Blog
Featured Story![DBSQL performance OG]()

Product
December 17, 2025/6 min read
SQL on the Databricks Lakehouse in 2025
What's new![data modeling graphic]()
![Databricks Free Edition Hackathon]()
Product
December 15, 2025/12 min read
Databricks Lakehouse Data Modeling: Myths, Truths, and Best Practices

Platform
December 16, 2025/3 min read
Announcing the winners of the inaugural Databricks Free Edition Hackathon
Recent posts

Announcements
December 19, 2025/2 min read
Welcoming Stately Cloud to Databricks: Investing in the Foundation for Scalable AI Applications

Product
December 18, 2025/6 min read
Top 10 Questions You Asked About Databricks Clean Rooms, Answered
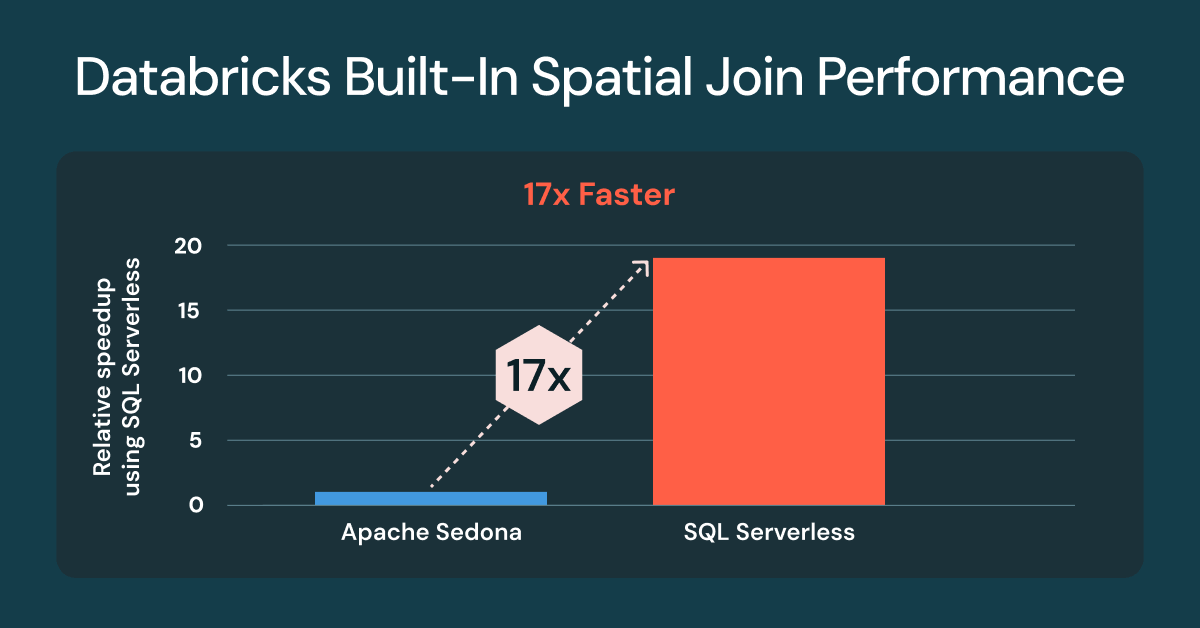

Platform
December 16, 2025/3 min read
Announcing the winners of the inaugural Databricks Free Edition Hackathon
Product
December 15, 2025/12 min read
Databricks Lakehouse Data Modeling: Myths, Truths, and Best Practices

Product
December 11, 2025/5 min read
OpenAI GPT-5.2 and Responses API on Databricks: Build Trusted, Data-Aware Agentic Systems

Partners
December 9, 2025/20 min read
Introducing Databricks GenAI Partner Accelerators for Data Engineering & Migration

Mosaic Research
December 9, 2025/12 min read
Introducing OfficeQA: A Benchmark for End-to-End Grounded Reasoning

Solutions
December 8, 2025/6 min read
Powering Growth: How Data and AI Are Rewiring Productivity in Banking and Payments

Technology
December 5, 2025/14 min read
Expensive Delta Lake S3 Storage Mistakes (And How to Fix Them)


Energy
December 4, 2025/4 min read
BP’s Geospatial AI Engine: Transforming Safety and Operations with Databricks

Data Leader
December 4, 2025/2 min read
Building the AI-Ready Enterprise: Leaders Share Real-World AI Solutions and Practices



Announcements
December 2, 2025/6 min read
Completing the Lakehouse Vision: Open Storage, Open Access, Unified Governance
Data Intelligence for All

Never miss a Databricks post
Subscribe to our blog and get the latest posts delivered to your inbox