
While large language models (LLMs) are increasingly adept at solving general tasks, they can often fall short on specific domains that are dissimilar to the data they were trained on. In such cases, how do you effectively and efficiently adapt an open-source LLM to your needs? This can be challenging due to the many decisions involved, such as training methods and data selection. This blog post will explore one method for customizing LLMs — Continued Pre-Training (CPT) — and provide guidance on executing this process effectively. Furthermore, we consider how CPT can be used as a tool to efficiently characterize datasets, i.e. better understand which evaluation metrics are helped, hurt, or unaffected by the data.
Effective CPT requires attention to three key hyperparameters: (1) learning rate, (2) training duration, and (3) data mixture. In addition, simple weight averaging is an easy way to mitigate forgetting caused by CPT. This blog outlines these processes from start to finish to help you unlock the most value from your CPT runs.
Continued Pre-Training vs. Fine-Tuning
What is Continued Pre-Training (CPT), and how does it differ from fine-tuning?
When working with a new, specific domain (eg. a medical domain) that was not well represented in a model’s pre-training corpus, the model might lack factual knowledge critical to performing well on that domain. While one could pre-train a new model from scratch, this is not a cost-effective strategy as pre-trained models already possess many core language and reasoning capabilities that we want to leverage on the new domain. Continued Pre-Training refers to the cost effective alternative to pre-training. In this process, we further train a base pre-trained LLM on a large corpus of domain-specific text documents. This augments the model’s general knowledge with specific information from the particular domain. The data typically consists of large amounts of raw text, such as medical journals or mathematical texts.
Fine-Tuning, on the other hand, involves training a language model on a much smaller, task-specific dataset. This dataset often contains labeled input-output pairs, such as questions and answers, to align the model’s behavior to perform a specific, well-defined task. While a CPT dataset might contain billions of tokens of raw, unstructured text, a fine-tuning dataset will contain millions of tokens of structured input-output pairs. This is often not a sufficient amount of data to teach a model factual information from a completely new domain. In this case, it would be more effective to fine-tune for style and alignment after CPT.
In this post, we focus on the case of continued pre-training. We demonstrate how CPT can enhance a small LLM’s factual knowledge performance to match that of a much larger LLM. We will outline the entire process for:
- Showing how to optimize hyperparameters.
- Measuring the effect of different datasets.
- Developing heuristics for mixing datasets.
- Mitigating forgetting.
Finally we consider how the performance gains from continued pre-training scale with training FLOPS, a measure of the amount of compute used to train the model.
How to do Continued Pre-training
Task and Evaluation
For our experiments, we will evaluate our model on the MMLU benchmark, which tests the model’s ability to recall a wide range of facts. This benchmark provides a stand in for the general process of factual knowledge acquisition in LLMs.
In addition to the MMLU benchmark, we will monitor the Gauntlet Core Average[1], which averages a large set of language modeling benchmarks. This allows us to track the core language and reasoning capabilities of the model, ensuring it doesn’t lose skills in reading comprehension and language understanding, which are essential for other downstream tasks. Monitoring Core Average is a great way to keep track of forgetting in LLMs.
Models
We aim to see if we can start with a Llama-2-7B base model and elevate its performance to match that of a Llama-2-13B base model using CPT. To study CPT across model scales, we also demonstrate its efficacy at improving Llama-2-13B and Llama-2-70B.
Example Datasets
For this experiment, we considered 5 datasets that we intuited could potentially help MMLU: OpenWebMath, FLAN, Wikipedia, Stack Exchange, and arXiv . These datasets, ranging from 8B to 60B tokens, were chosen for their high-quality sources and dense information to maximize general knowledge exposure.
Hyperparameters: The Key to Performance
When further training open-source base models, two critical hyperparameters are the learning rate (LR) and the training duration. The optimal values for these hyperparameters can vary based on the model, dataset size, dataset composition, and benchmark. Therefore, it is essential to sweep both hyperparameters while iterating.
