What is Automation Bias?
The human tendency to favor automated system suggestions while ignoring contradictory information, risking over-reliance on AI without critical evaluation
- Automation bias is the tendency for people to overtrust automated systems and accept their outputs without sufficient critical thinking.
- Automation bias can lead users to ignore conflicting evidence, fail to catch errors and rely too heavily on recommendations from AI or software tools.
- Managing automation bias requires training, clear system design and safeguards so humans stay engaged and can override incorrect automated decisions.
What is Automation Bias?
Automation bias is an over-reliance on automated aids and decision support systems. As the availability of automated decision aids is increasing additions to critical decision-making contexts such as intensive care units, or aircraft cockpits are becoming more common. It is a human tendency to take the road of least cognitive effort while leaning towards "automation bias". The same concept can be translated to the fundamental way that AI and automation work, which is mainly based on learning from large sets of data. This type of computation assumes that things won’t be radically different in the future. Another aspect that should be considered is the risk of using a flawed training data then the learning will be flawed.
The agentic AI playbook for the enterprise

What is Machine Bias?
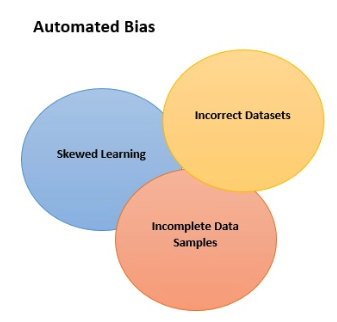
Machine Bias relates to the ways in which algorithms exhibit the bias of the algorithm used or their input data. Today, artificial intelligence (AI) is helping us uncover new insight from data and enhance human decision-making one such example is the face recognition feature used to sign into our smartphones. Unintended bias can come from many causes (Wikipedia lists 184), but the three main drivers are:
- incomplete data samples
- incorrect datasets.
- skewed learning that happens through interactions over time, also known as interaction bias
 We can prevent data bias by using a comprehensive and broad dataset, reflective of all possible edge use cases, the more comprehensive the dataset, the more accurate the AI predictions are going to be. Let’s take a look at several points you should take into consideration when working on your AI. Choose the right learning model for the problem. There’s probably no single model that you can follow in order to completely avoid bias, but there are parameters that can inform your team as it’s building. You will have to identify the best model for a given situation as well as troubleshoot ideas before committing to them Choose a representative training data set. Making sure to use training data that is diverse and includes different groups. Monitor performance using real data. You should be simulating real-world applications as much as possible when building algorithms.
We can prevent data bias by using a comprehensive and broad dataset, reflective of all possible edge use cases, the more comprehensive the dataset, the more accurate the AI predictions are going to be. Let’s take a look at several points you should take into consideration when working on your AI. Choose the right learning model for the problem. There’s probably no single model that you can follow in order to completely avoid bias, but there are parameters that can inform your team as it’s building. You will have to identify the best model for a given situation as well as troubleshoot ideas before committing to them Choose a representative training data set. Making sure to use training data that is diverse and includes different groups. Monitor performance using real data. You should be simulating real-world applications as much as possible when building algorithms.
Additional Resources
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.