Get to Know Your Queries With the New Databricks SQL Query Profile!
by Bilal Aslam and Lucas Cerdan
Databricks SQL provides data warehousing capabilities and first class support for SQL on the Databricks Lakehouse Platform - allowing analysts to discover and share new insights faster at a fraction of the cost of legacy cloud data warehouses.
This blog is part of a series on Databricks SQL that covers critical capabilities across performance, ease of use, and governance. In a previous blog post, we covered recent user experience enhancements. In this article, we’ll cover improvements that help our users understand queries and query performance.
Speed up queries by identifying execution bottlenecks
Databricks SQL is great at automatically speeding up queries - in fact, we recently set a world record for it! Even with today’s advancements, there are still times when you need to open up the hood and look at query execution (e.g. when a query is unexpectedly slow). That’s why we’re excited to introduce Query Profile, a new feature that provides execution details for a query and granular metrics to see where time and compute resources are being spent. The UI should be familiar to administrators who have used databases before.
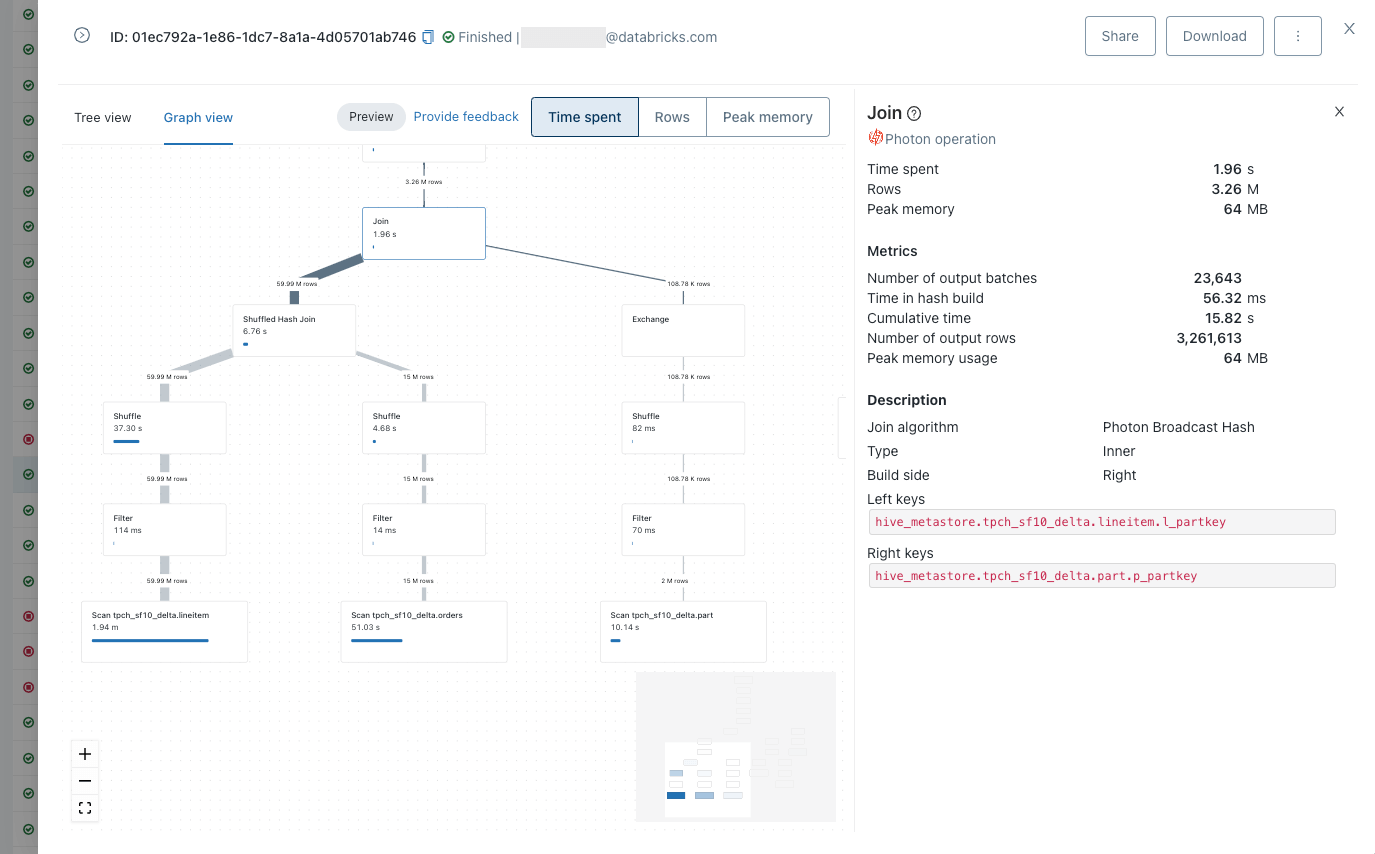
Query Profile includes these key capabilities:
- A breakdown of the main components of query execution and related metrics: time spent in tasks, rows processed, and memory consumption.
