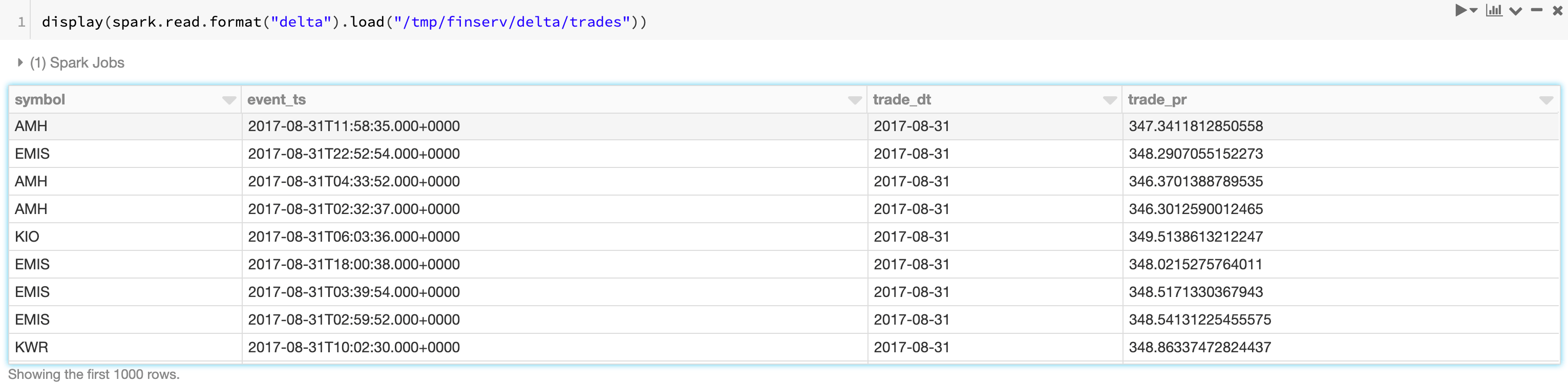
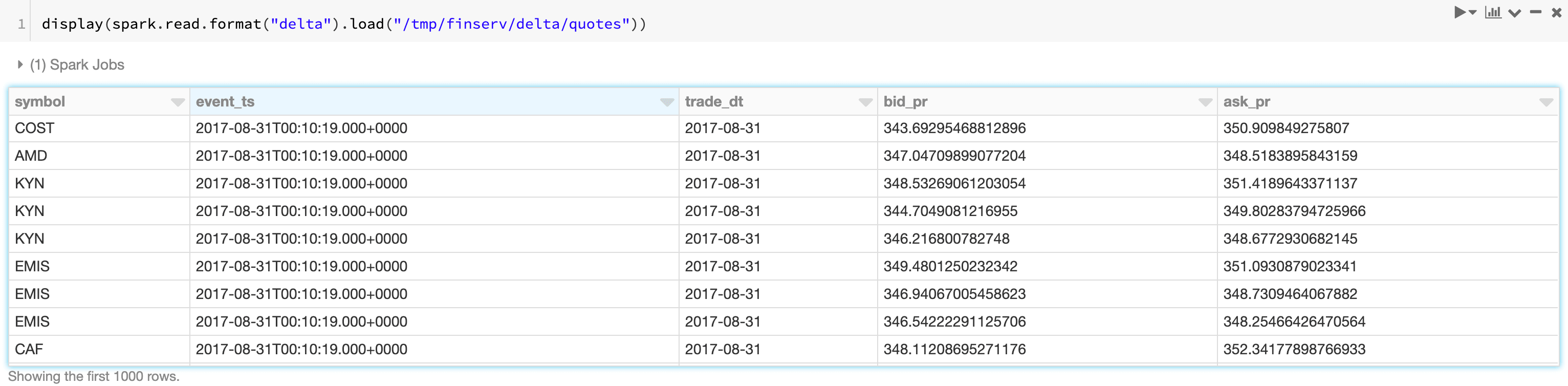
Let’s begin by ingesting a couple of traditional financial time series datasets: trades and quotes. We have simulated the datasets for this blog, which are modeled on data received from a trade reporting facility (trades) and the National Best Bid Offer (NBBO) feed (from an exchange such as the NYSE). You can find some example data here: https://www.tickdata.com/product/nbbo/.
This article generally assumes basic financial terms; for more extensive references, see Investopedia’s documentation. What is notable from the datasets below is that we’ve assigned the TimestampType to each timestamp, so the trade execution time and quote change time have been renamed to event_ts for normalization purposes. In addition, as shown in the full notebook attached in this article, we ultimately convert these datasets to Delta format so that we ensure data quality and keep a columnar format, which is most efficient for the type of interactive queries we have below.
