Introducing the MLflow Model Registry
Watch the announcement and demo
At today’s Spark + AI Summit in Amsterdam, we announced the availability of the MLflow Model Registry, a new component in the MLflow open source ML platform. Since we introduced MLflow at Spark+AI Summit 2018, the project has gained more than 140 contributors and 800,000 monthly downloads on PyPI, making MLflow one of the fastest growing open source projects in machine learning!
MLflow already has the ability to track metrics, parameters, and artifacts as part of experiments, package models and reproducible ML projects, and deploy models to batch or real-time serving platforms.
The MLflow Model Registry builds on MLflow’s existing capabilities to provide organizations with one central place to share ML models, collaborate on moving them from experimentation to testing and production, and implement approval and governance workflows. Since we started MLflow, model management was the top requested feature among our open source users, so we are excited to launch a model management system that integrates directly with MLflow.
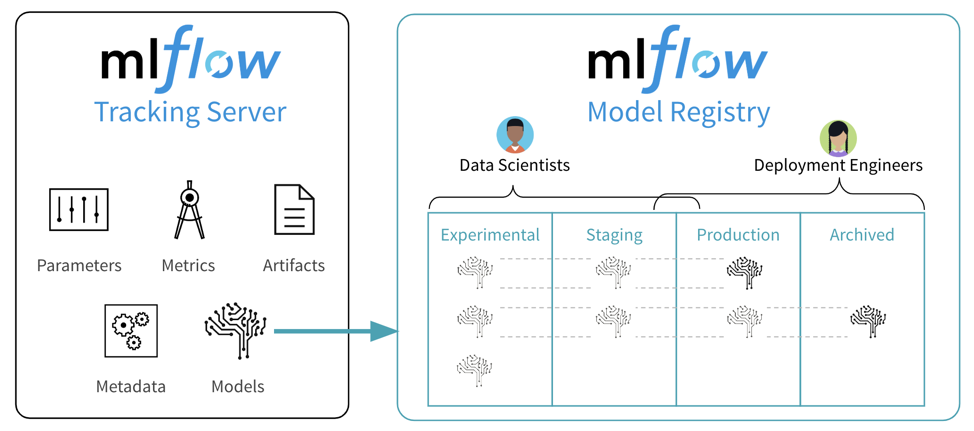
The Model Registry gives MLflow new tools to share, review and manage ML models throughout their lifecycle
Applying Good Engineering Principles to Machine Learning with MLflow Model Registry
Many Data Science and Machine Learning projects fail due to preventable issues that have been discovered and solved in software engineering more than a decade ago. However, those solutions need to be adapted due to key differences between developing code and training ML models.
- Expertise, Code, AND Data: With the addition of data, Data Science and ML code not only needs to deal with data dependencies, but also handle the inherent non-deterministic characteristics of statistical modeling. ML models are not guaranteed to behave the same way when trained twice, unlike traditional code that can be easily unit tested.
- Model Artifacts: In addition to application code, ML products and features also depend on models that are the result of a training process. Those model artifacts can often be large (on the order of gigabytes) and often need to be served differently from code itself.
- Collaboration: In large organizations, models that are deployed in an application are often not trained by the same people responsible for the deployment. Handoffs between experimentation, testing, and production deployments are similar, but not identical to approval processes in software engineering.
The MLflow Model Registry addresses the aforementioned challenges. Below are some of the key features of this new component.
One hub for managing ML models collaboratively
Building and deploying ML models is a team sport. Not only are the responsibilities along the machine learning model lifecycle often split across multiple people (e.g. data scientists train models whereas production engineers deploy them), but also, at each lifecycle stage, teams can benefit from collaboration and sharing (e.g. a fraud model built in one part of the organization could be re-used in others).
The new Model Registry facilitates sharing of expertise and knowledge across teams by making ML models more discoverable and providing collaborative features to jointly improve on common ML tasks. Simply register an MLflow model from your experiments to get started. The registry will then let you track multiple versions of the model and mark each one with a lifecycle stage: development, staging, production or archived.
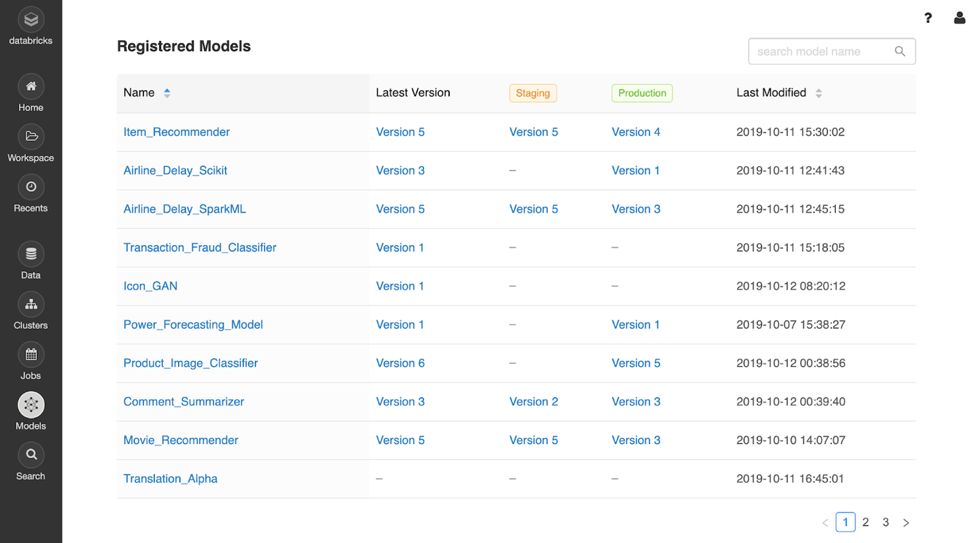
Sample machine learning models displayed via the MLflow Model Registry dashboard
Flexible CI/CD pipelines to manage stage transitions
The MLflow Model Registry lets you manage your models’ lifecycle either manually or through automated tools. Analogous to the approval process in software engineering, users can manually request to move a model to a new lifecycle stage (e.g., from Staging to Production), and review or comment on other users’ transition requests. Alternatively, you can use the Model Registry’s API to plug in continuous integration and deployment (CI/CD) tools such as Jenkins to automatically test and transition your models. Each model also links to the experiment run that built it in MLflow Tracking to let you easily review models.
