![]()
Make R Programming on Big Data simpler With Databricks

Why Databricks + RStudio?
Increase productivity of R users
The seamless integration between Databricks and RStudio allows data scientists to use familiar tools and languages to run and execute R jobs on Databricks directly in RStudio IDE.
Simplify access to large data sets
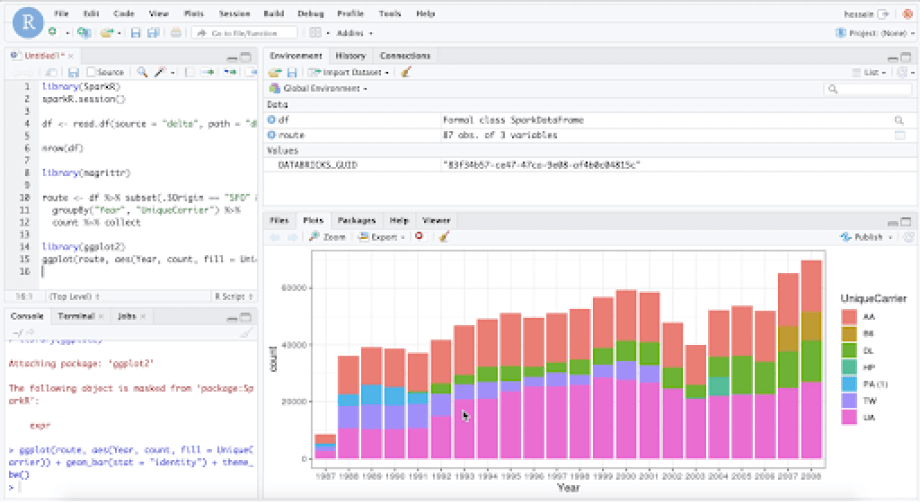
Unify datasets in Databricks for your R-based machine learning and AI projects with the ability to code in RStudio. Databricks provides scalable data processing with Delta Lake and optimized Apache Spark to clean, blend and join datasets in an open data format.
Enable distributed R computing at scale
Databricks supports R as a first-class language, offering unprecedented performance (up to 100x faster than Apache Spark) as well as the ability to auto-scale cloud-based clusters to handle the most demanding jobs, while keeping the total cost of ownership low.
RStudio and Databricks Integration
For data scientists looking at scaling out R-based computing to big data, Databricks provides a Unified Analytics Platform that is easy to setup and integrates with the most popular R tools and frameworks.
How it works
Access RStudio IDE on Databricks
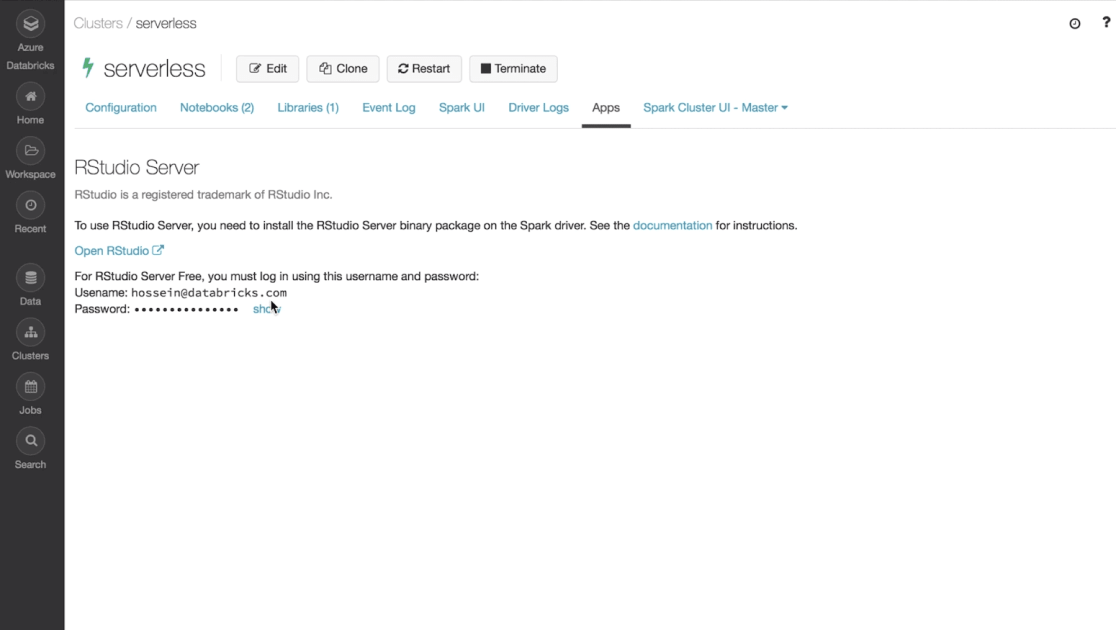
Install your desired RStudio Server version (open source or pro) on a Databricks cluster. Seamlessly use Apache Spark™ from RStudio IDE inside Databricks using both SparkR or sparklyr.
Prepare high-quality data sets for analyses
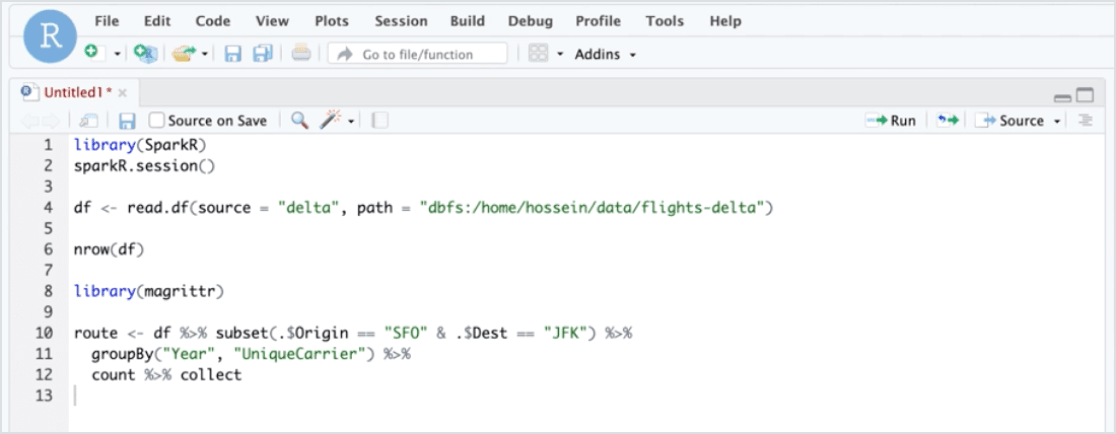
Clean, blend and join data sets using RStudio’s familiar interface and tools without the need for cluster management. Access data from Delta tables or external data sources using Apache Spark.
Interactively develop and build Shiny applications
Develop and test Shiny applications inside a hosted RStudio Server using a high-bandwidth connection to a powerful Apache Spark cluster.
Use cases
Inventory optimization analytics
Forecast warehouse stocking levels using R and Databricks to optimize safety stock levels.
Genomic sequencing
Enable efficient cloud processing to turn population-scale genetic data into meaningful insights.
Predict portfolio performance
Use pre-built functions for performance and risk management calculations of large-scale portfolio data.
Ready to get started?