Merging and Aggregating Time Series with Apache Spark™
There are over six hundred thousand publicly traded securities globally today in financial markets. Given our trade and quote datasets span this volume of securities, we’ll need a tool that scales easily. Because Apache Spark™ offers a simple API for ETL and it is the standard engine for parallelization, it is our go-to tool for merging and aggregating standard metrics which in turn help us understand liquidity, risk, and fraud. We’ll start with the merging of trades and quotes, then aggregate the trades dataset to show simple ways to slice the data. Lastly, we’ll show how to package this code up into classes for faster iterative development with Databricks Connect. The full code used for the metrics below is in the attached notebook.
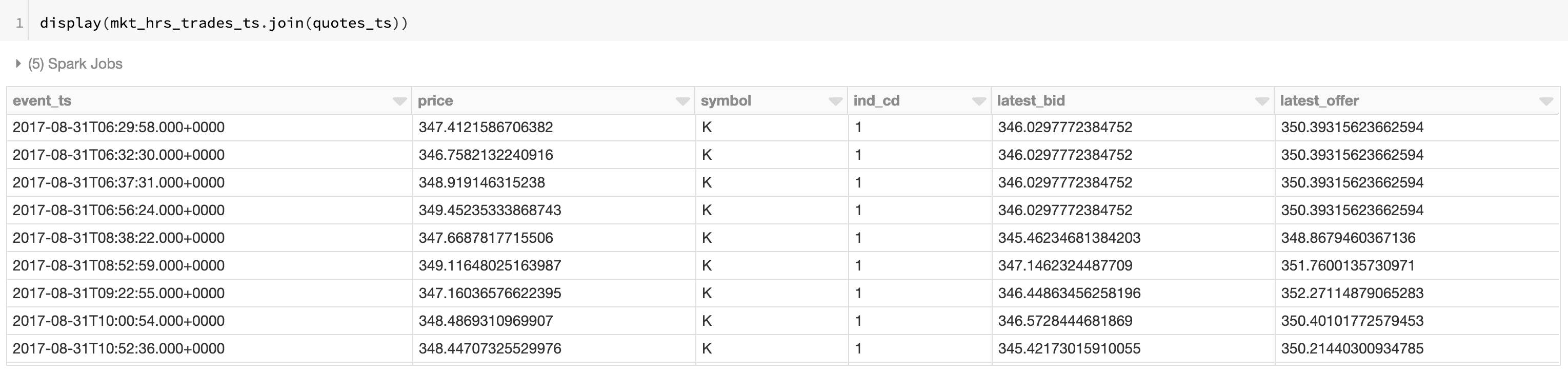
AS-OF Joins
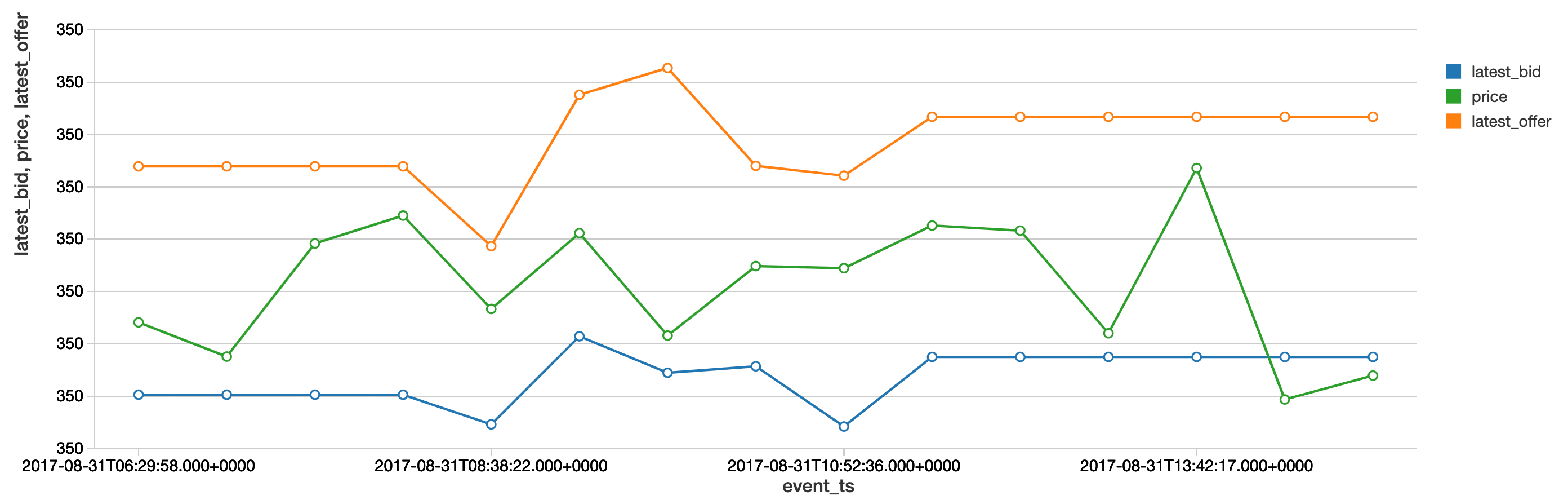
An as-of join is a commonly used ‘merge’ technique that returns the latest right value effective at the time of the left timestamp. For most time-series analyses, multiple types of time series are joined together on the symbol to understand the state of one time series (e.g. NBBO) at a particular time present in another time series (e.g. trades). The example below records the state of the NBBO for every trade for all symbols. As seen in the figure below, we have started off with an initial base time series (trades) and merged the NBBO dataset so that each timestamp has the latest bid and offer recorded ‘as of the time of the trade.’ Once we know the latest bid and offer, we can compute the difference (known as the spread) to understand at what points the liquidity may have been lower (indicated by a large spread). This kind of metric impacts how you may organize your trading strategy to boost your alpha.