We use the following procedure to set these hyperparameters for OpenWebMath. We swept the LR for 15B tokens with values of 10e-6, 3e-6, 10e-5, and 3e-5. In Figure 1a, we can see that the accuracy on MMLU can vary by as much as 5 percentage points based on the LR, indicating the importance of this hyperparameter. Typically, 1B to 10B tokens are sufficient for identifying the optimal LR.
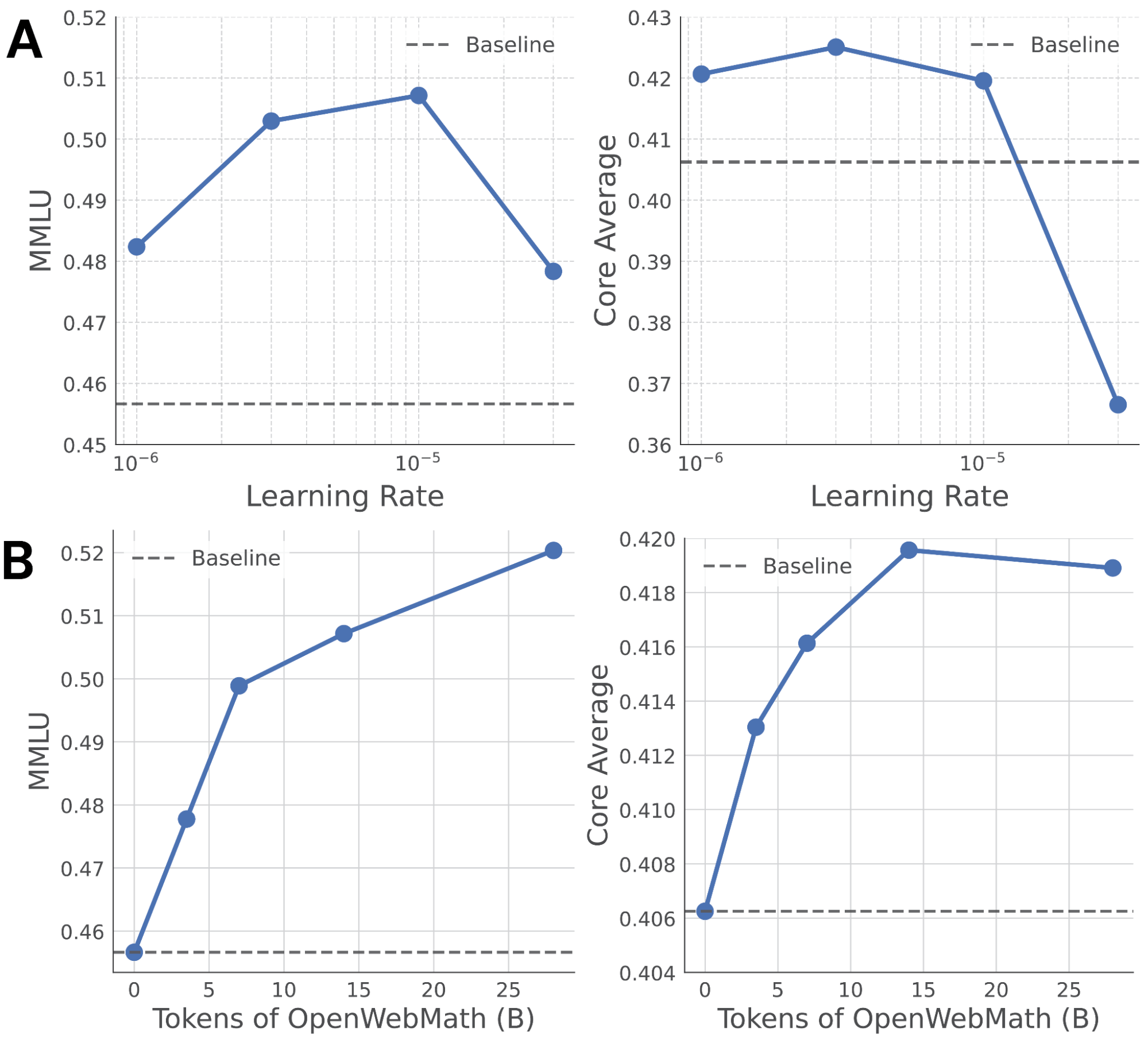
After identifying the optimal LR, we trained on OpenWebMath for longer durations to determine the optimal training period (Figure 1B). In addition to measuring the performance on our target MMLU metric, we also measure the Core Average to monitor forgetting.
