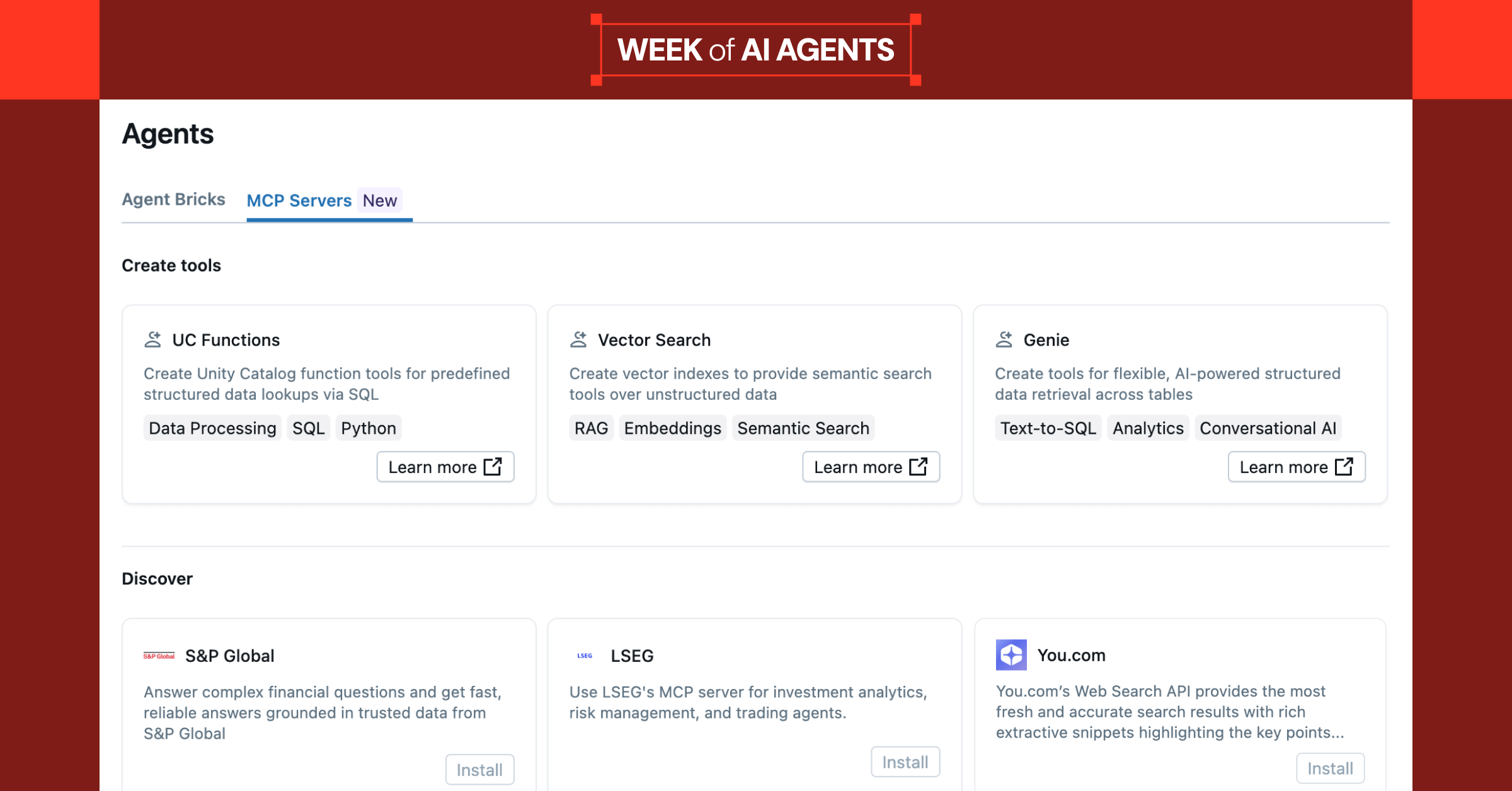
Product
November 3, 2025/5 min read
October 27, 2025/11 min read
News
October 30, 2025/3 min read
Industries
November 13, 2025/2 min read
November 13, 2025/3 min read
November 13, 2025/4 min read
Partners
November 12, 2025/23 min read
November 11, 2025/3 min read
November 11, 2025/6 min read
Manufacturing
November 11, 2025/8 min read
November 11, 2025/7 min read
November 11, 2025/5 min read
November 7, 2025/6 min read
November 7, 2025/3 min read
November 6, 2025/12 min read
Data Leader
November 6, 2025/5 min read
November 6, 2025/6 min read
Customers
November 5, 2025/5 min read
November 5, 2025/4 min read
Data + AI Summit is over, but you can still watch on demand
Subscribe to our blog and get the latest posts delivered to your inbox