Introducing Databricks AutoML: A Glass Box Approach to Automating Machine Learning Development

Today, we announced Databricks AutoML, a tool that empowers data teams to quickly build and deploy machine learning models by automating the heavy lifting of preprocessing, feature engineering and model training/tuning. With this launch, data teams can select a dataset, configure training, and deploy models entirely through a UI. We also provide an advanced experience in which data scientists can access generated notebooks with the source code for each trained model to customize training or collaborate with experts for productionization. Databricks AutoML integrates with the Databricks ML ecosystem, including automatically tracking trial run metrics and parameters with MLflow and easily enabling teams to register and version control their models in the Databricks Model Registry for deployment.
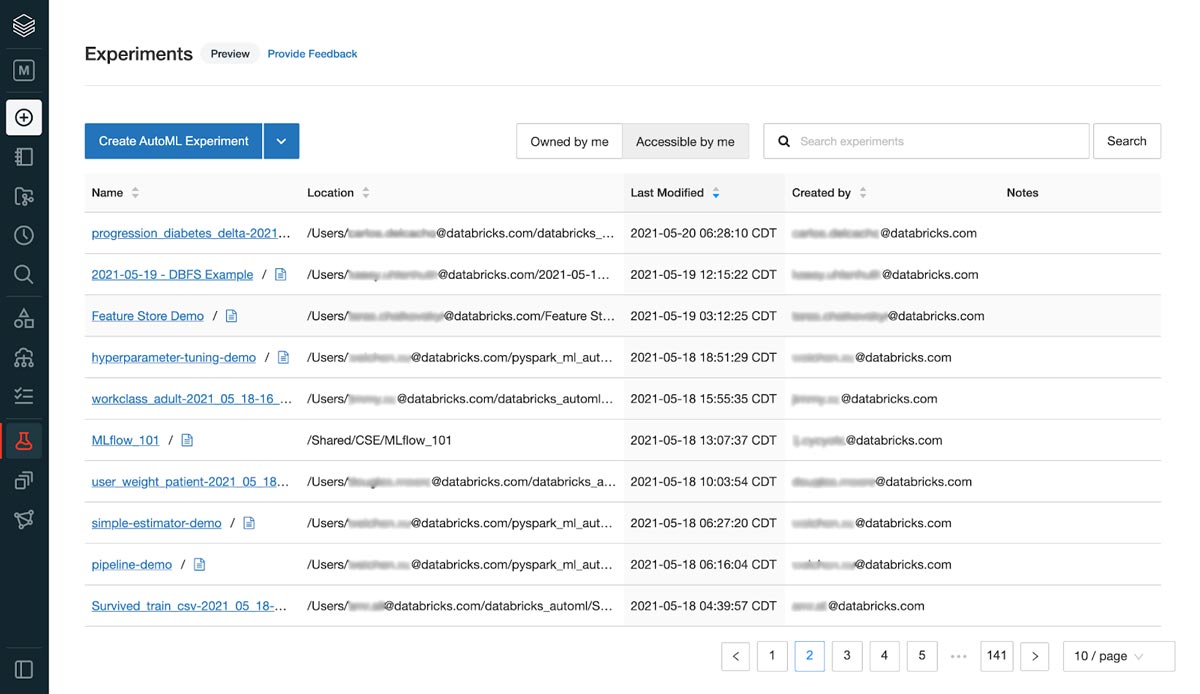
A glass box approach to AutoML
Today, many existing AutoML tools are opaque boxes -- meaning users don’t know exactly how a model was trained. Data scientists hit a wall with these tools when they need to make domain-specific modifications or when they work in an industry that requires auditability for regulatory reasons. Data teams then have to invest the time and resources to reverse engineer these models to make customizations, which counteracts many of the productivity gains they were supposed to receive.
That’s why we are excited to bring customers Databricks AutoML, a glass box approach to AutoML that provides Python notebooks for every model trained to augment developer workflows.
Data scientists can leverage their domain expertise and easily add or modify cells to these generated notebooks. Data scientists can also use Databricks AutoML generated notebooks to jumpstart ML development by bypassing the need to write boilerplate code.