Capturing the impact of the dataset
We repeated the LR sweep (like the one shown in Figure 1A for OpenWebMath) for each of our five datasets, training for between 1B and 10B tokens each time. Surprisingly, only two of these high-quality datasets improved our model’s performance: OpenWebMath and FLAN. The other datasets reduced accuracy across all LRs. Notably, the optimal learning rates for the different datasets were not the same.
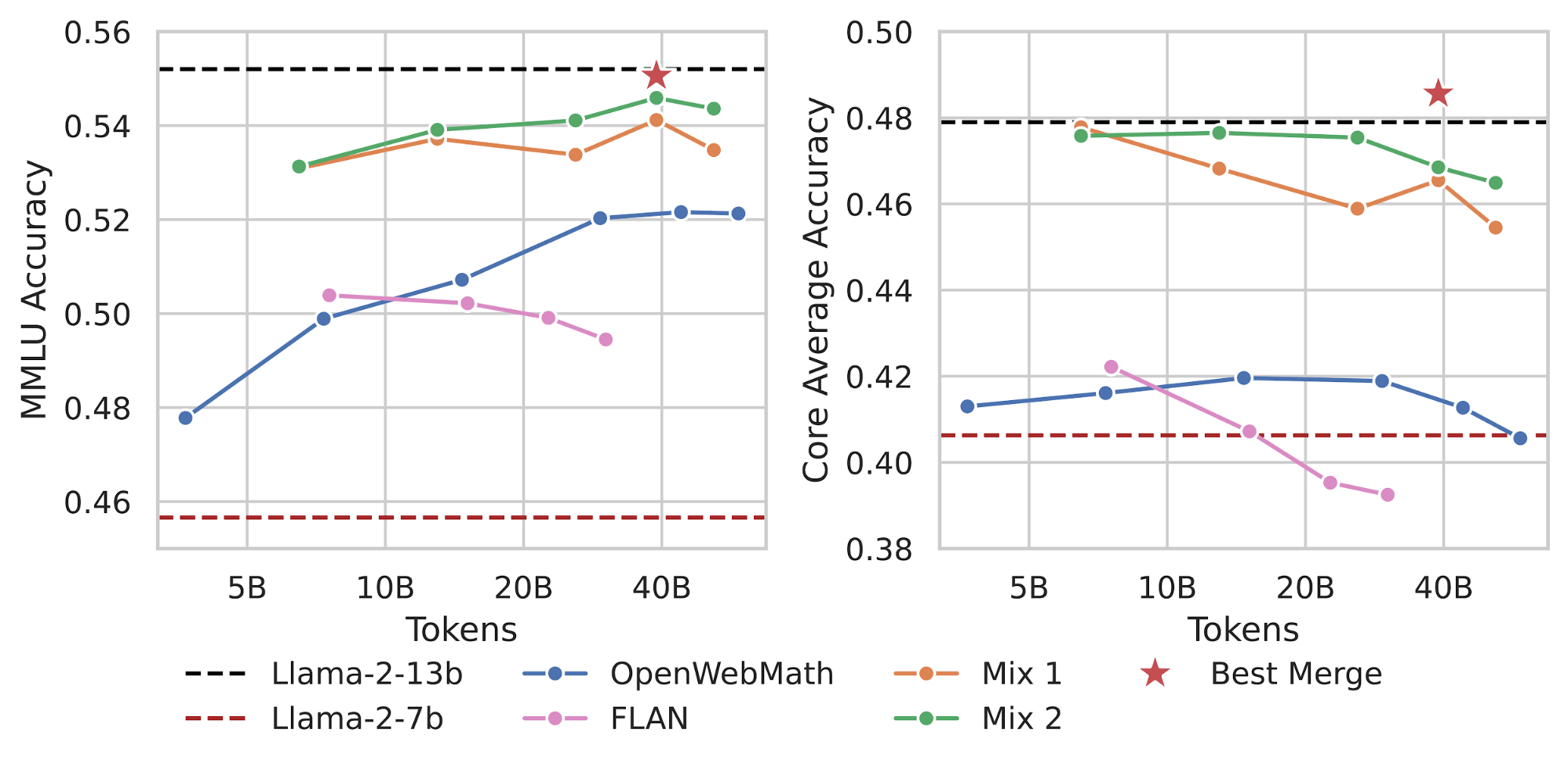
Figure 3 shows the duration sweep of the optimal learning rate for OpenWebMath and FLAN, the two datasets that resulted in MMLU improvement. The red horizontal dashed line is the performance of Llama-2-7B base, the model before training. The black horizontal dashed line is the performance of Llama-2-13B base, a model that is twice as big. Both datasets led to substantial improvements over Llama-2-7B base but had very different optimal durations. While one of our datasets led to improved performance at 8B tokens but worse performance with more training (pink line in Figure 2), the other dataset showed consistent performance improvements up to 40B tokens (blue line Figure 2). Additionally, monitoring our Core Average metric revealed that over-training on certain datasets could lead to forgetting.
Thus, we see running LR sweeps at the 1B to 10B token regime is a fast and effective way to identify which datasets enhance model performance. This allows us to remove ineffectual datasets and eventually mix the beneficial datasets and train them for longer periods, making CPT an efficient tool for identifying useful datasets.
Mixing Datasets for Better Performance
After identifying individual datasets that improve performance and their optimal training durations, we mixed them to achieve further improvements. We recommend a simple heuristic: mix them in the ratio of the number of tokens required for optimal performance for each dataset. For example, we found success mixing them in the ratio of 8:40, or 16% of the data comes from FLAN (pink) and 84% comes from OpenWebMath (blue).
This simple heuristic outperforms mixing datasets in a 1:1 ratio or merely concatenating them. With the new mixed dataset, we again swept the LR at 1B tokens. We then swept the training duration at the optimal learning rate. This resulted in our CPT model (orange line) at 40B tokens outperforming the Llama-2-7B base on both MMLU and Gauntlet Core Average, nearly matching the performance of the Llama-2-13B base.