First, let’s use the built-in windowing function last to find the last non-null quote value after ordering by time.
Now, we’ll call our custom join to merge our data and attach our quotes. See attached notebook for full code.
Marking VWAP Against Trade Patterns
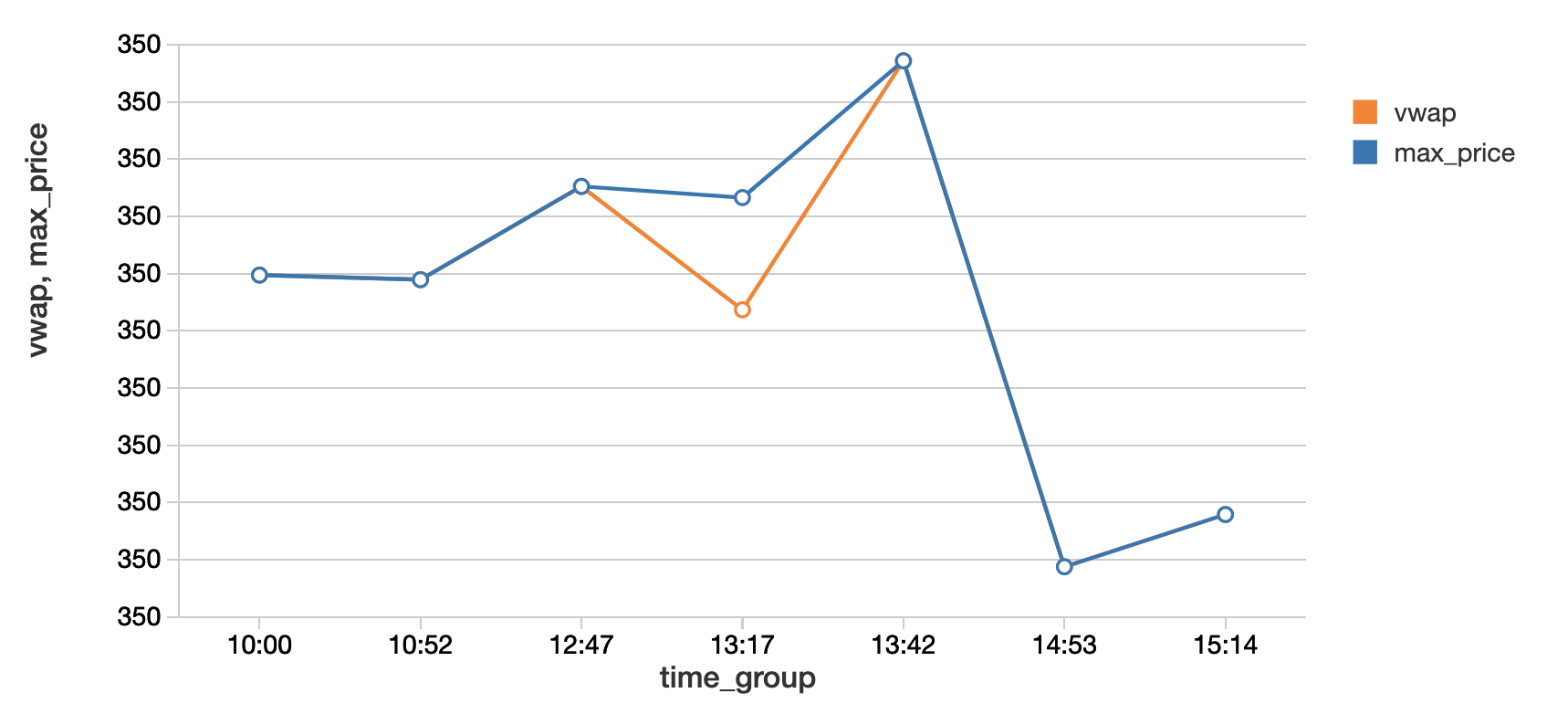
We’ve shown a merging technique above, so now let’s focus on a standard aggregation, namely Volume-Weighted Average Price (VWAP), which is the average price weighted by volume. This metric is an indicator of the trend and value of the security throughout the day. The vwap function within our wrapper class (in the attached notebook) shows where the VWAP falls above or below the trading price of the security. In particular, we can now identify the window during which the VWAP (in orange) falls below the trade price, showing that the stock is overbought.