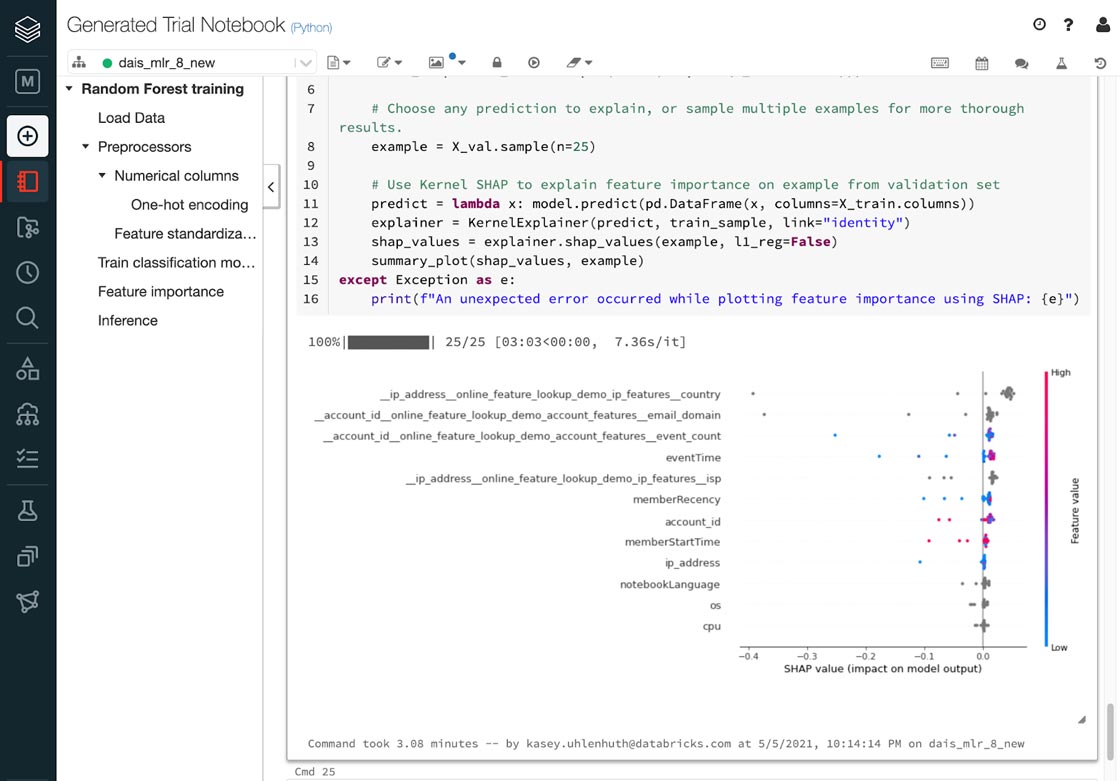
Get quick insights into datasets
In addition to model training and selection, Databricks AutoML creates a data exploration notebook to give basic summary stats on a dataset. By automating the data exploration stage, which many find tedious, Databricks AutoML saves data scientists time and allows them to quickly gut check that their datasets are fit for training. The data exploration notebooks use pandas profiling to provide users with warnings--high cardinality, correlations, and null values--as well as information on the distribution of variables.
