Built for open, intelligent data storage
Choose your storage location and format, with full ownership and portability of your data.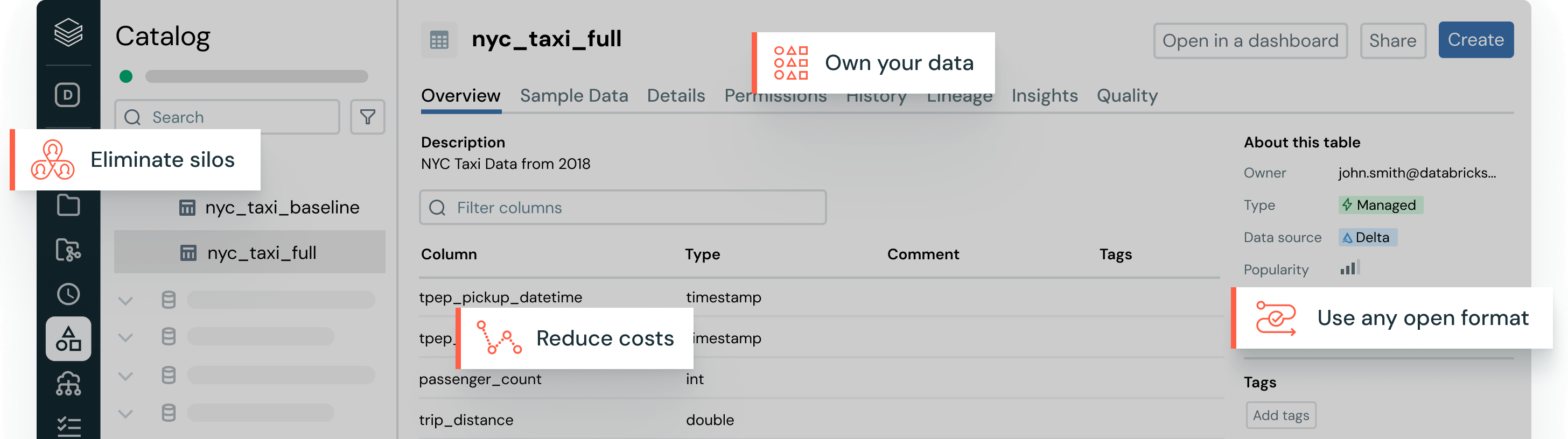
TOP TEAMS SUCCEED WITH DATA INTELLIGENCE
Lakehouse storage that’s flexible and fast
Eliminate data management headaches with open table formats, centralized governance and automatic data optimizations.Compatible formats
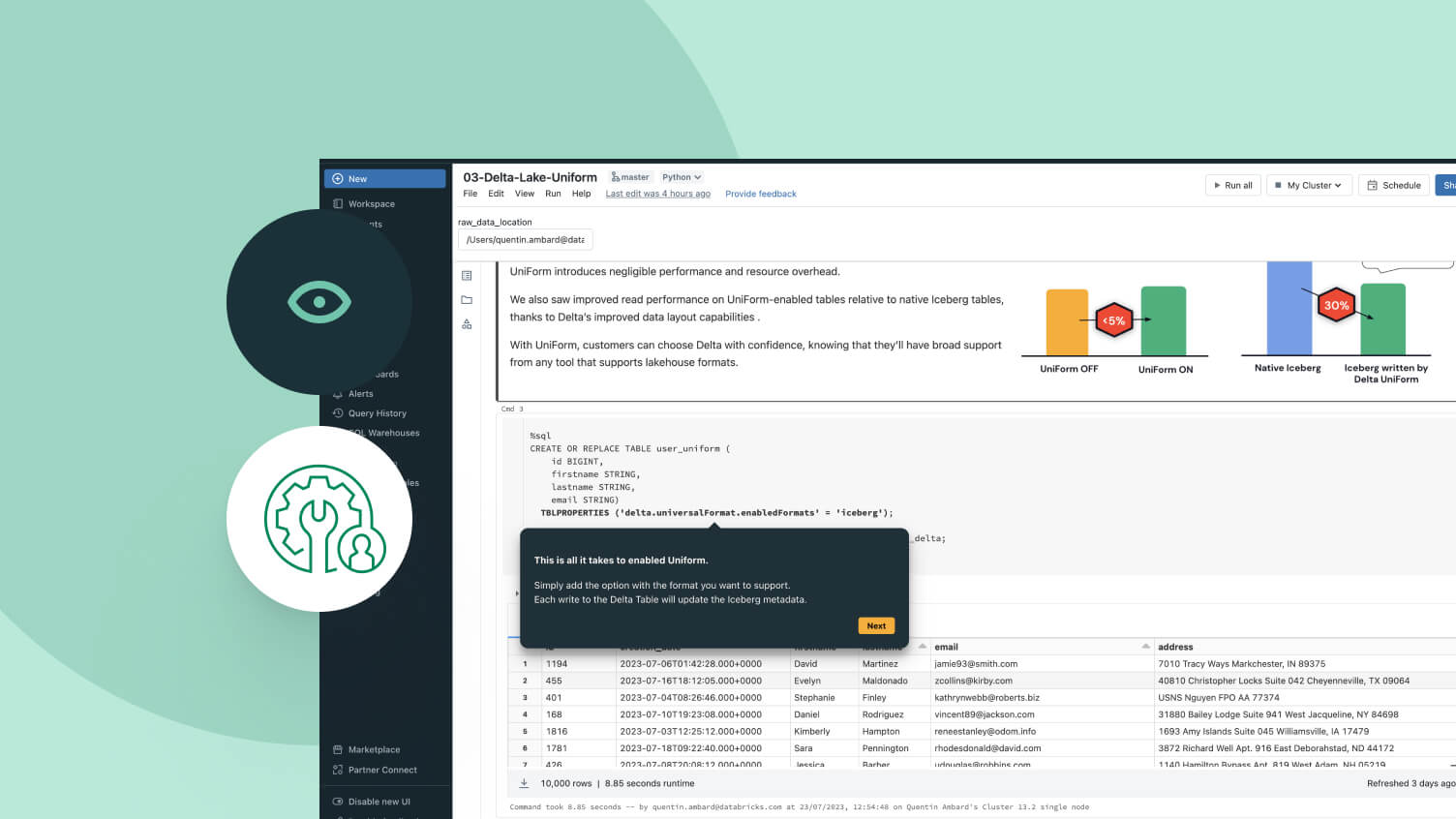
A single copy of source data in Delta Lake or Apache Iceberg™ that can be accessed by any engine.
