Blog
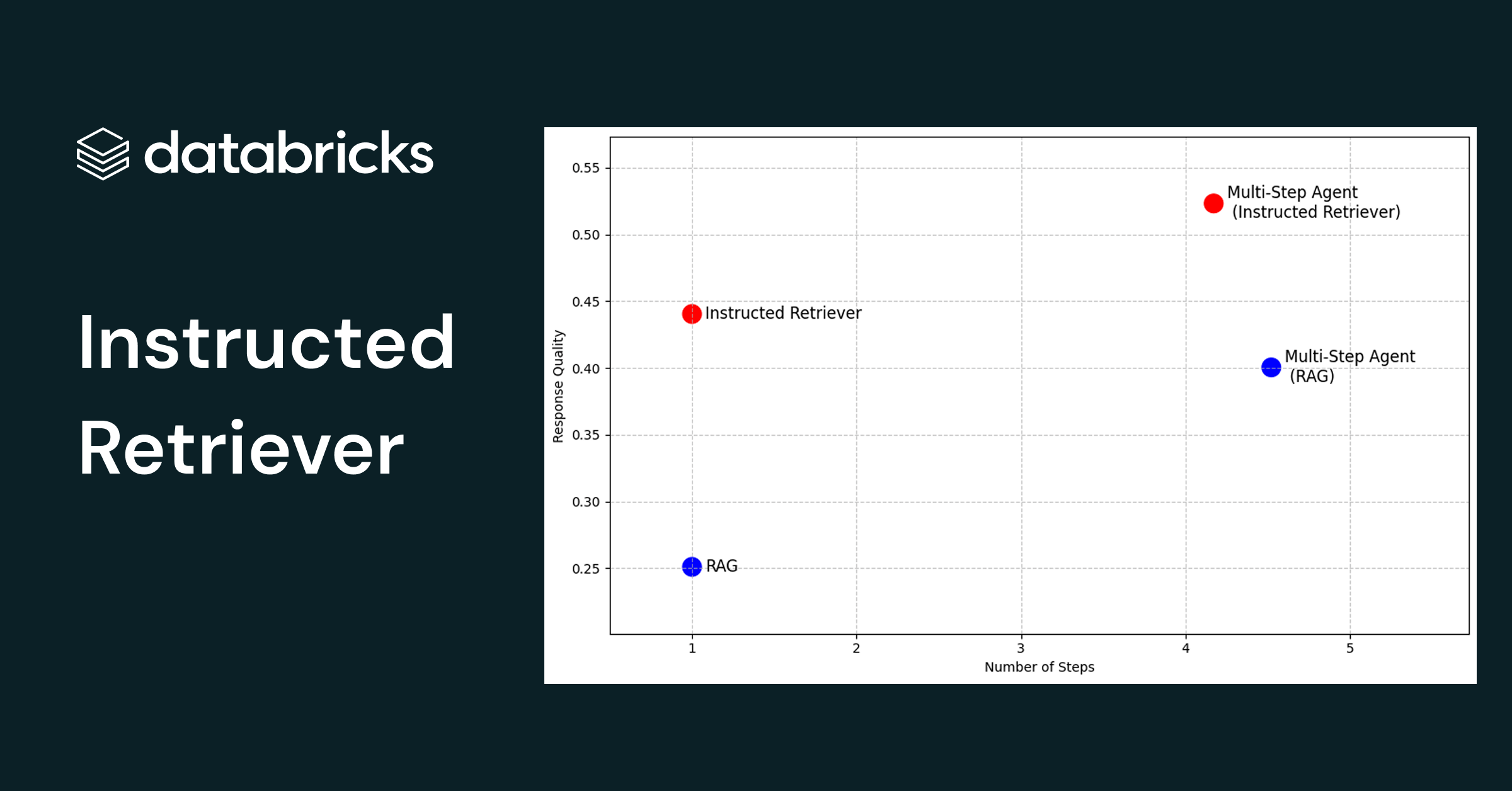
Featured Story![Instructed Retriever]()
Mosaic Research
January 6, 2026/NaN min read
Instructed Retriever: Unlocking System-Level Reasoning in Search Agents
What's new![2026 on red background with silhouette]()
![Marketing campaign data visualization dashboard]()