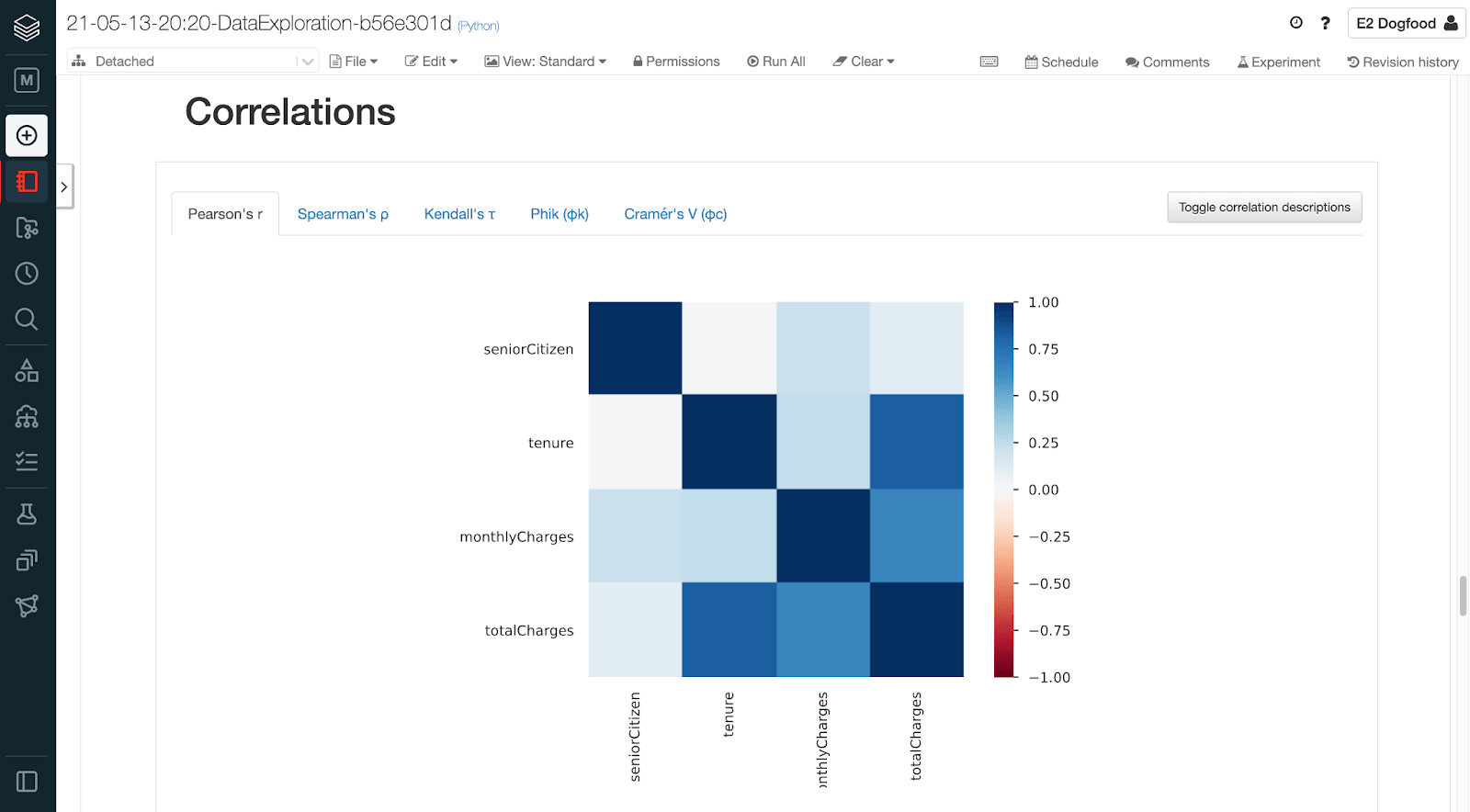
Learn ML best practices
The AutoML experience integrates with MLflow--our API for tracking metrics/parameters across trial runs--and uses ML best practices to help improve productivity on data science teams:
- From the Experiments page, data scientists can compare trial runs and register and serve models in the Databricks Model Registry.
- Our generated training notebooks provide all the code used to train a given model--from loading data to splitting test/train sets to tuning hyperparameters to displaying SHAP plots for explainability.
