What is Big Data Analytics?
Examining massive, varied datasets from IoT devices, social media, and eCommerce to uncover hidden patterns, correlations, and actionable insights
- Big data analytics is the practice of examining very large and varied datasets to uncover patterns, trends and relationships that are hard to see with smaller samples.
- Big data analytics uses advanced techniques such as machine learning, statistics and data mining on data from many sources including logs, sensors and transactions.
- Organizations rely on big data analytics to improve decisions, personalize experiences, manage risk and find new business opportunities.

What Is Big Data Analytics?
Big data analytics is the often complex process of examining large and varied data sets ("big data") generated by sources such as eCommerce, mobile devices, social media and the Internet of Things (IoT). It involves integrating different data sources, transforming unstructured data into structured data, and generating insights from the data using specialized tools and techniques that spread out data processing over an entire network.
The amount of digital data is growing rapidly, doubling roughly every two years. Big data analytics offer a different approach for managing and analyzing all of these data sources. While the principles of traditional data analytics generally still apply, the scale and complexity of big data analytics required the development of new ways to store and process the petabytes of structured and unstructured data involved.
Core Process & Methods
The demand for faster speeds and greater storage capacities created a technological vacuum that was soon filled by approaches, including:
- Storage methods such as data warehouses and data lakes
- Nonrelational databases like NoSQL
- Data processing and data management technologies and frameworks, such as open source Apache Hadoop, Spark, and Hive.
Big data analytics takes advantage of advanced analytic techniques to analyze really big data sets that include structured, semi-structured and unstructured data, from various sources, and in different sizes from terabytes to zettabytes.
Traditional Data Analytics vs. Big Data Analytics
Prior to the invention of Hadoop, the technologies underpinning modern storage and compute systems were relatively basic, limiting companies mostly to the analysis of "small data." Even this form of analytics could be difficult, especially the integration of new data sources. With traditional data analytics, which relies on relational databases of structured data, every byte of raw data needs to be formatted in a specific way before it can be ingested into the database for analysis. This often lengthy process, commonly known as extract, transform, load (or ETL) is required for each new data source. The main problem with this 3-part process and approach is that it’s incredibly time and labor intensive, sometimes requiring up to 18 months for data scientists and engineers to implement or change. 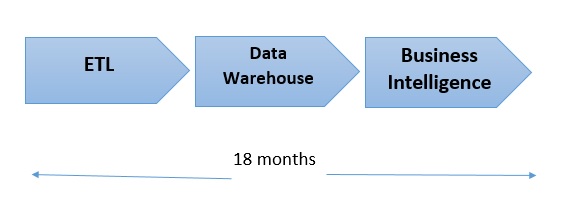
The agentic AI playbook for the enterprise

Most Common Data Types in Big Data Analytics
- Web data: Customer level web behavior data such as visits, page views, searches, purchases, etc.
- Text data: Data generated from sources of text including email, news articles, Facebook feeds, Word documents, and more is one of the biggest and most widely used types of unstructured data.
- Time and location, or geospatial data: GPS and cell phones, as well as Wi-Fi connections, make time and location information a growing source of interesting data. This can also include geographic data related to roads, buildings, lakes, addresses, people, workplaces, and transportation routes, which have been generated from geographic information systems.
- Real-time media: Real-time data sources can include real-time streaming or event-based data.
- Smart grid and sensor data: Sensor data from cars, oil pipelines, windmill turbines, and other sensors is often collected at extremely high frequency.
- Social network data: Unstructured text (comments, likes, etc.) from social network sites like Facebook, LinkedIn, Instagram, etc. is growing. It is even possible to do link analysis to uncover the network of a given user.
- Linked data: this type of data has been collected using standard Web technologies like HTTP, RDF, SPARQL, and URLs.
- Network data: Data related to very large social networks, like Facebook and Twitter, or technological networks such as the Internet, telephone and transportation networks.
Big data analytics helps organizations harness their data and use advanced data science techniques and methods, such as natural language processing, deep learning, machine learning, uncovering hidden patterns, unknown correlations, market trends and customer preferences, to identify new opportunities and make more informed business decisions.
Advantages of Using Big Data Analytics Include:
- Cost reduction: Cloud computing and storage technologies, such as Amazon Web Services (AWS) and Microsoft Azure, as well as Apache Hadoop, Spark, and Hive can help companies decrease their expenses when it comes to storing and processing large data sets.
- Improved decision making: With the speed of Spark and in-memory analytics, combined with the ability to quickly analyze new sources of data, businesses can generate immediate and actionable insights needed to make decisions in real time.
- New products and services: With the help of big data analytics tools, companies can more precisely analyze customer needs, making it easier to give customers what they want in terms of products and services.
- Fraud detection: Big data analytics is also used to prevent fraud, mainly in the financial services industry, but it is gaining importance and usage across all verticals.
Additional Resources
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.