Now Generally Available: Simplify Data and Machine Learning Pipelines With Jobs Orchestration
We are excited to announce the general availability of Jobs orchestration, a new capability that lets Databricks customers easily build data and machine learning pipelines consisting of multiple, dependent tasks.
Today, data pipelines are frequently defined as a sequence of dependent tasks to simplify some of their complexity. But, they still demand heavy lifting from data teams and specialized tools to develop, manage, monitor and reliably run such pipelines. These tools are typically separate from the actual data or machine learning tasks. This lack of integration leads to fragmentation of efforts across the enterprise and users having to switch contexts a lot.
Explore why lakehouses are the data architecture of the future with the father of the data warehouse, Bill Inmon.
With today’s launch, orchestrating pipelines has become substantially easier. Orchestrating multi-step Jobs makes it simple to define data and ML pipelines using interdependent, modular tasks consisting of notebooks, Python scripts and JARs. Data engineers can easily create and manage multi-step pipelines that transform and refine data, and train machine learning algorithms, all within the familiar workspace of Databricks, saving teams immense time and effort.
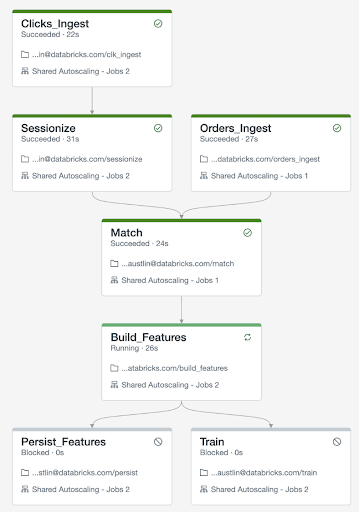
In the example above, a Job consisting of multiple tasks uses two tasks to ingest data: Clicks_Ingest and Orders_Ingest. This ingested data is then aggregated together and filtered in the “Match” task, from which new machine learning features are generated (Build_Features), persistent (Persist_Features), and used to train new models (Train).
We are deeply grateful to the hundreds of customers who provided feedback during a successful public preview of Jobs orchestration with multiple tasks. Based on their input, we have added further improvements: a streamlined debug workflow, information panels that provide an overview of the job at all times, and a new version 2.1 of the Jobs API (AWS|Azure|GCP) with support for new orchestration features.
"Jobs orchestration is amazing, much better than an orchestration notebook. Each of our jobs now has multiple tasks, and it turned out to be easier to implement than I thought. I can't imagine implementing such a data pipeline without Databricks." - Omar Doma, Data Engineering Manager at BatchService
Get started today with the new Jobs orchestration now by enabling it yourself for your workspace (AWS|Azure|GCP). Otherwise, auto-enablement will occur over the course of the following months.
In the coming months, we will make it possible to reuse the same cluster among multiple tasks in a job and to repair failed job runs without requiring a full rerun. We are also looking forward to launching features that will make it possible to integrate with your existing orchestration tools
Enable your workspace
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.