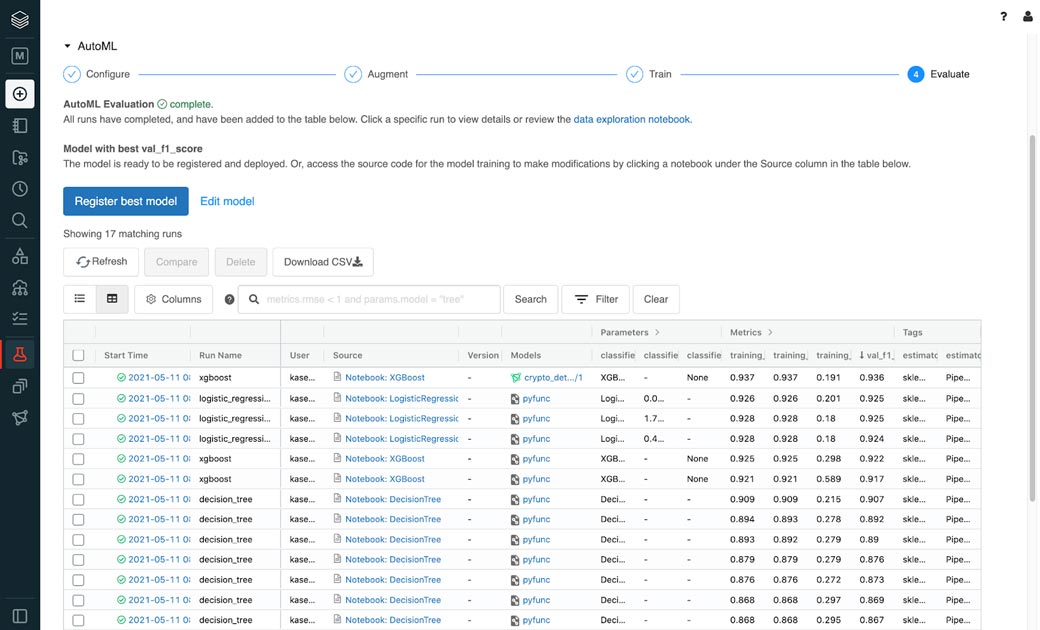
AutoML public preview features
The Databricks AutoML Public Preview parallelizes training over sklearn and xgboost models for classification (binary and multiclass) and regression problems. We support datasets with numerical, categorical and timestamp features and automatically handle one-hot encoding and null imputation. Trained models are sklearn pipelines such that all data preprocessing is wrapped with the model for inference.
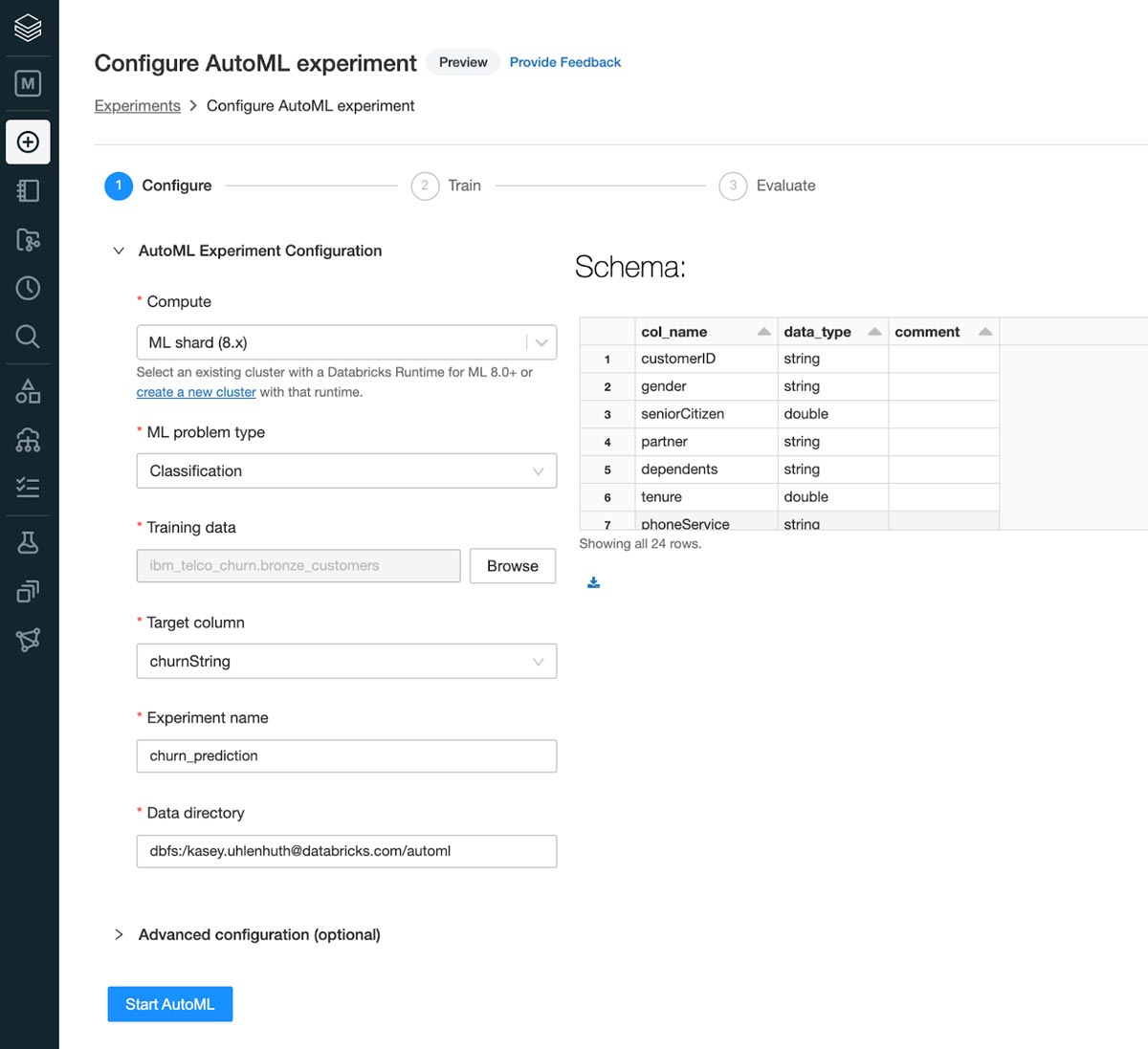
