Data lake best practices
Data lakes provide a complete and authoritative data store that can power data analytics, business intelligence and machine learning

Data lake best practices
As shared in an earlier section, a lakehouse is a platform architecture that uses similar data structures and data management features to those in a data warehouse but instead runs them directly on the low-cost, flexible storage used for cloud data lakes. Advanced analytics and machine learning on unstructured data is one of the most strategic priorities for enterprises today, and with the ability to ingest raw data in a variety of formats (structured, unstructured, semi-structured), a data lake is the clear choice for the foundation for this new, simplified architecture. Ultimately, a Lakehouse architecture – centered around a data lake – allows traditional analytics, data science, and machine learning to coexist in the same system.
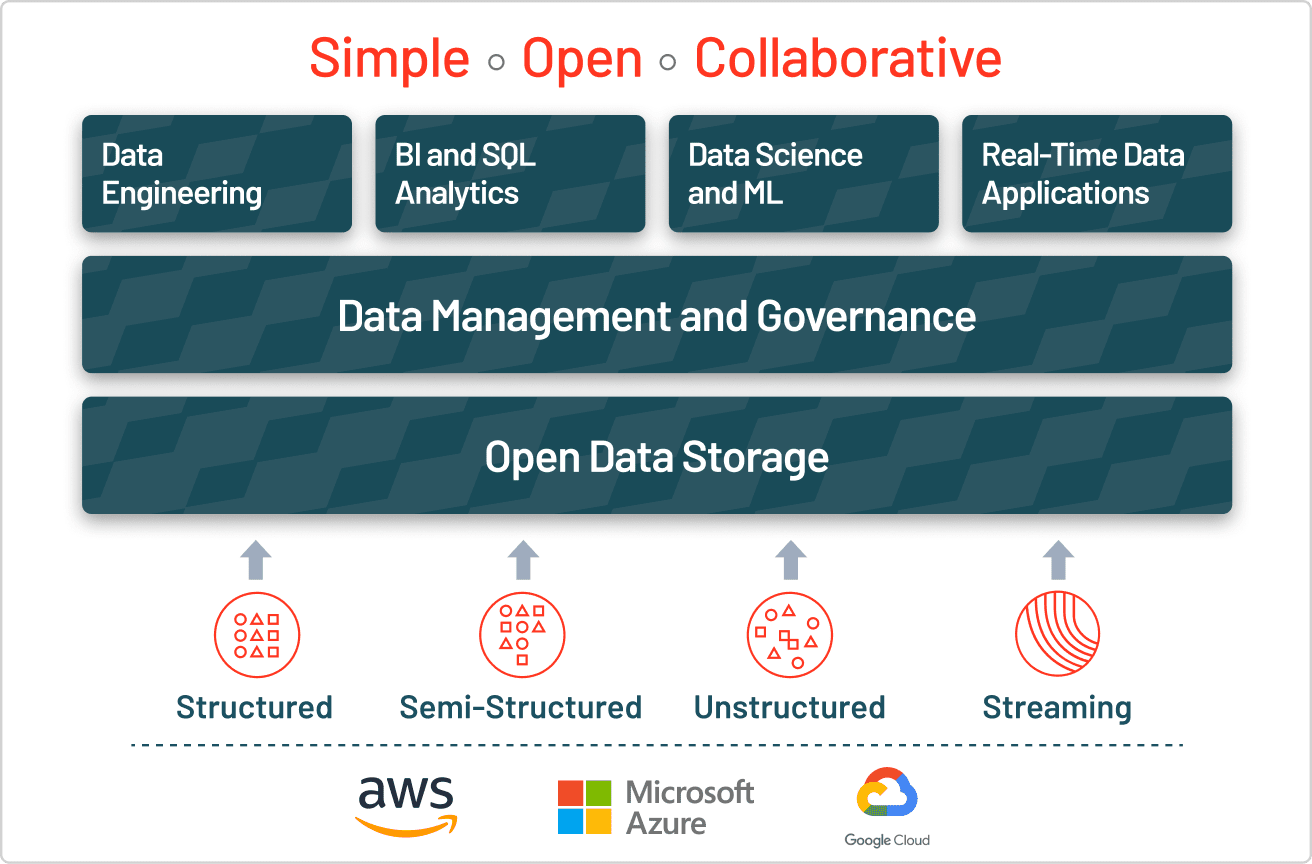
Use the data lake as a foundation and landing zone for raw data
As you add new data into your data lake, it’s important not to perform any data transformations on your raw data (with one exception for personally identifiable information — see below). Data should be saved in its native format, so that no information is inadvertently lost by aggregating or otherwise modifying it. Even cleansing the data of null values, for example, can be detrimental to good data scientists, who can seemingly squeeze additional analytical value out of not just data, but even the lack of it.
