What is Adagrad?
An adaptive learning rate optimizer adjusting step size per parameter based on accumulated past gradients, especially useful for sparse data and NLP
- Adagrad is an optimization algorithm that adapts the learning rate for each parameter based on the history of its gradients.
- Parameters with large, frequent gradients get smaller updates, while rarely updated parameters receive larger steps, which can help with sparse data.
- Adagrad can converge quickly but its learning rates may shrink too much over time, motivating variants that adjust or reset the accumulated gradients.
Gradient descent is the most commonly used optimization method deployed in machine learning and deep learning algorithms. It’s used to train a machine learning model.
Types of Gradient Descent
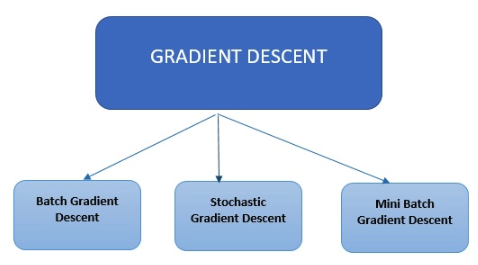 There are three primary types of gradient descent used in modern machine learning and deep learning algorithms.
There are three primary types of gradient descent used in modern machine learning and deep learning algorithms.
Batch Gradient Descent
Batch Gradient Descent is the most straightforward type. It calculates the error for each example in the training dataset, however, it only updates the model after all training examples have been evaluated.
Stochastic Gradient Descent
Stochastic Gradient Descent calculates the error and updates the model for each example in the training dataset.
Mini Batch Gradient Descent
Mini Batch Gradient Descent instead of going over all examples, it sums up over lower number of examples based on the batch size and performs an update for each of these batches. Stochastic Gradient Descent is a common method for optimization. It is conceptually simple and can often be efficiently implemented. However, it features a parameter (the step size) that needs to be manually tuned. There have been proposed different options to automate this tuning. One of the successful scheme is AdaGrad. While standard stochastic subgradient methods mainly follow a predetermined procedural scheme that disregards the characteristics of the data being observed. In contrast, AdaGrad’s algorithms dynamically incorporate knowledge of the geometry of the data observed in earlier iterations to perform more informative gradient-based learning. AdaGrad has been released in two versions. Diagonal AdaGrad (this version is the one used in practice), its main characteristic is to maintain and adapts one learning rate per dimension; the second version known as Full AdaGrad maintains one learning rate per direction (e.g.. a full PSD matrix). Adaptive Gradient Algorithm (Adagrad) is an algorithm for gradient-based optimization. The learning rate is adapted component-wise to the parameters by incorporating knowledge of past observations. It performs larger updates (e.g. high learning rates) for those parameters that are related to infrequent features and smaller updates (i.e. low learning rates) for frequent one. It performs smaller updates As a result, it is well-suited when dealing with sparse data (NLP or image recognition) Each parameter has its own learning rate that improves performance on problems with sparse gradients.
Advantages of Using AdaGrad
- It eliminates the need to manually tune the learning rate
- Convergence is faster and more reliable – than simple SGD when the scaling of the weights is unequal
- It is not very sensitive to the size of the master step
The agentic AI playbook for the enterprise

Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.