Mitigating Forgetting with Model Soups
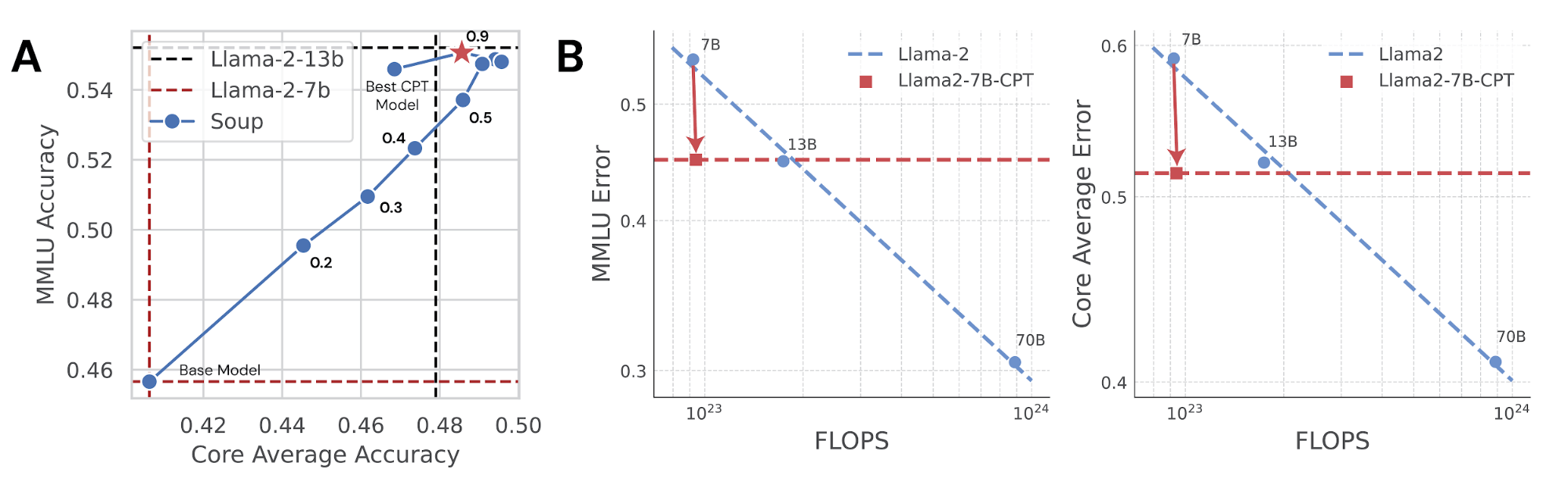
While the model trained for 40B tokens on our mix had the best performance on MMLU, it performed slightly worse on Core Average than models trained for a shorter duration. To mitigate forgetting, we used model souping: simply averaging the weights of two models that have the same architecture but are trained differently. We averaged the model trained for 40B tokens on the mixed dataset with Llama-2-7B base before CPT. This not only improved Core Average, reducing forgetting, but also enhanced performance on MMLU, resulting in our best model yet (red star in figure). In fact, this model matches or exceeds the performance of the Llama-2-13B base on both metrics.
Does Continued Pre-training Scale Well?
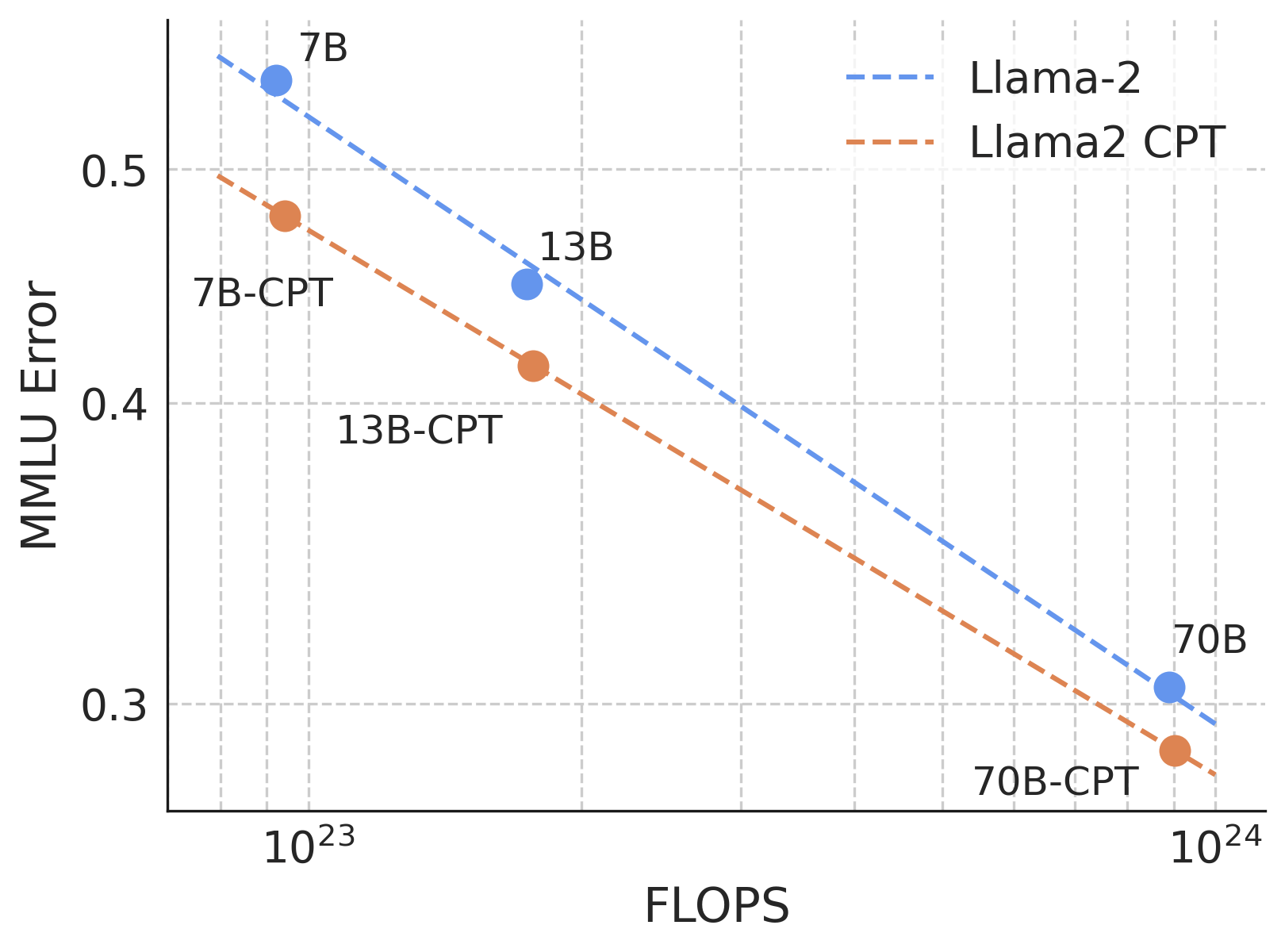
Finally, we consider how well CPT with OpenWebMath scales to models at larger FLOP scales. We repeat the learning rate and duration sweep with OpenWebMath performed for Llama-2-7B above, but now with Llama-2-13B and Llama-2-70B. As shown in Figure 4, we continue to see improvements at the 10^24 FLOP scale, and the scaling curve indicates that we could potentially see gains at even higher FLOPS. Each marker for the CPT runs represents the best MMLU performance following the learning rate and duration sweep.
Conclusion
In this blog post, we explored the process of Continued Pre-Training (CPT) to enhance a small LLM’s general knowledge performance to that of a larger model. We demonstrated how to effectively sweep hyperparameters, identify beneficial datasets, and mix datasets for improved performance. Additionally, we discussed strategies to mitigate forgetting through model souping. By following these guidelines, you can leverage CPT to quickly measure if different datasets are effective at teaching models new information as well as customize and enhance your LLMs efficiently, achieving remarkable performance improvements.
An important consideration is the success of CPT is likely to be dependent on the original pre-training data mix. For example, because OpenWebMath was released after the Llama-2 family, our continued pre-training introduced the model to a novel mix of high-quality mathematical data, and the results could potentially be altered if OpenWebMath was included in the pre-training corpus. Regardless, the results demonstrate the ability of CPT to adapt a model to novel data in a FLOP efficient manner.
[1] In this blog, reported scores are Gauntlet v0.2 core average. In a recent blog post Calibrating the Mosaic Evaluation Gauntlet, we discussed our process of building the Gauntlet v0.3 core average in which we removed several evals based on poor scaling with training FLOPS. The v0.2 and v0.3 scores will be similar but should not be directly compared.