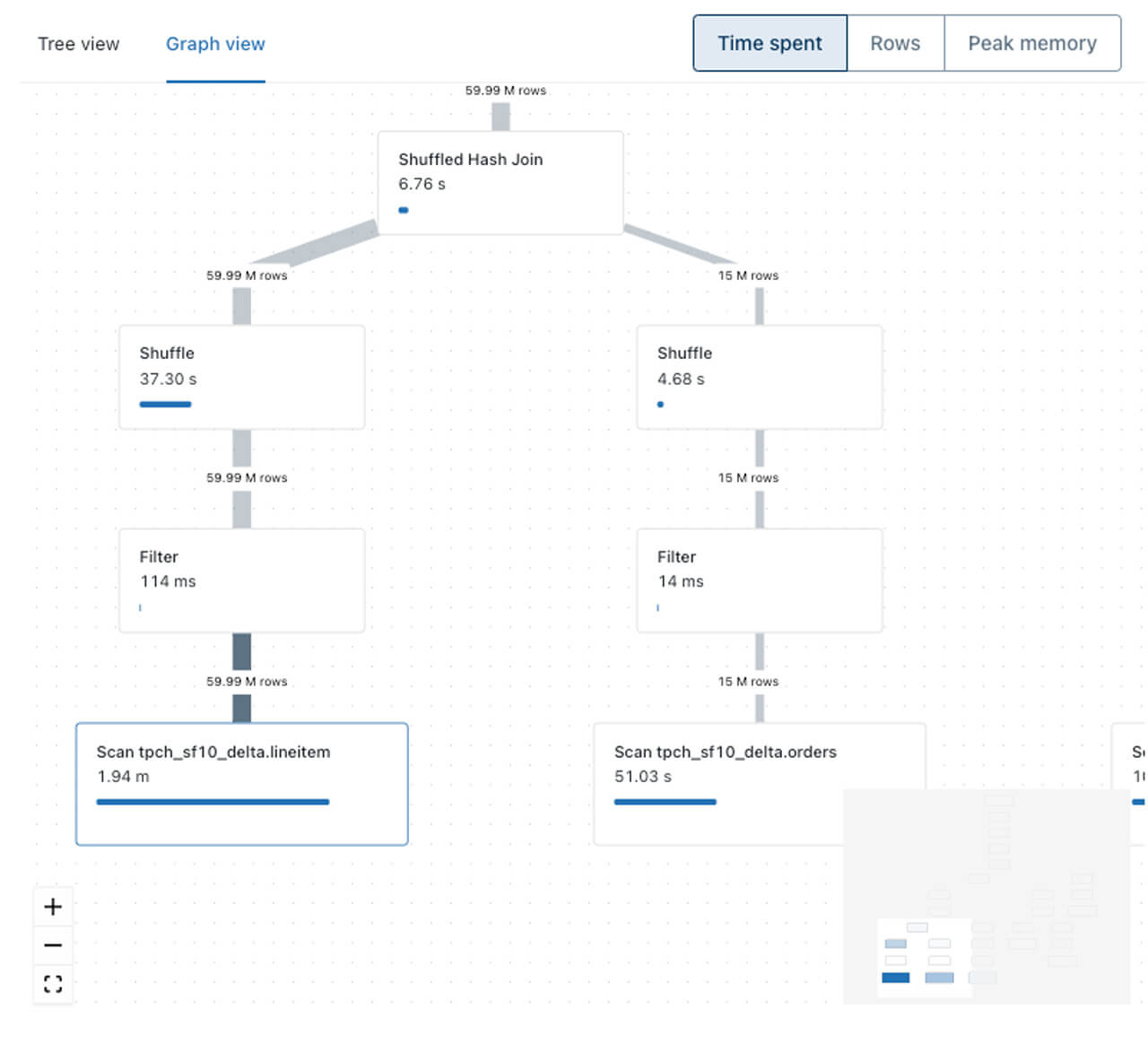
- Multiple graphical representations. This includes a condensed tree view for spotting the slowest operations at a glance and a graph view to understand how data is flowing between query operators.