Data Leader
December 29, 2025/3 min read
The Top Strategic Priorities Guiding Data and AI Leaders in 2026
Solutions
December 30, 2025/4 min read
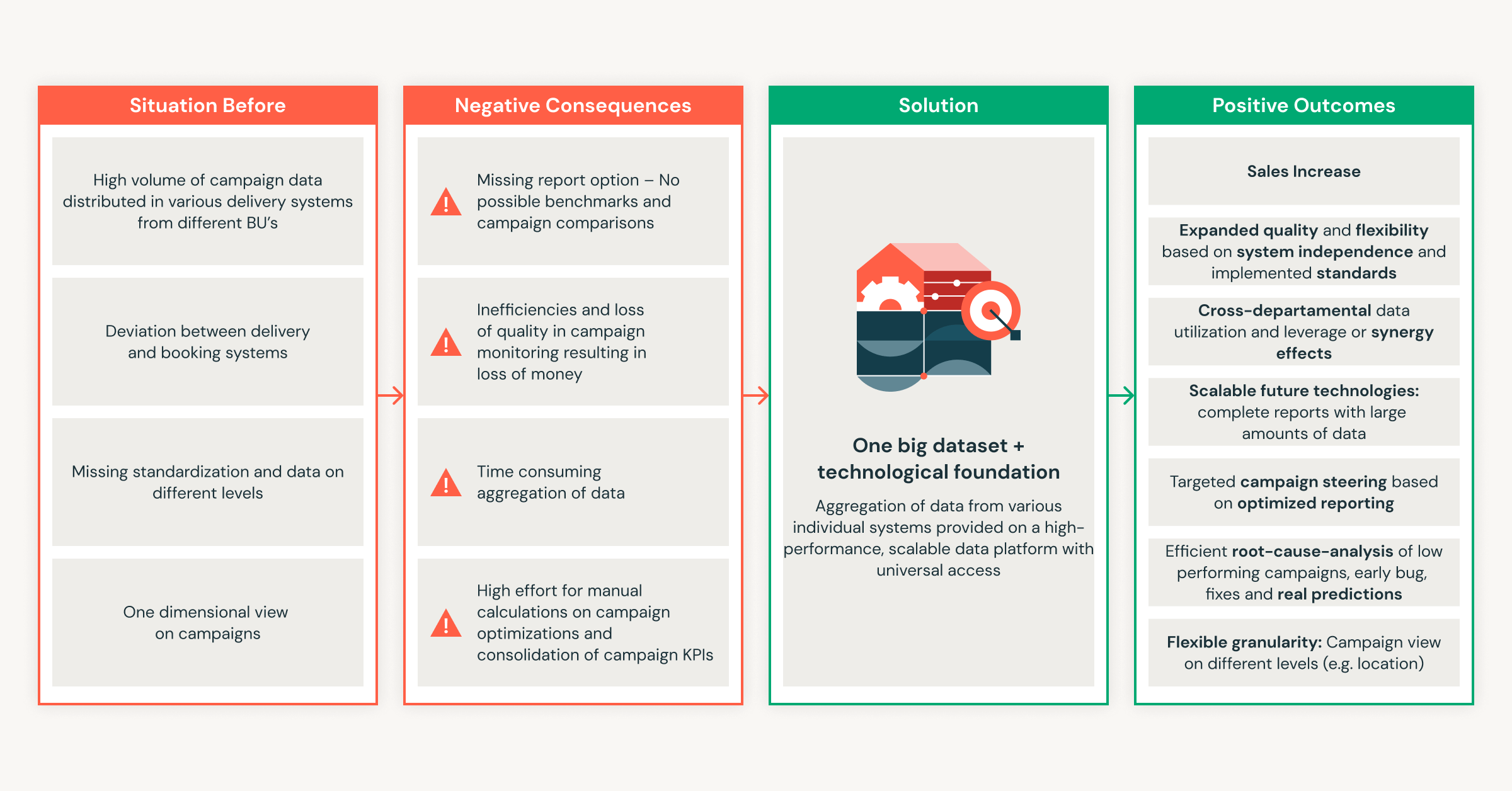
From Zero to Millions in Savings: Ströer Transforms Advertising Success with Databricks
Recent posts




Technology
January 9, 2026/4 min read
Thumbtack Powering Safe, Smart Home Services on Databricks with GenAI

Insights
January 9, 2026/4 min read
How 7‑Eleven Transformed Maintenance Technician Knowledge Access with Databricks Agent Bricks

Energy
January 8, 2026/7 min read
Securing the Grid: A Practical Guide to Cyber Analytics for Energy & Utilities

Engineering
January 7, 2026/6 min read
From Chaos to Scale: Templatizing Spark Declarative Pipelines with DLT-META
Mosaic Research
January 6, 2026/11 min read
Instructed Retriever: Unlocking System-Level Reasoning in Search Agents

Solutions
January 5, 2026/8 min read
BCBS 239 Compliance in the Age of AI: Turning Regulatory Burden into Strategic Advantage
Solutions
December 30, 2025/4 min read
From Zero to Millions in Savings: Ströer Transforms Advertising Success with Databricks
Data Leader
December 29, 2025/3 min read
The Top Strategic Priorities Guiding Data and AI Leaders in 2026


Announcements
December 19, 2025/2 min read
Welcoming Stately Cloud to Databricks: Investing in the Foundation for Scalable AI Applications

Product
December 18, 2025/6 min read
Top 10 Questions You Asked About Databricks Clean Rooms, Answered



Platform
December 16, 2025/3 min read
Announcing the winners of the inaugural Databricks Free Edition Hackathon
Product
December 15, 2025/12 min read
Databricks Lakehouse Data Modeling: Myths, Truths, and Best Practices

Product
December 11, 2025/5 min read
OpenAI GPT-5.2 and Responses API on Databricks: Build Trusted, Data-Aware Agentic Systems
Data Intelligence for All

Never miss a Databricks post
Subscribe to our blog and get the latest posts delivered to your inbox