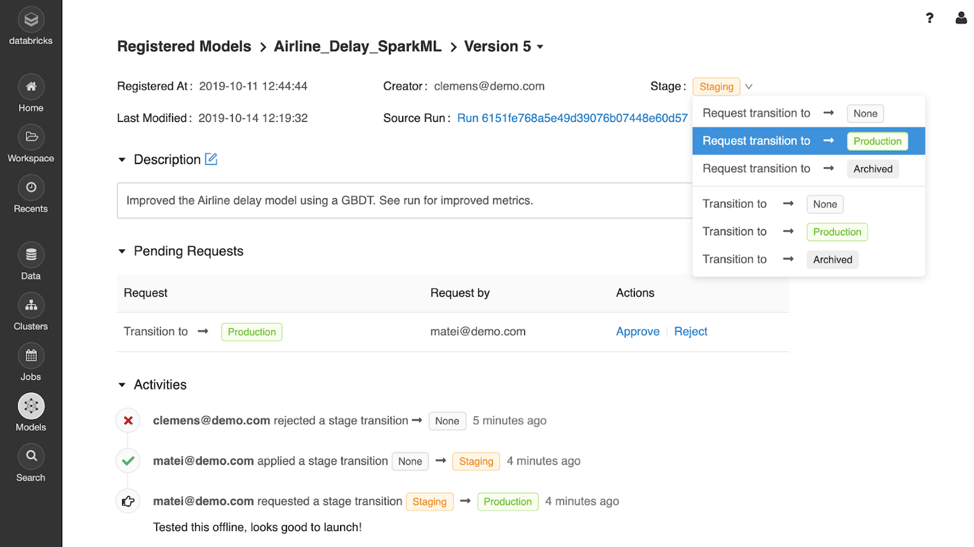
Example machine learning model page view in MLflow, showing how users can request and review changes to a model’s stage
Visibility and governance for the ML lifecycle
In large enterprises, the number of ML models that are in development, staging, and production at any given point in time may be in the 100s or 1,000s. Having full visibility into which models exist, what stages they are in, and who has collaborated on and changed the deployment stages of a model allows organizations to better manage their ML efforts.
The MLflow Model Registry provides full visibility and enables governance by keeping track of each model’s history and managing who can approve changes to the model’s stages.
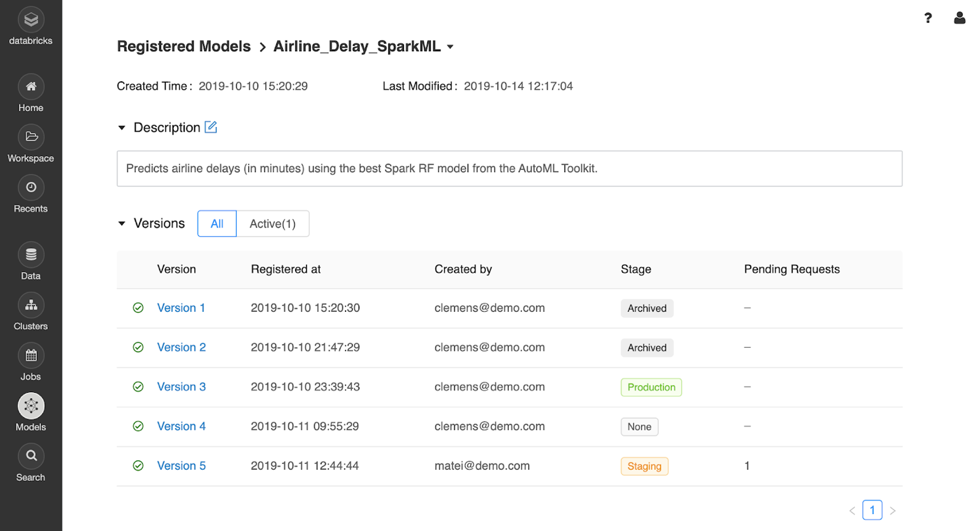
Identify model versions, stages, and authors of each model version
Get Started with the MLflow Model Registry
We’ve been developing the MLflow Model Registry with feedback from Databricks customers over the past few quarters, and today, we’ve posted the first open source patch for the MLflow Model Registry on GitHub. We would love to hear your feedback! We plan to continue developing the registry over the next few months and included it in the next MLflow release. Databricks customers can also sign up here to get started with the Model Registry.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.