What is Feature Engineering?
Transforming raw data into informative features for ML models through selection, extraction, construction, and transformation techniques
- Feature engineering is the practice of creating and selecting input variables, or features, from raw data so machine learning models can learn patterns more effectively.
- Feature engineering includes tasks such as cleaning, transforming, aggregating and encoding data to highlight the signals that matter for a given prediction problem.
- On Databricks, feature engineering is supported by the lakehouse and feature store so teams can build, share and reuse high quality features across models.

Feature engineering is the process of transforming raw data into relevant features for use by machine learning models. It involves selecting and creating input variables (features) that help ML algorithms learn patterns more effectively and make accurate predictions.
Features, in the context of machine learning, are the input data that is used to train a model. They are the attributes of some entity that the model will learn about. Raw data typically must be processed before it can be used as input to an ML model. Good feature engineering makes the process of model development more efficient and leads to models that are simpler, more flexible and more accurate.

What is Included in Feature Engineering?
Feature engineering is the process of transforming and enriching data to improve the performance of machine learning algorithms used to train models using that data.
Feature engineering includes steps such as scaling or normalizing data, encoding non-numeric data (such as text or images), aggregating data by time or entity, joining data from different sources, or even transferring knowledge from other models. The goal of these transformations is to increase the ability of machine learning algorithms to learn from the data set and thus make more accurate predictions.
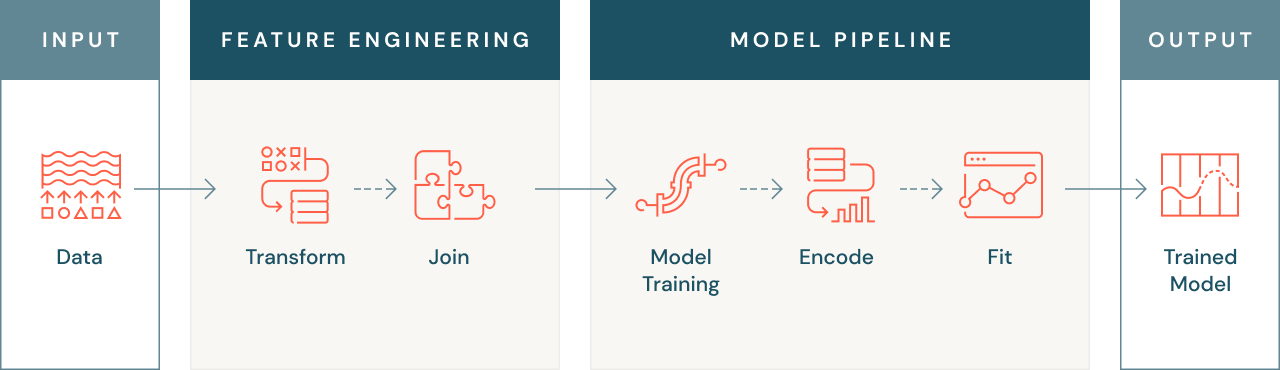
Why is Feature Engineering Important?
1. Transforming Data for Model Compatibility
Machine learning models sometimes can't operate on raw data, and so the data must be transformed into a numeric form that the model can understand. This could involve converting text or image data into numeric form, or creating aggregate features such as average transaction values for a customer.
2. Combining Data From Multiple Sources
Sometimes relevant features for a machine learning problem may exist across multiple data sources, and so effective feature engineering involves joining these data sources together to create a single, usable data set. This allows you to use all of the available data to train your model, which can improve its accuracy and performance.
3. Leveraging Transfer Learning
Another common scenario is that other models' output and learning can sometimes be reused in the form of features for a new problem, using a process known as transfer learning. This allows you to leverage the knowledge gained from previous models to improve the performance of a new model. Transfer learning can be particularly useful when dealing with large, complex data sets where it is impractical to train a model from scratch.
Effective feature engineering also enables reliable features at inference time, when the model is being used to make predictions on new data. This is important because the features used at inference time must be the same as the features used at training time, in order to avoid "online/offline skew," where the features used at the time of prediction are calculated differently than those used for training.
Benefits of Feature Engineering
Having an effective feature engineering pipeline means more robust modeling pipelines, and ultimately more reliable and performant models. Improving the features used both for training and inference can have an incredible impact on model quality, so better features means better models.
From a different perspective, effective feature engineering also encourages reuse, not only saving practitioners time but also improving the quality of their models. This feature reuse is important for two reasons: it saves time, and having robustly defined features helps prevent your models from using different feature data between training and inference, which typically leads to "online/offline" skew.
Feature Engineering vs. Data Transformation
The goal of feature engineering is to create a data set that can be trained to build a machine learning model. Many of the tools and techniques used for data transformations are also used for feature engineering.
Because the emphasis of feature engineering is to develop a model, there are several requirements that are not present with all feature transformations. For example, you may want to reuse features across multiple models or across teams in your organization. This requires a robust method for discovering features.
Also, as soon as features are reused, you will need a way to track where and how features are computed. This is called feature lineage. Reproducible feature computations are of particular importance for machine learning, since the feature not only must be computed for training the model but also must be recomputed in exactly the same way when the model is used for inference.
The agentic AI playbook for the enterprise

Feature Engineering Tools
Generally the same tools that are used for data engineering can be used for feature engineering, as most of the transforms are common between the two. This usually entails some data storage and management system, access to standard open transformation languages (SQL, Python, Spark, etc.), and access to some type of compute to run the transformations.
There are, however, some additional tools that can be implemented for feature engineering in the form of specific Python libraries that can help with the machine learning–specific data transformations — such as embedding text or images, or one-hot encoding categorical variables. There are also some open source projects that aid in tracking features that a model uses.
Data versioning is an important tool for feature engineering, since models can often be trained on a data set that has since been modified. Having proper data versioning allows you to reproduce a given model while your data naturally evolves over the course of time.
What is a Feature Store?
A feature store is a tool designed to address the challenges of feature engineering. A feature store is a centralized repository for features across an organization. Data scientists can use a feature store to discover and share features and track feature lineage. A feature store also ensures that the same feature values are used at training and inference times. This reproducible feature computation is of particular importance for machine learning, since the feature not only must be computed for training the model but also must be recomputed in exactly the same way when the model is used for inference.
Why Use Databricks Feature Store?
Databricks Feature Store is fully integrated with other components of Databricks. You can use Databricks notebooks to develop code to create features and build models based on those features. When you serve models with Databricks, the model automatically looks up feature values from the feature store for inference. The Databricks Feature Store also provides the benefits of feature stores described in this article:
Feature Discoverability and Lineage
- Discoverability: The Feature Store UI, accessible from the Databricks workspace, lets you browse and search for existing features.
- Lineage: When you create a feature table with Databricks Feature Store, the data sources used to create the feature table are saved and accessible. For each feature in a feature table, you can also access the models, notebooks, jobs and endpoints that use the feature.
Model Integration and Serving
When you use features from Databricks Feature Store to train a model, the model is packaged with feature metadata. When you use the model for batch scoring or online inference, it automatically retrieves features from Databricks Feature Store. The caller does not need to know about them or include logic to look up or join features to score new data. This makes model deployment and updates much easier.
Point-in-Time Lookups
Databricks Feature Store supports time series and event-based use cases that require point-in-time correctness.
Additional Resources
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.