Faster Iterative Development with Databricks Connect
Up to this point, we’ve created some basic wrappers for one-off time-series metrics. However, productionalization of code requires modularization and testing, and this is best accomplished in an IDE. This year, we introduced Databricks Connect, which gives the ability for local IDE development and enhances the experience with testing against a live Databricks cluster. The benefits of Databricks Connect for financial analyses include the ability to add time-series features on small test data with the added flexibility to execute interactive Spark queries against years of historical tick data to validate features.
We use PyCharm to organize classes needed for wrapping PySpark functionality for generating a rich time series feature set. This IDE gives us code completion, formatting standards, and an environment to quickly test classes and methods before running code.
https://www.youtube.com/watch?v=MkYAbqGDKA0
We can quickly debug classes then run Spark code directly from our laptop using a Jupyter notebook which loads our local classes and executes interactive queries with scalable infrastructure. The console pane shows our jobs being executed against a live cluster.
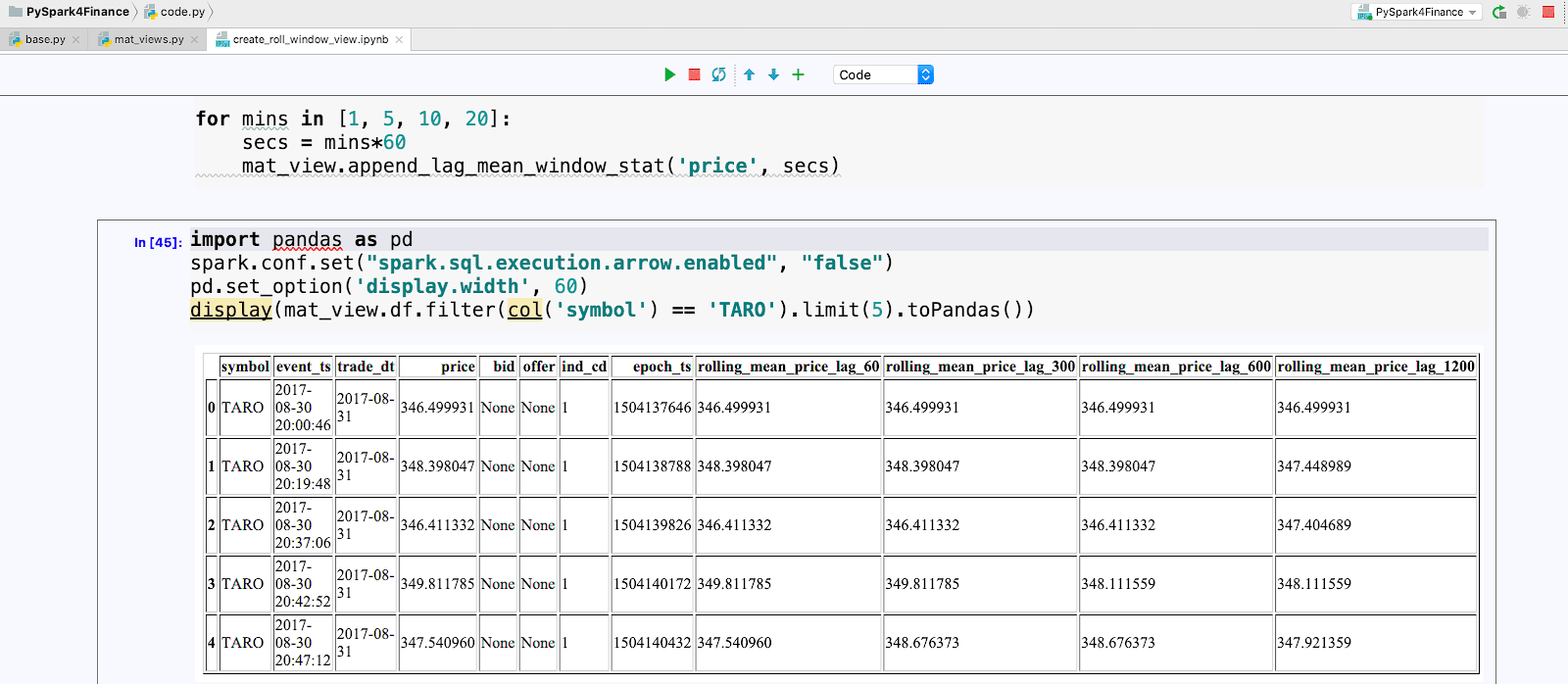
Lastly, we get the best of both worlds by using our local IDE and at the same time appending to our materialized time-series view on our largest time-series dataset.
