Azure Databricks
Azure Databricks is a first-party solution jointly developed by Databricks and Microsoft. Built on lakehouse architecture, it unifies data, analytics and AI on Azure. Part of the Databricks Data Intelligence Platform, Azure Databricks enables organizations to simplify architectures, accelerate time to insight and build generative AI solutions — all with a seamless, native Azure experience.

Azure Databricks is fully integrated into the Azure ecosystem, offering native connectivity to services like Power BI, Azure OpenAI and Microsoft Purview. It brings the openness of lakehouse architecture to Azure, helping customers securely operationalize AI on their existing Microsoft investments.

Azure Databricks
Unlock the potential of your data with this Introduction to Azure Databricks step-by-step training. This comprehensive training explores the Databricks Platform, covering everything from production-scale AI and LLM training to serverless data warehousing and unified governance with Unity Catalog. Learn to simplify complex ETL processes and accelerate your organization's AI initiatives using a unified lakehouse architecture designed for performance and regulatory compliance.
Unified
Unify all your data, analytics and AI
on one open platform.
Open
Built on open standards to ensure
interoperability and avoid vendor lock-in.
Collaborative
Empower all data teams to securely build
and share insights together.
Why Azure Databricks?
12x better price/performance for SQL workloads
Accelerated performance for SQL workloads with Photon and AI-driven query optimization. Optimized runtimes for Spark, Python and SQL power all workloads, from ETL to BI to AI.
Enterprise scale
Trusted by over 10,000 global organizations, including more than 60% of the Fortune 500, to run data and AI workloads reliably at scale across 44+ Azure regions.
Native Azure experience
Deploy in one click through Azure Portal. Benefit from native identity and governance via Entra ID, Unity Catalog and Microsoft Purview. Empower teams with collaborative notebooks, SQL and visual workflows to accelerate data and AI projects.
Industry use cases
Discover how industry leaders in financial services, retail and healthcare are transforming with the Databricks Data Intelligence Platform on Azure.

HSBC
Built a digital payment platform using Azure Databricks.
Santander
Accelerates real-time analytics and compliance with Azure Databricks.
Banco Bradesco
Uses Azure Databricks and Databricks Assistant to speed up code development and expand data access across teams.
Navy Federal Credit Union
Scales fraud detection and AI with Azure Databricks.

Join an Azure Databricks event
Learn how organizations are transforming with the Databricks Data Intelligence Platform on Azure. Meet product experts, Microsoft partners and customers at upcoming events and workshops.
Optimized for Azure
Seamlessly integrate Azure data stores and services with specialized connectors for fast data access and simplified management across your environment. Azure-native integrations ensure easy setup of Unity Catalog, security and compliance, as well as the ability to manage and operationalize all your Azure data.
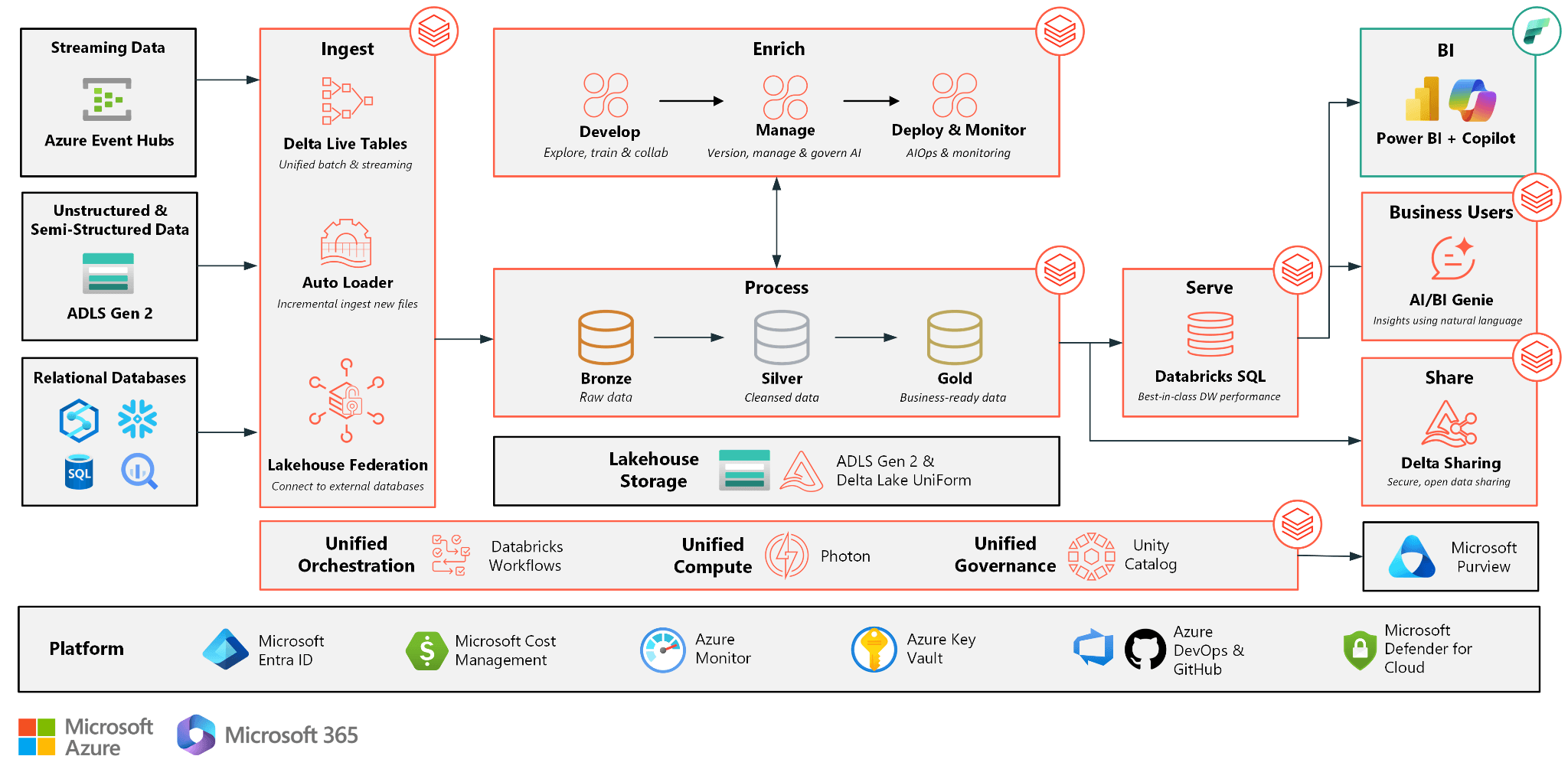
Featured integrations