Additionally, Databricks AutoML has several advanced options. Many teams are trying to get quick answers from AutoML, so customers can control how long AutoML training lasts through configurable stopping conditions: a wall-clock timeout or the maximum number of trials to run. They can also configure the evaluation metric for ranking model performance.
Get started with Databricks AutoML public preview
Databricks AutoML is now in Public Preview and is part of the Databricks Machine Learning experience. To get started:
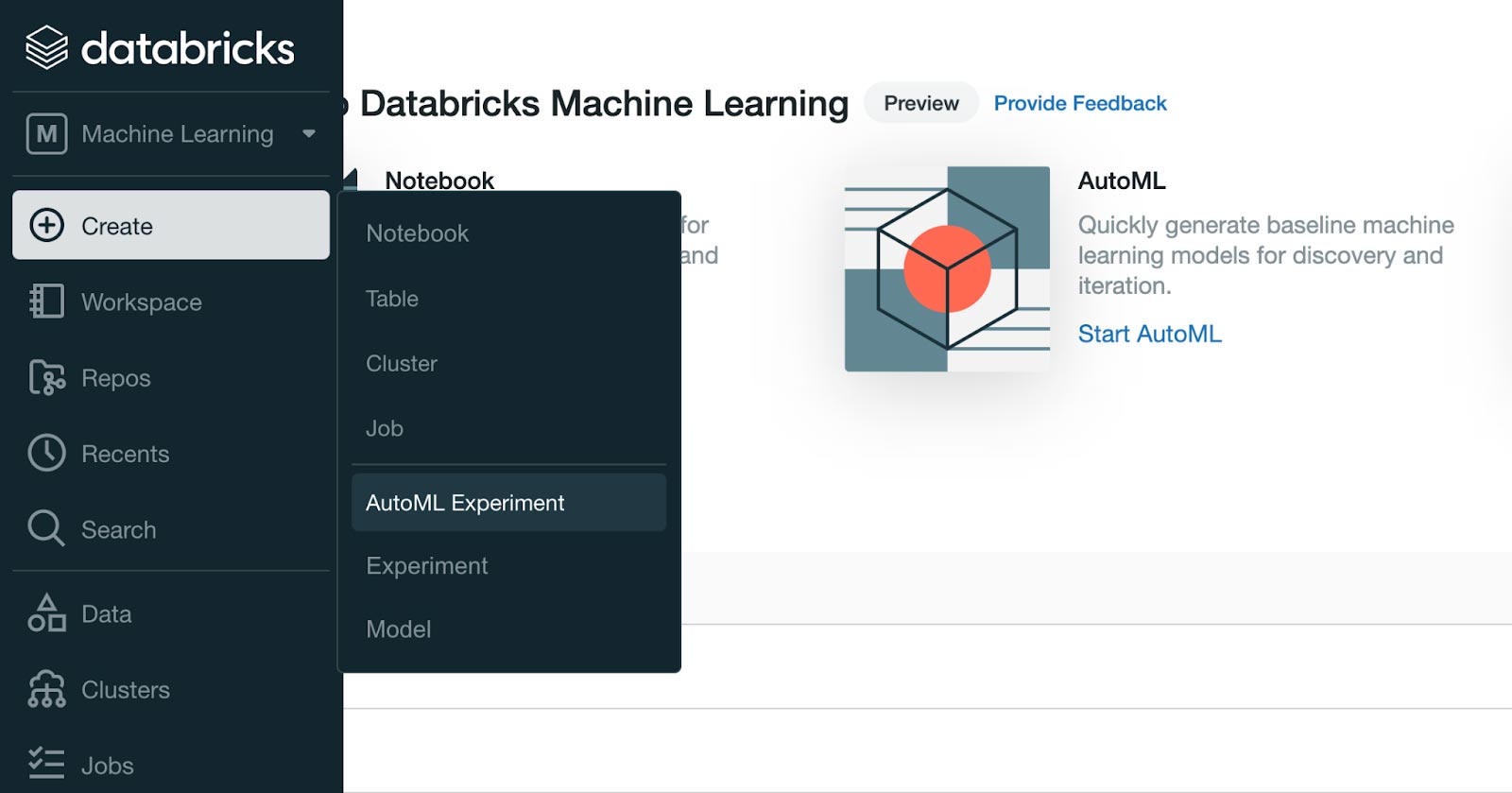