Leveraging Koalas for Market Manipulation
The pandas API is the standard tool for data manipulation and analysis in Python and is deeply integrated into the Python data science ecosystem, e.g. NumPy, SciPy, matplotlib. One drawback of pandas is that it does not scale easily to large amounts of data. Financial data always includes years of historical data, which is critical for risk aggregation or compliance analysis. To make this easier, we introduced Koalas as a way to leverage pandas APIs while executing Spark on the backend. Since the Koalas API matches Pandas, we don’t sacrifice ease of use, and migration to scalable code is a one-line code change (see import of Koalas in the next section). Before we showcase Koalas’ fit for financial time series problems, let’s start with some context on a specific problem in financial fraud: front running.
Front running occurs when the following sequence occurs:
- A trading firm is aware of non-public information which may affect the price of a security
- The firm buys a large bulk order (or large set of orders totaling a large aggregate volume)
- Due to the removal of liquidity, the security price rises
- The firm sells the security to investors (which has been driven upward from the previous purchase) and makes a large profit, forcing investors to pay a larger price even though the information upon which the security was traded was non-public

Source: CC0 Public domain images: https://pxhere.com/en/photo/1531985, https://pxhere.com/en/photo/847099
For illustration purposes, a simple example using farmer’s markets and an apple pie business is found here. This example shows Freddy, a runner who is aware of the imminent demand for apples needed for apple pie businesses across the country and subsequently purchases apples at all farmer’s markets. This, in effect, allows Freddy to sell his apples at a premium to buyers since Freddy caused a major impact by purchasing before any other buyers (representing investors) had a chance to buy the product.