- The ability to easily discover common mistakes in queries (e.g. exploding joins or full table scans).
- Better collaboration via the ability to download and share a query profile.
A common methodology for speeding up queries is to first identify the longest running query operators. We are more interested in total time spent on a task rather than the exact “wall clock time” of an operator as we’re dealing with a distributed system and operators can be executed in parallel.
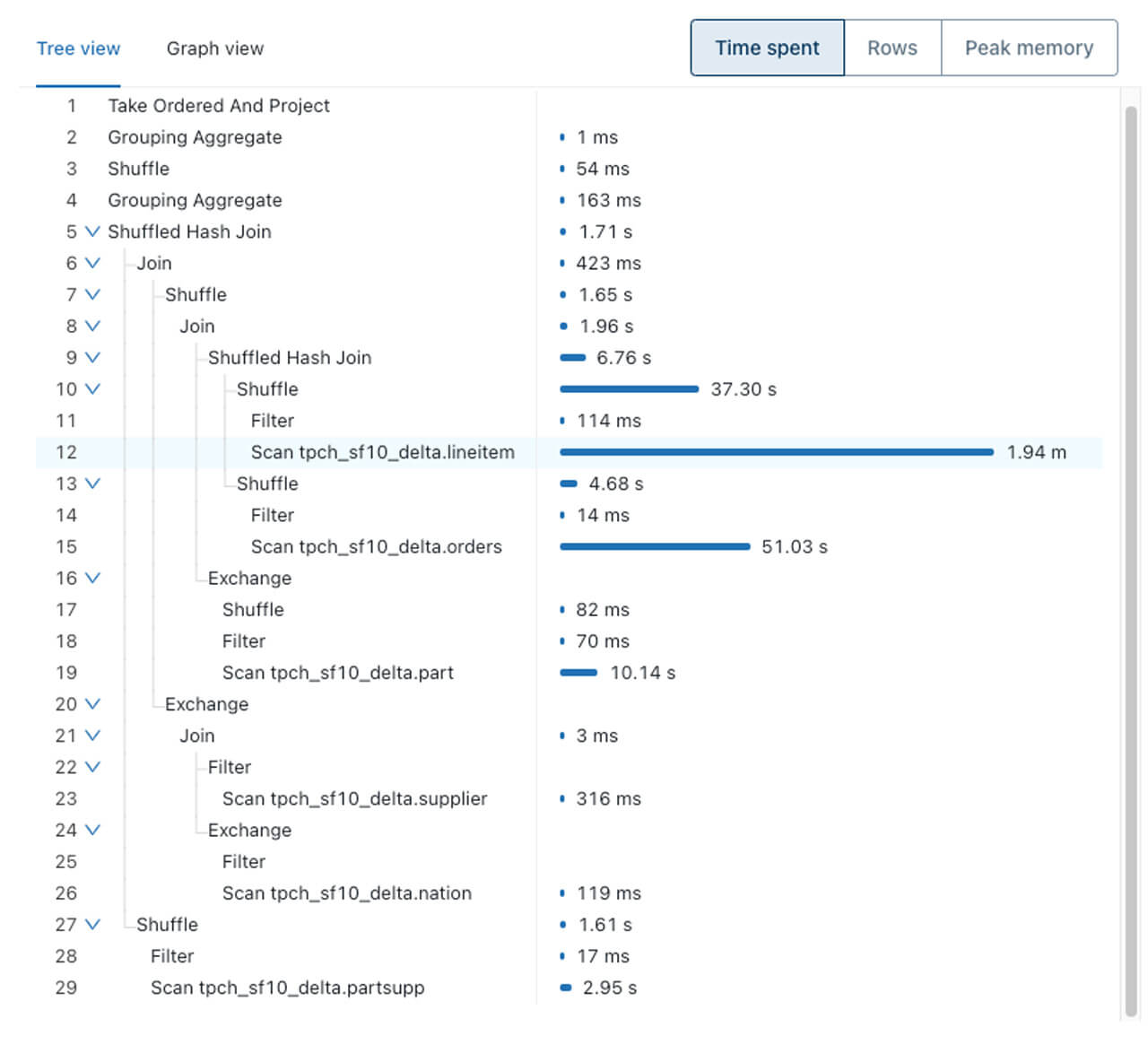
From the Query Profile above of a TPC-H query, it’s easy to identify the most expensive query operator: scan of the table lineitem. The second most expensive operator is the scan of another table (orders).