- Use the left-hand sidebar to switch to the “Machine Learning'' experience to access Databricks AutoML via the UI. Click on the “(+) Create” on the left navigation bar and click “AutoML Experiment” or navigate to the Experiments page and click “Create AutoML Experiment” to get started.
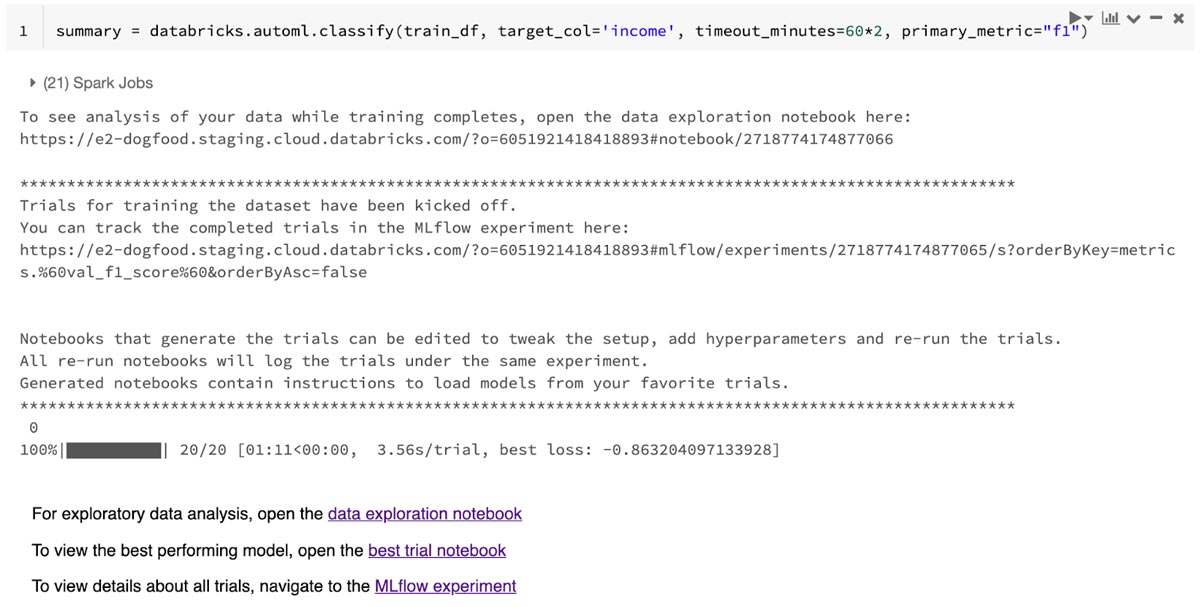
- Use the AutoML API, a single-line call, which can be seen in our documentation.
Ready to get started or try Databricks AutoML out for yourself? Read more about Databricks AutoML and how to use it on AWS, Azure, and GCP.
Never miss a Databricks post
What's next?


Product
November 21, 2024/3 min read