What is Data Flow?
Movement and transformation of data from source to destination via streaming pipelines, batch workflows, real-time event processing, and orchestrated ETL
- A data flow describes how data moves from sources through transformations to destinations such as dashboards, models or downstream systems.
- Mapping data flows helps teams design pipelines, identify dependencies and spot bottlenecks or risks in how information travels.
- Databricks workflows and lakehouse patterns give organizations a clear way to define, orchestrate and monitor end to end data flows for analytics and AI.
Data flow describes the movement of data through a system’s architecture, from one process or component to another. It describes how data is input, processed, stored and output within a computer system, application or network. Data flow has a direct impact on the efficiency, reliability and security of any IT system, making it crucial that a system is properly configured to optimize its outputs.
Key Elements of Data Flow Systems
There are several key components that define how data moves and is processed within a data flow system:
Data Source
Data flow begins with the ingestion of data from a given source, which can include both structured and unstructured data, scripted sources or customer inputs. These sources initiate data flow and set the data flow system into motion.
Data Transformation
Once data has been ingested into the system, data may undergo a transformation into a structure or format usable for analysis or data science. Data transformation occurs according to data transformation rules, which define how data should be handled or modified throughout a system. This helps ensure data is in the correct format for your business processes and outcomes.
Data Sink
Once data has been ingested and transformed, the final destination of the processed data is the data sink. This is the endpoint in a data system, where data is used without being transferred any further in the data flow. This can include a database, lakehouse, reports or log files where data is recorded for audit or analysis.
Data Flow Paths
Data flow diagrams define the pathways or channels through which data travels between sources, processes and destinations. These paths can include physical network connections, or logical paths like API calls, and they also feature protocols and channels for secure and efficient data transmission.
Types of Data Flow
Depending on how your organization arranges its data pipeline, there are some common ways data flow can be handled. An extract, transform, load (ETL) process organizes, prepares and centralizes data from multiple sources, making it accessible and usable for analysis, reporting and operational decision-making. By managing the flow of data from source systems to a target database or data warehouse, ETL enables data integration and consistency, which are essential for generating reliable insights and supporting data-driven strategies.
Real-time Analytics
This data flow can process an infinite number of records from the original source and process a continuous incoming stream of data. This gives users instant analysis and insights, which can be useful for applications where timely responses are essential, such as monitoring, tracking, recommendations and any automated actions.
Operational Data Pipelines
Operational data pipelines are designed to handle transactional and operational data critical for the ongoing, day-to-day functions of an organization. These pipelines capture data from various sources, such as customer interactions, financial transactions, inventory movements and sensor readings, and ensure that this data is processed, updated and available across systems in near real time or at low latency. The purpose of operational data pipelines is to keep applications and databases synchronized, ensuring that business operations can run smoothly and that all systems reflect the latest state of data.
Batch Processing
Batch processing in data flow refers to the handling of large volumes of data at scheduled intervals or after collecting sufficient data to process at once. Unlike real-time processing, batch processing doesn’t need instant results; instead, it focuses on efficiency, scalability and processing accuracy by aggregating data before processing it. Batch processing is often used for tasks like reporting, historical analysis and large-scale data transformations where immediate insights aren’t essential.
Tools and technologies for data flow
An ETL workflow is a common example of data flow. In ETL processing, data is ingested from source systems and written to a staging area, transformed based on requirements (ensuring data quality, deduplicating records, flagging missing data), and then written to a target system such as a data warehouse or data lake.
Robust ETL systems in your organization can help optimize your data architecture for throughput, latency, cost and operational efficiency. This gives you access to high-quality, timely data to guide precise decision-making.
Delta Live Tables for Data Flow
With the sheer amount and variety of business-critical data being generated, the need to understand your data flow is essential for good data engineering. While many companies need to choose between batch and real-time streaming to handle their data, Databricks offers one API for both batch and streaming data. Tools like Delta Live Tables help users optimize for cost at one end and latency or throughput at the other end by easily switching processing modes. This can help users future-proof their solutions by easily preparing them to migrate to streaming as their business needs evolve.
The agentic AI playbook for the enterprise

Data Flow Diagrams
One of the ways organizations illustrate the flow of data throughout the system is by creating a data flow diagram (DFD). This is a graphical representation that shows how information is collected, processed, stored and used by establishing the directional flow of data between different parts of the system. The kind of DFD you need to construct depends on the complexity of your data architecture, as they can be as simple as an overview of data flow, or a deeper multilevel DFD that describes how data is handled at different stages in the lifecycle.
DFDs have evolved over time and today Delta Live Tables uses directed acyclic graphs (DAGs) to represent the sequence of data transformations and dependencies between tables or views within a pipeline. Each transformation or table is a node, and the edges between nodes define the data flow and dependencies. This ensures that operations are executed in the correct order and in a directionally closed loop.