However, data engineers do need to strip out PII (personally identifiable information) from any data sources that contain it, replacing it with a unique ID, before those sources can be saved to the data lake. This process maintains the link between a person and their data for analytics purposes, but ensures user privacy, and compliance with data regulations like the GDPR and CCPA. Since one of the major aims of the data lake is to persist raw data assets indefinitely, this step enables the retention of data that would otherwise need to be thrown out.
Secure your lakehouse with role- and view-based access controls
Traditional role-based access controls (like IAM roles on AWS and Role-Based Access Controls on Azure) provide a good starting point for managing data lake security, but they’re not fine-grained enough for many applications. In comparison, view-based access controls allow precise slicing of permission boundaries down to the individual column, row or notebook cell level, using SQL views. SQL is the easiest way to implement such a model, given its ubiquity and easy ability to filter based upon conditions and predicates.
View-based access controls are available on modern unified data platforms, and can integrate with cloud native role-based controls via credential pass-through, eliminating the need to hand over sensitive cloud-provider credentials. Once set up, administrators can begin by mapping users to role-based permissions, then layer in finely tuned view-based permissions to expand or contract the permission set based upon each user’s specific circumstances. You should review access control permissions periodically to ensure they do not become stale.
Build reliability and ACID transactions into your lakehouse by using Delta Lake
Until recently, ACID transactions have not been possible on data lakes. However, they are now available with the introduction of open source Delta Lake, bringing the reliability and consistency of data warehouses to data lakes.
ACID properties (atomicity, consistency, isolation and durability) are properties of database transactions that are typically found in traditional relational database management systems systems (RDBMSes). They’re desirable for databases, data warehouses and data lakes alike because they ensure data reliability, integrity and trustworthiness by preventing some of the aforementioned sources of data contamination.
Delta Lake builds upon the speed and reliability of open source Parquet (already a highly performant file format), adding transactional guarantees, scalable metadata handling, and batch and streaming unification to it. It’s also 100% compatible with the Apache Spark API, so it works seamlessly with the Spark unified analytics engine. Learn more about Delta Lake with Michael Armbrust’s webinar entitled Delta Lake: Open Source Reliability for Data Lakes, or take a look at a quickstart guide to Delta Lake here.
Catalog the data in your lakehouse
In order to implement a successful lakehouse strategy, it’s important for users to properly catalog new data as it enters your data lake, and continually curate it to ensure that it remains updated. The data catalog is an organized, comprehensive store of table metadata, including table and column descriptions, schema, data lineage information and more. It is the primary way that downstream consumers (for example, BI and data analysts) can discover what data is available, what it means, and how to make use of it. It should be available to users on a central platform or in a shared repository.
At the point of ingestion, data stewards should encourage (or perhaps require) users to “tag” new data sources or tables with information about them — including business unit, project, owner, data quality level and so forth — so that they can be sorted and discovered easily. In a perfect world, this ethos of annotation swells into a company-wide commitment to carefully tag new data. At the very least, data stewards can require any new commits to the data lake to be annotated and, over time, hope to cultivate a culture of collaborative curation, whereby tagging and classifying the data becomes a mutual imperative.
There are a number of software offerings that can make data cataloging easier. The major cloud providers offer their own proprietary data catalog software offerings, namely Azure Data Catalog and AWS Glue. Outside of those, Apache Atlas is available as open source software, and other options include offerings from Alation, Collibra and Informatica, to name a few.
Get started with a lakehouse
Now that you understand the value and importance of building a lakehouse, the next step is to build the foundation of your lakehouse with Delta Lake. Check our our website to learn more or try Databricks for free.