Deploy Production Pipelines Even Easier With Python Wheel Tasks
With its rich open source ecosystem and approachable syntax, Python has become the main programming language for data engineering and machine learning. Data and ML engineers already use Databricks to orchestrate pipelines using Python notebooks and scripts. Today, we are proud to announce that Databricks can now run Python wheels, making it easy to develop, package and deploy more complex Python data and ML pipeline code.
Python wheel tasks can be executed on both interactive clusters and on job clusters as part of jobs with multiple tasks. All the output is captured and logged as part of the task execution so that it is easy to understand what happened without having to go into cluster logs.
The wheel package format allows Python developers to package a project’s components so they can be easily and reliably installed in another system. Just like the JAR format in the JVM world, a wheel is a compressed, single-file build artifact, typically the output of a CI/CD system. Similar to a JAR, a wheel contains not only your source code but references to all of its dependencies as well.
To run a Job with a wheel, first build the Python wheel locally or in a CI/CD pipeline, then upload it to cloud storage. Specify the path of the wheel in the task and choose the method that needs to be executed as the entrypoint. Task parameters are passed to your main method via *args or **kwargs.
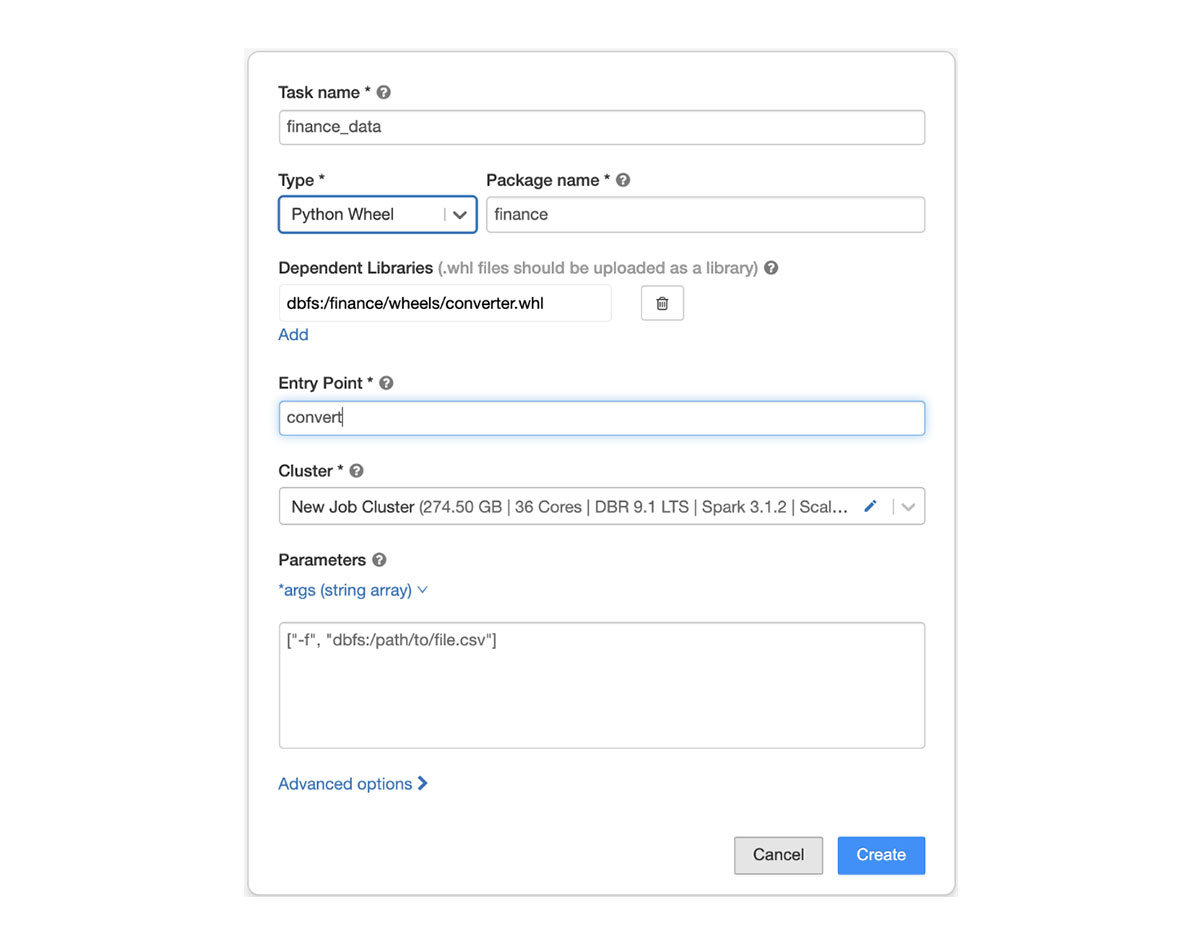
Python Wheel tasks in Databricks Jobs are now Generally Available. We would love for you to try out this capability and tell us how we can better support Python data engineers.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.