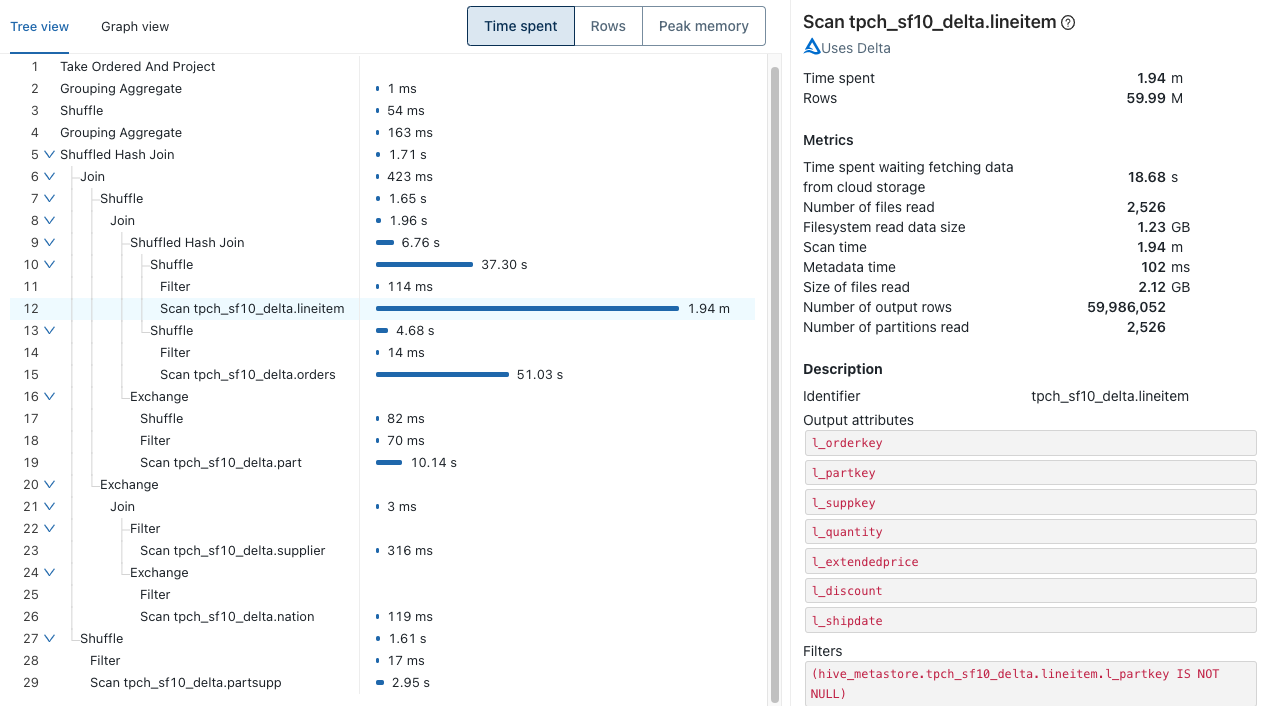
Each query operator comes with a slew of statistics. In the case of a scan operator, metrics include number of files or data read, time spent waiting for cloud storage or time spent reading files. As a result, it is easy to answer questions such as which table should be optimized or whether a join could be improved.
Spring cleaning Query History
We are also happy to announce a few small but handy tweaks in Query History. We have enhanced the details that can be accessed for each query. You can now see a query’s status, SQL statement, duration breakdown and a summary of the most important execution metrics.