Detection of front running requires an understanding of order flow imbalances (see diagram below). In particular, anomalies in order flow imbalance will help identify windows during which front running may be occurring.
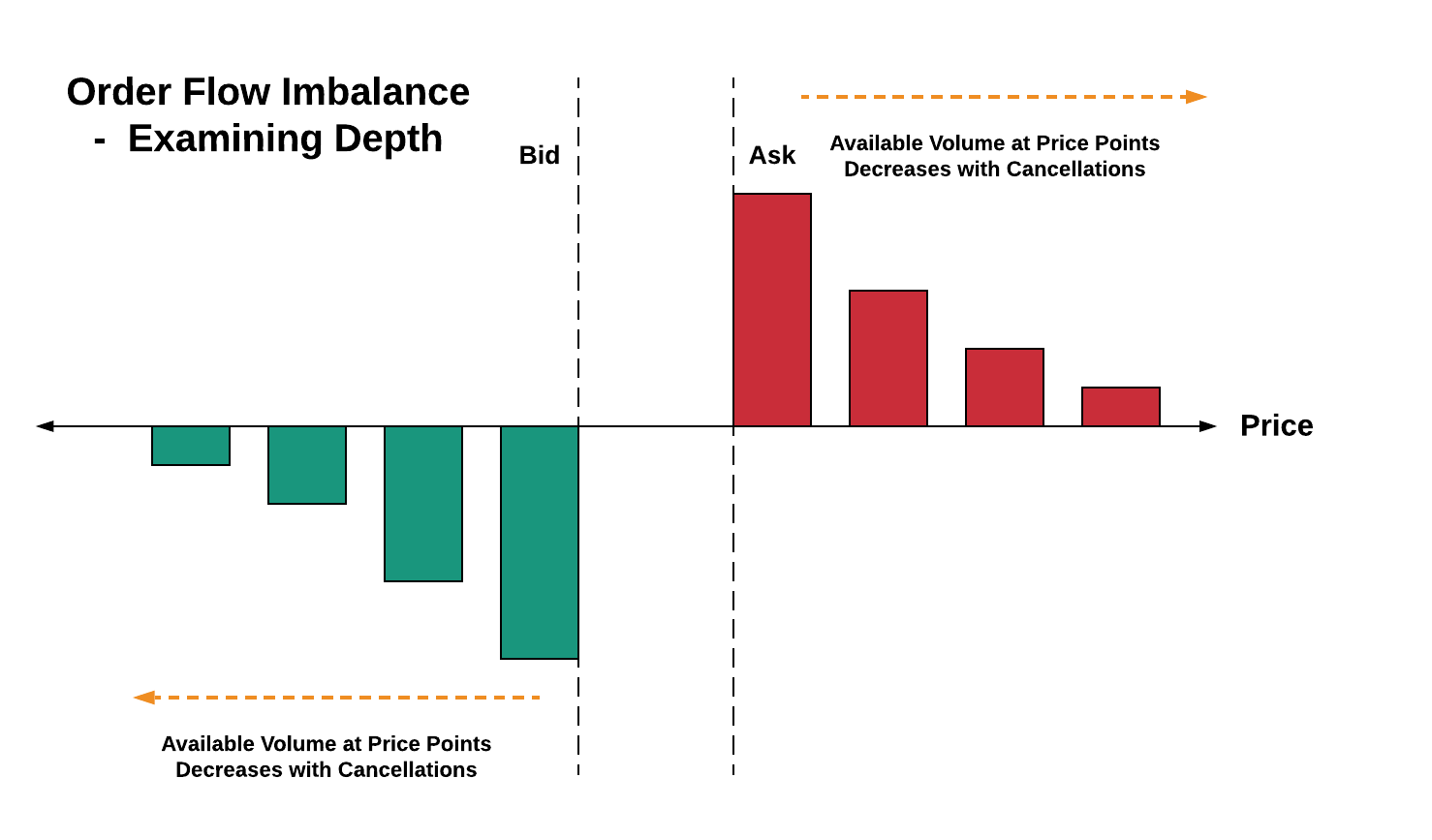
Let’s now use the koalas package to improve our productivity while solving the market manipulation problem. Namely, we’ll focus on the following to find order flow imbalance anomalies:
- De-duplication of events at the same time
- Lag windows for assessing supply/demand increases
- Merging of data frames to aggregate order flow imbalances
De-duplication of Time Series
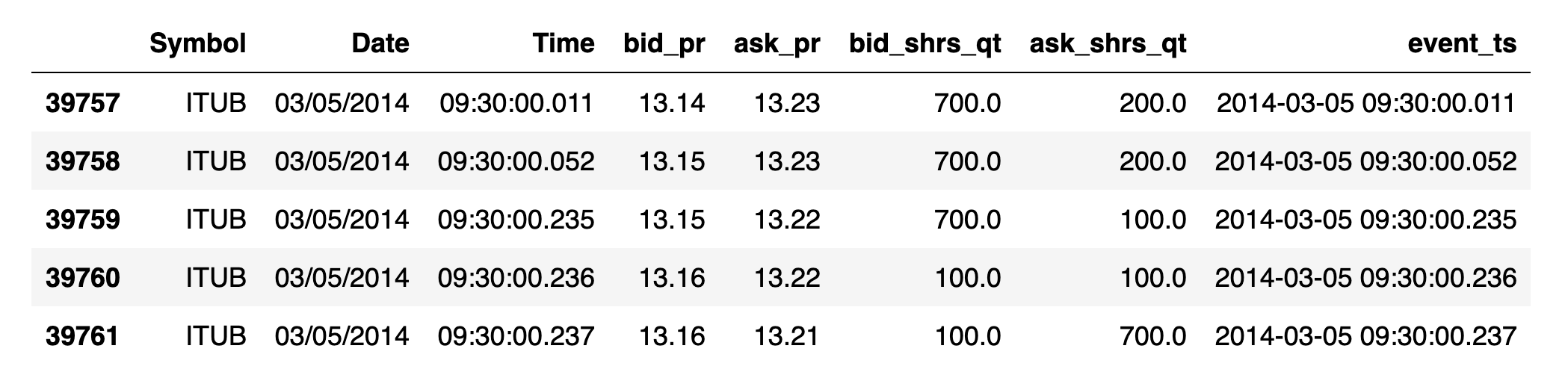
Common time series data cleansing involves imputation and de-duplication. You may find duplicate values in high-frequency data (such as quote data). When there are multiple values per time with no sequence number, we need to deduplicate so subsequent statistical analysis makes sense. In the case below, multiple bid/ask shares quantities are reported per time, so for computation of order imbalance, we want to rely on one value for maximum depth per time.
Time Series Windowing with Koalas
We’ve deduplicated our time series, so now we let’s look at windows so we can find supply and demand. Windowing for time series generally refers to looking at slices or intervals of time. Most trend calculations (simple moving average, for example) all use the concept of time windows to perform calculations. Koalas inherits the simple pandas interface for getting lag or lead values within a window using shift (analogous to Spark’s lag function), as demonstrated below.
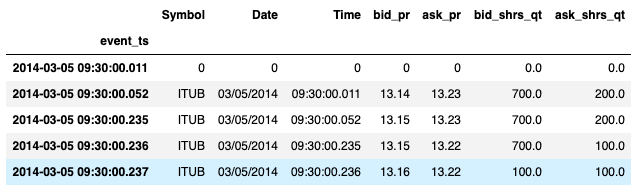
Merge on Timestamp and Compute Imbalance with Koalas Column Arithmetic
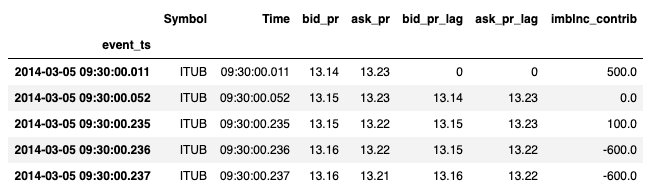
Now that we have lag values computed, we want to be able to merge this dataset with our original time series of quotes. Below, we employ the Koalas merge to accomplish this with our time index. This gives us the consolidated view we need for supply/demand computations which lead to our order imbalance metric.
