What is a Catalyst Optimizer?
How the Catalyst optimizer uses rule-based and cost-based techniques on tree-structured query plans to make Spark SQL queries faster, more efficient and easier to extend
- The Catalyst optimizer is the query optimization framework inside Spark SQL that turns user queries into efficient execution plans.
- Catalyst builds a logical plan of operations, applies rule based transformations and then chooses physical strategies based on cost.
- Through techniques like predicate pushdown, column pruning and join reordering, Catalyst helps Spark run SQL workloads faster and more efficiently.
At the core of Spark SQL is the Catalyst optimizer, which leverages advanced programming language features (e.g. Scala’s pattern matching and quasi quotes) in a novel way to build an extensible query optimizer. Catalyst is based on functional programming constructs in Scala and designed with these key two purposes:
- Easily add new optimization techniques and features to Spark SQL
- Enable external developers to extend the optimizer (e.g. adding data source specific rules, support for new data types, etc.)
The agentic AI playbook for the enterprise

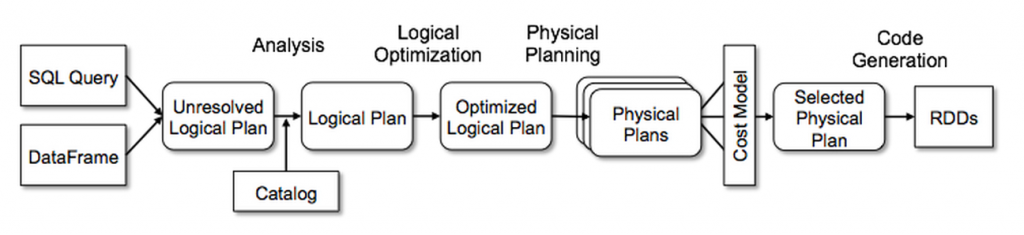
Catalyst contains a general library for representing trees and applying rules to manipulate them. On top of this framework, it has libraries specific to relational query processing (e.g., expressions, logical query plans), and several sets of rules that handle different phases of query execution: analysis, logical optimization, physical planning, and code generation to compile parts of queries to Java bytecode. For the latter, it uses another Scala feature, quasiquotes, that makes it easy to generate code at runtime from composable expressions. Catalyst also offers several public extension points, including external data sources and user-defined types. As well, Catalyst supports both rule-based and cost-based optimization.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.