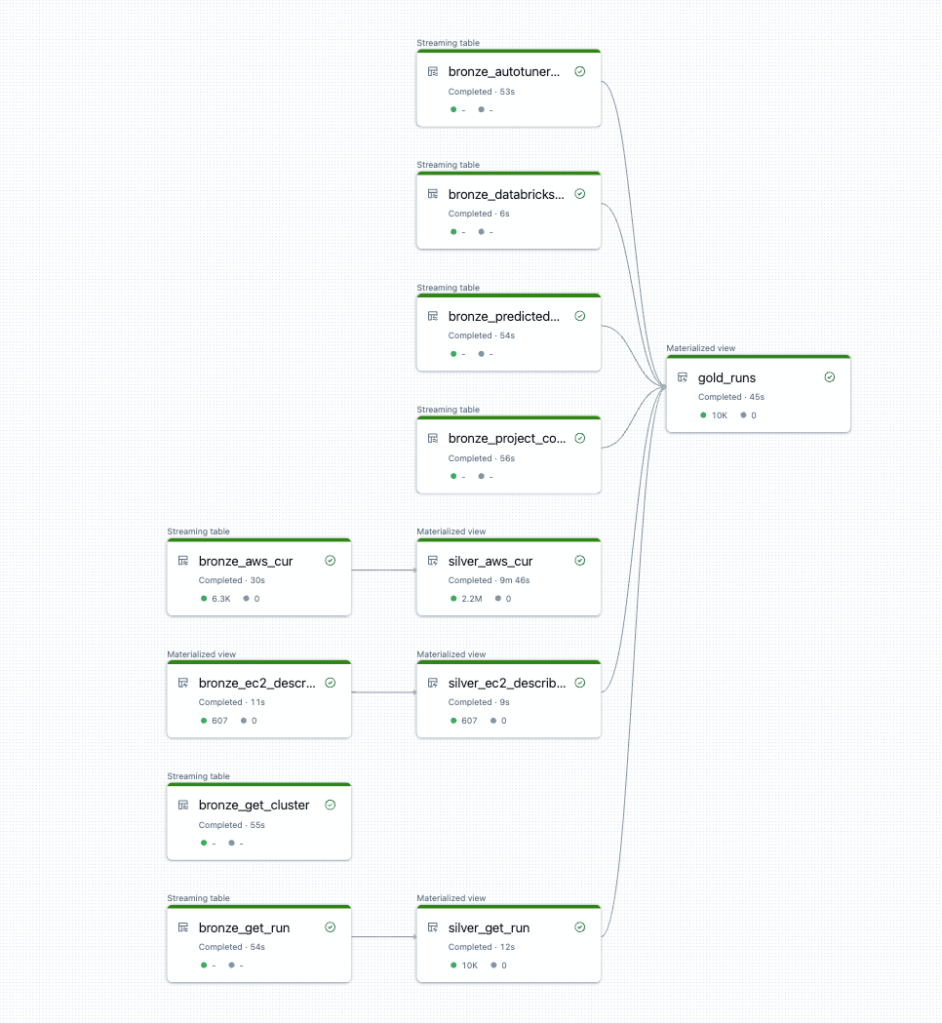
Directed Acyclic Graphs (DAGs)
DAGs offer visual clarity to understand the relationships between tasks and they can also help identify and manage errors or failures in the data flow system. Delta Live Tables ensures that the DAG is managed efficiently, scheduling and optimizing operations like data loading, transformations and updates to maintain consistency and performance.
Best Practices for Data Flow Management
Some best practices should be followed to ensure your data flow is optimized, efficient and secure:
Optimize Data Process
This involves streamlining the flow of data to eliminate bottlenecks, reduce redundancy and enable real-time processing. Regularly reviewing and refining workflows ensures that data flows through the system without unnecessary complexity, which reduces resource consumption and enhances scalability.
Ensure Seamless Information Flow
To achieve a seamless flow of information, it’s important to minimize data silos and prioritize interoperability across systems. By implementing strict ETL pipelines, organizations can take advantage of consistent data across various applications, departments and uses. This also means creating reliable backup and recovery processes to hedge against system failures or outages.
Security Considerations
Of course, making your data secure within its flow is paramount. All data, especially sensitive or personally identifiable information, should be encrypted while it’s being transferred or stored. Limiting data access can help reduce the risk of unauthorized data exposure, and regularly conducting security audits and vulnerability assessments can identify potential weak points, allowing proactive measures to secure the data flow from end to end.
Performance Monitoring
Using analytics tools to track metrics like latency, data transfer speeds and error rates can identify areas where data flow may lag or encounter issues. Setting up automated alerts and dashboards ensures that teams are immediately informed of any issues, enabling quick resolution and minimal disruption. Regular performance reviews can also provide actionable insights, ensuring a robust, secure and efficient management process.
Benefits of Efficient Data Flow
Efficient data flow can make a material difference in your organization’s bottom line. By optimizing the seamless and rapid flow of data across systems and departments, you can streamline workflows, improve productivity and reduce the time it takes to process information.
For more information on how Databricks can help your organization achieve optimal data flow, review some of our lakehouse reference architecture. Additionally, learn more about our medallion architecture, which is a data design pattern used to logically organize data in a lakehouse.
If you’d like more information on how Delta Live Tables can prepare your organization to handle both batch and streaming data, contact a Databricks representative.
Crucially, an efficient data flow can help your organization make informed decisions that respond to operational or customer challenges. When you have immediate access to data, you can make real-time decisions with the most up-to-date information. And with efficient data flows, you can be confident that the information is consistent and reliable.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.