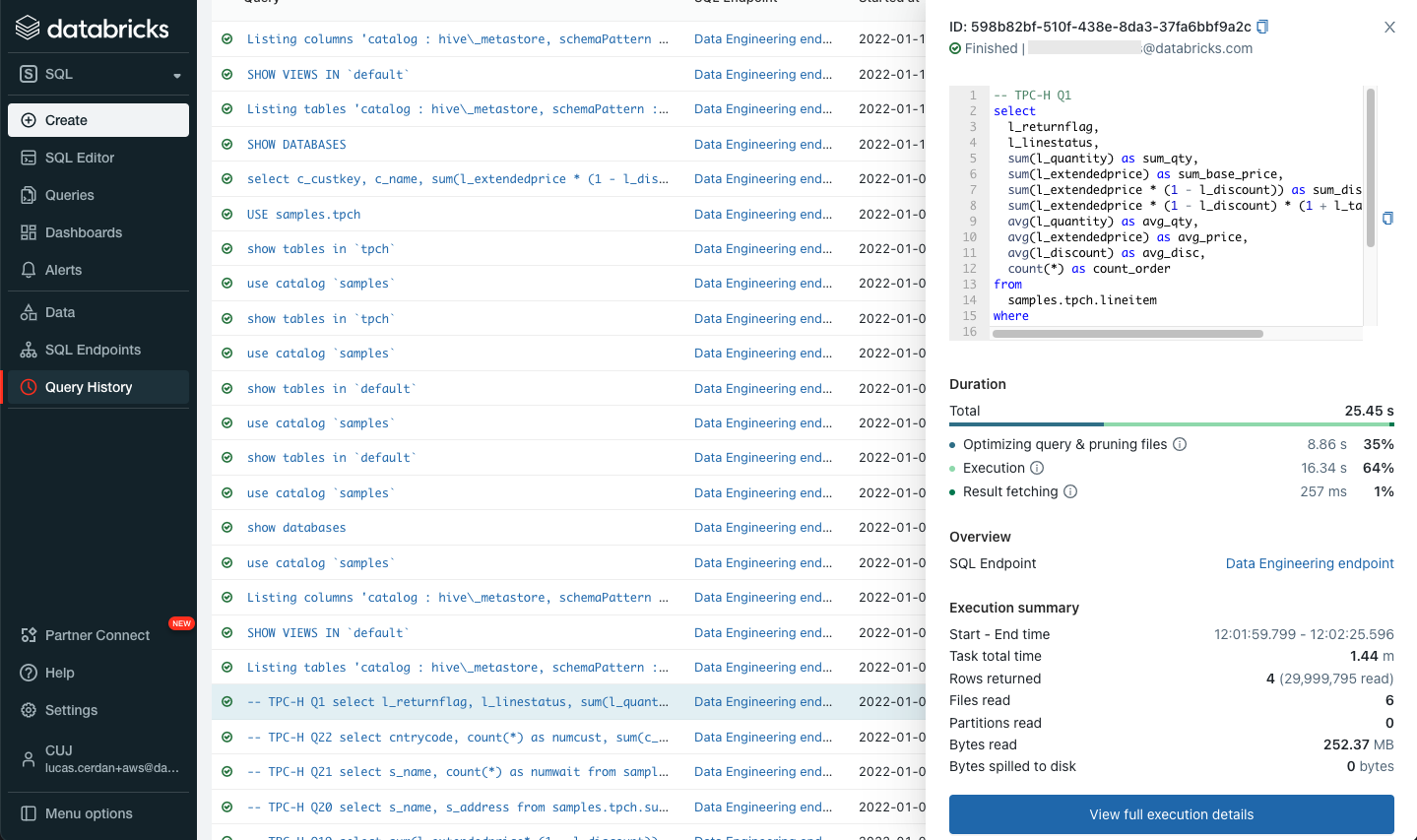
To avoid back and forth between the SQL editor and Query History, all the features announced above are also directly available from the SQL editor.
Query performance best practices
Query Profile is available today in Databricks SQL. Get started now with Databricks SQL by signing up for a free trial. To learn how to maximize lakehouse performance on Databricks SQL, join us for a webinar on February 24th. This webinar includes demos, live Q&As and lessons learned in the field so you can dive in and find out how to harness all the power of the Lakehouse Platform.
In this webinar, you’ll learn how to:
- Quickly and easily ingest business-critical data into your lakehouse and continuously refine data with optimized Delta tables for best performance
- Write, share and reuse queries with a native first-class SQL development experience on Databricks SQL — and unlock maximum productivity
- Get full transparency and visibility into query execution with an in-depth breakdown of operation-level details so you can dive in
Register here!
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.