Koalas to NumPy for Fitting Distributions
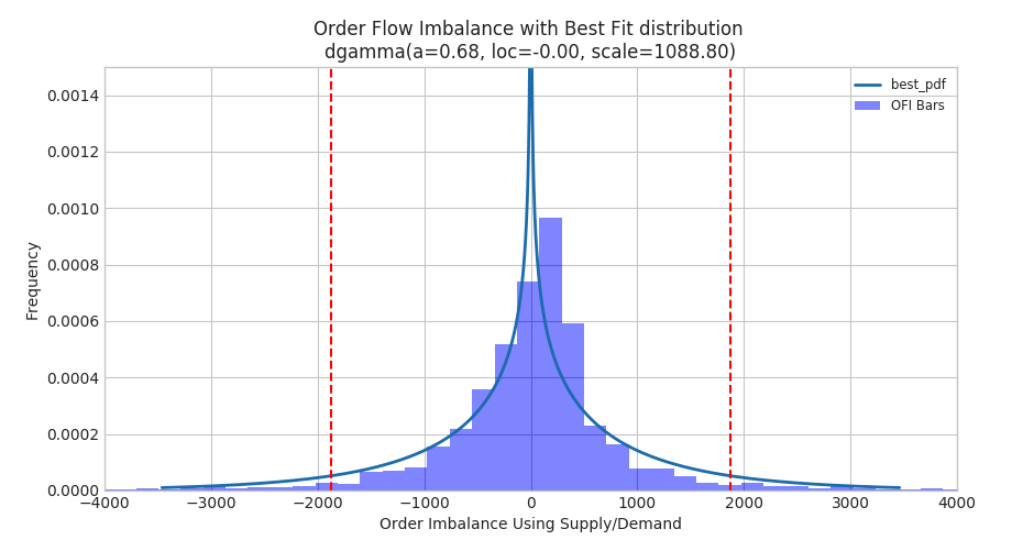
After our initial prep, it’s time to convert our Koalas data frame to a format useful for statistical analysis. For this problem, we might aggregate our imbalances down to the minute or other unit of time before proceeding, but for purposes of illustration, we’ll run against the full dataset for our ticker ‘ITUB’. Below, we convert our Koalas structure to a NumPy dataset so we can use the SciPy library for detecting anomalies in order flow imbalance. Simply use the to_numpy() syntax to bridge this analysis.
Below, we plotted the distribution of our order flow imbalances along with markers for the 5th and 95th percentiles to identify the events during which imbalance anomalies occurred. See the full notebook for the code to fit distributions and create this plot. The time during imbalances we just computed with our koalas/SciPy workflow will correlate with potential instances of front running, the market manipulation scheme we were searching for.
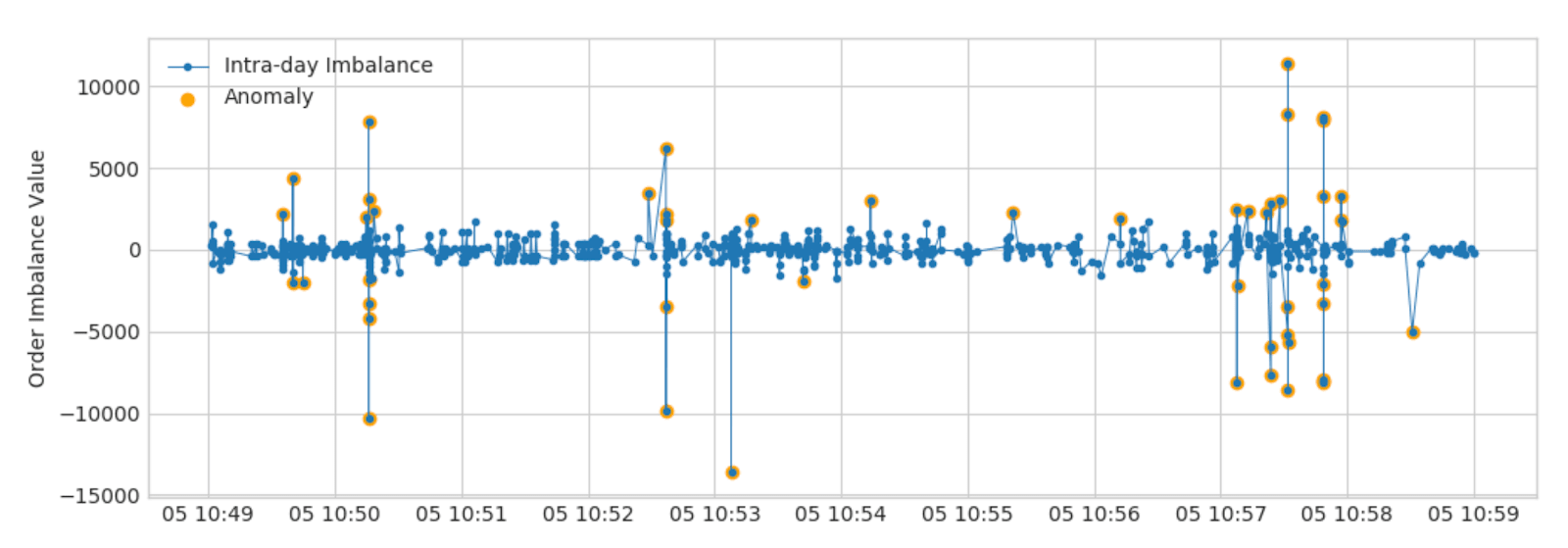
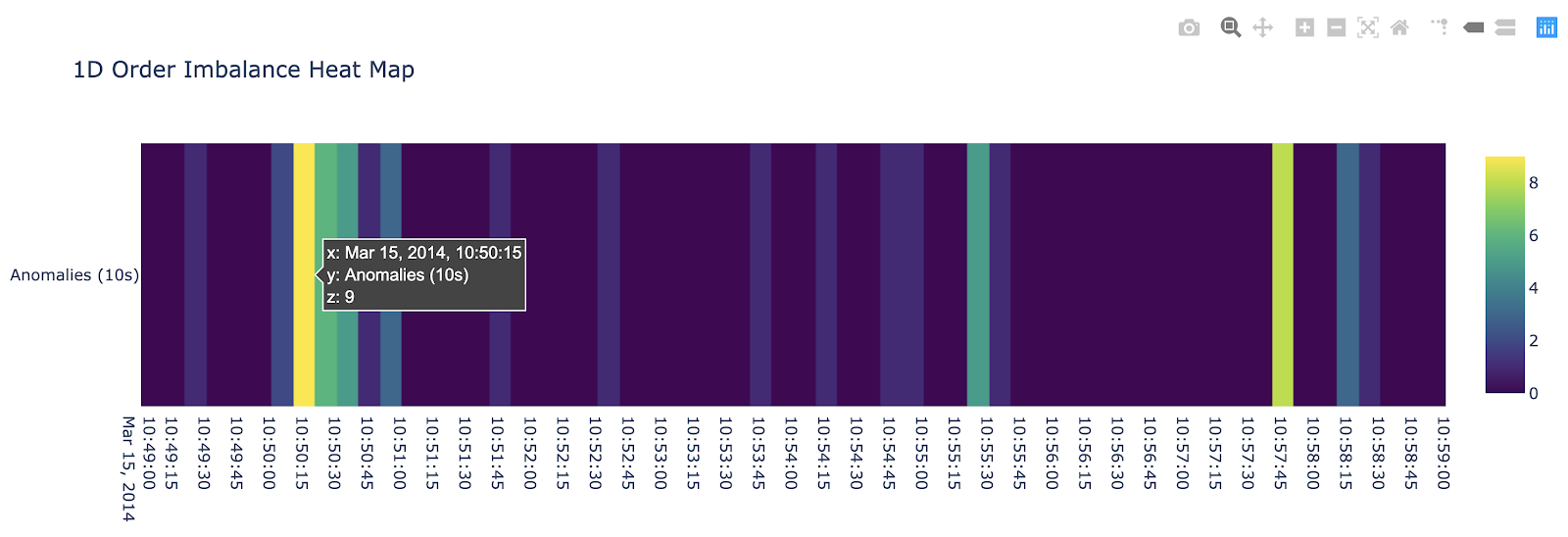
The time series visualization below pinpoints the anomalies retrieved as outliers above, highlighted in orange. In our final visualization, we use the plotly library to summarize time windows and frequency of anomalies in the form of a heat map. Specifically, we identify the 10:50:10 - 10:50:20 timeframe as a potential problem area from the front running perspective.
Conclusion
In this article, we’ve shown how Apache Spark and Databricks can be leveraged for time series analysis both directly, by using windowing and wrappers, and indirectly, by using Koalas. Most data scientists rely on the pandas API, so Koalas helps them use pandas functionality while allowing the scale of Apache Spark. The advantages of using Spark and Koalas for time series analyses include:
- Parallelize analyses of your time series for risk, fraud, or compliance use cases with as-of joins and simple aggregations
- Iterate faster and create rich time series features with Databricks Connect
- Arm your data science and quant teams with Koalas to scale out data preparation while not sacrificing pandas ease of use and APIs
Try this notebook on Databricks today! Contact us to learn more about how we assist customers with financial time series use cases.

