Blog



Recent posts





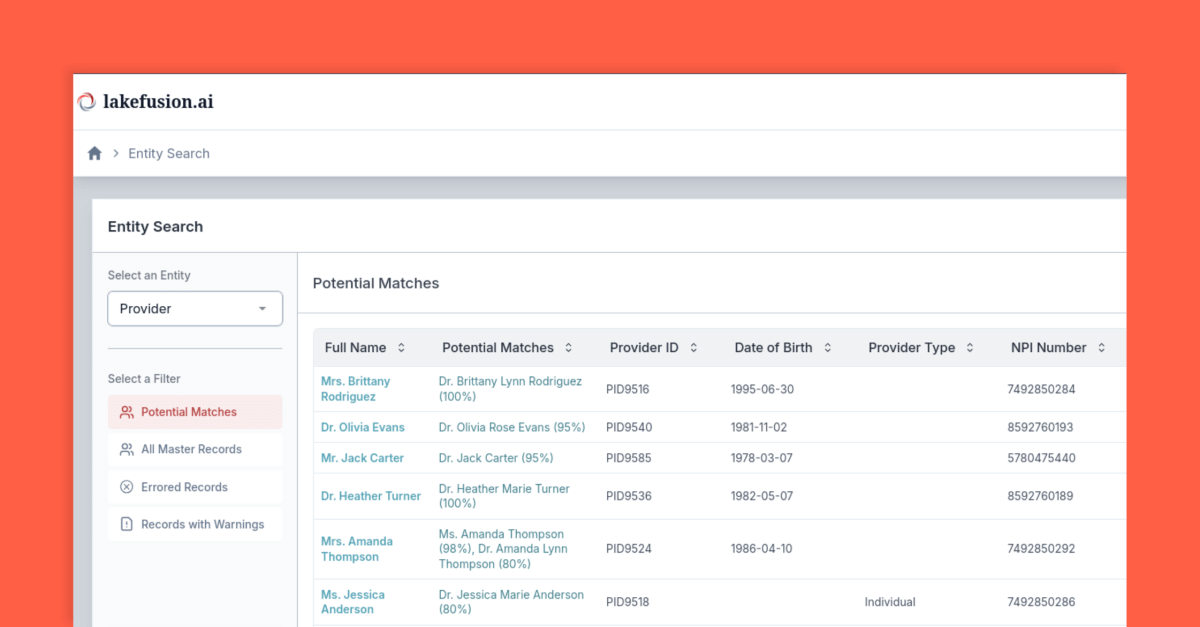







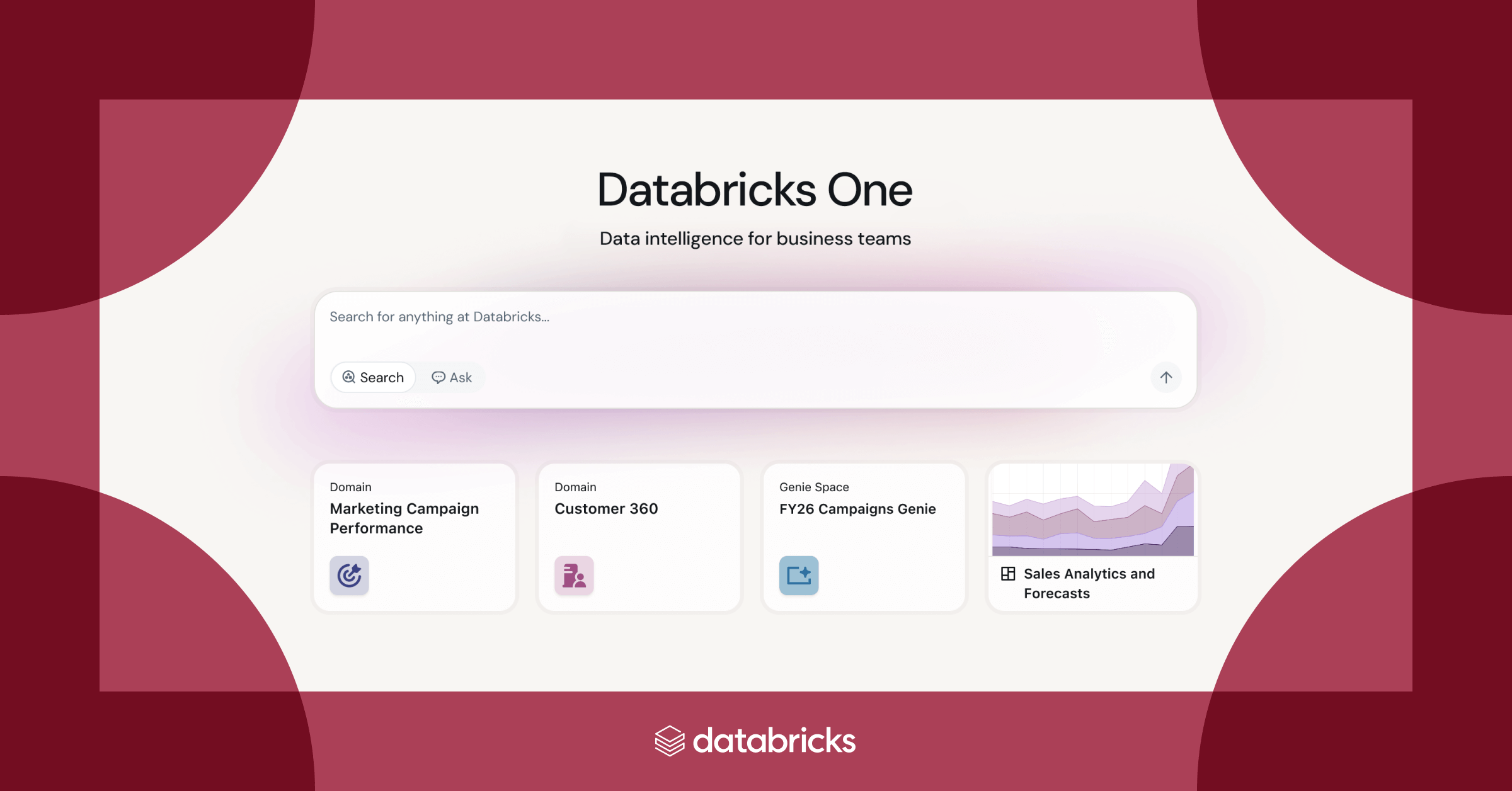




JUNE 9–12 / SAN FRANCISCO
Built by data and AI pros for pros

Never miss a Databricks post
Subscribe to the categories you care about and get the latest posts delivered to your inbox
Subscribe to the categories you care about and get the latest posts delivered to your inbox