Unified governance
A single catalog for data discovery and governance, across your data and AI assets.
AI-driven performance
AI-powered models autonomously optimize and maintain data for speed and low cost.
Your data, your way
Choose the storage location and open format that works for you. Keep your data portable, without vendor lock-in.Best-in-class read and write performance for Delta Lake and Apache Iceberg™ tables, out of the box, with storage optimizations not available in any other lakehouse.
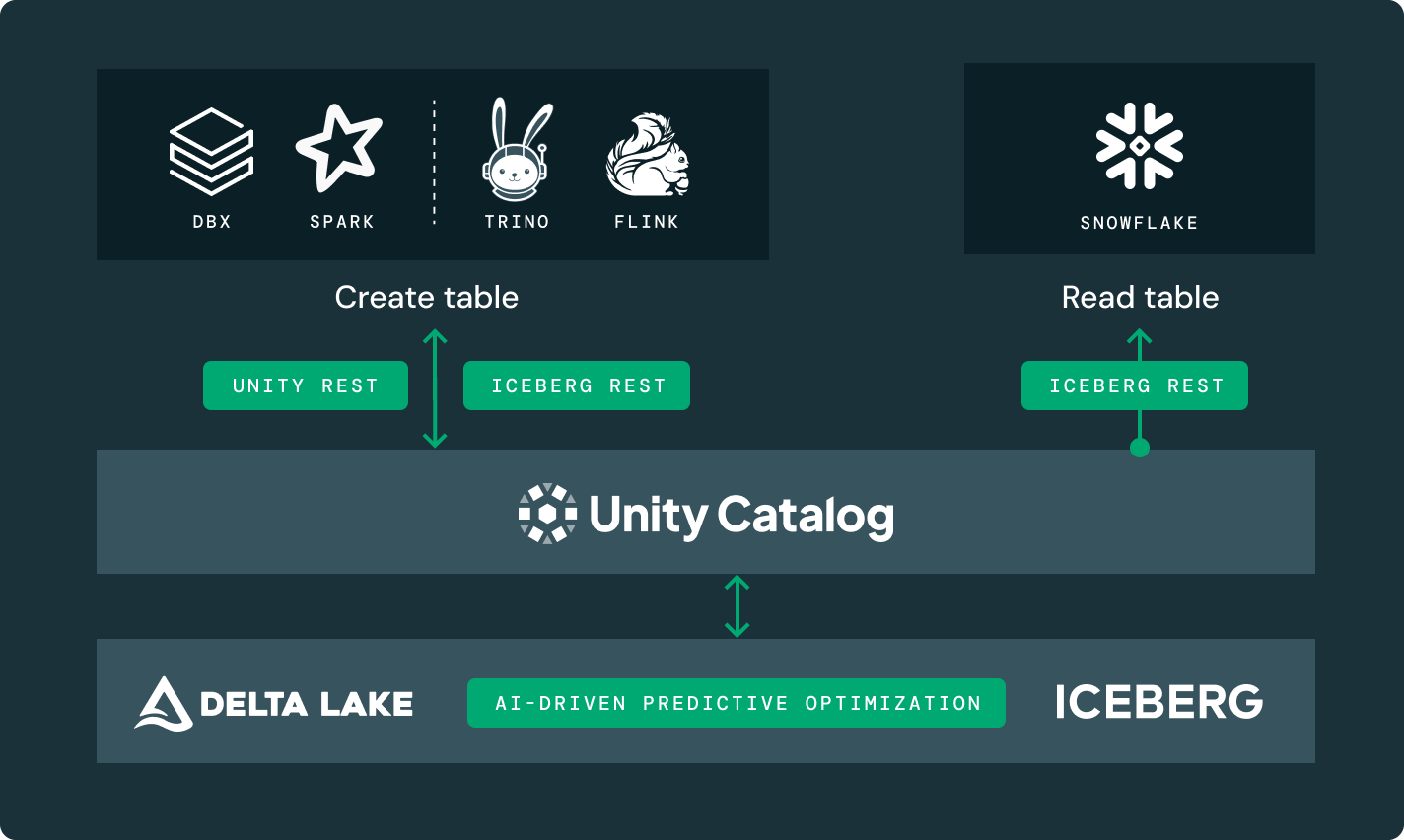
Access tables that are managed by external catalogs like Glue, HMS and Snowflake Horizon and leverage advanced Unity Catalog features like fine-grained access controls.
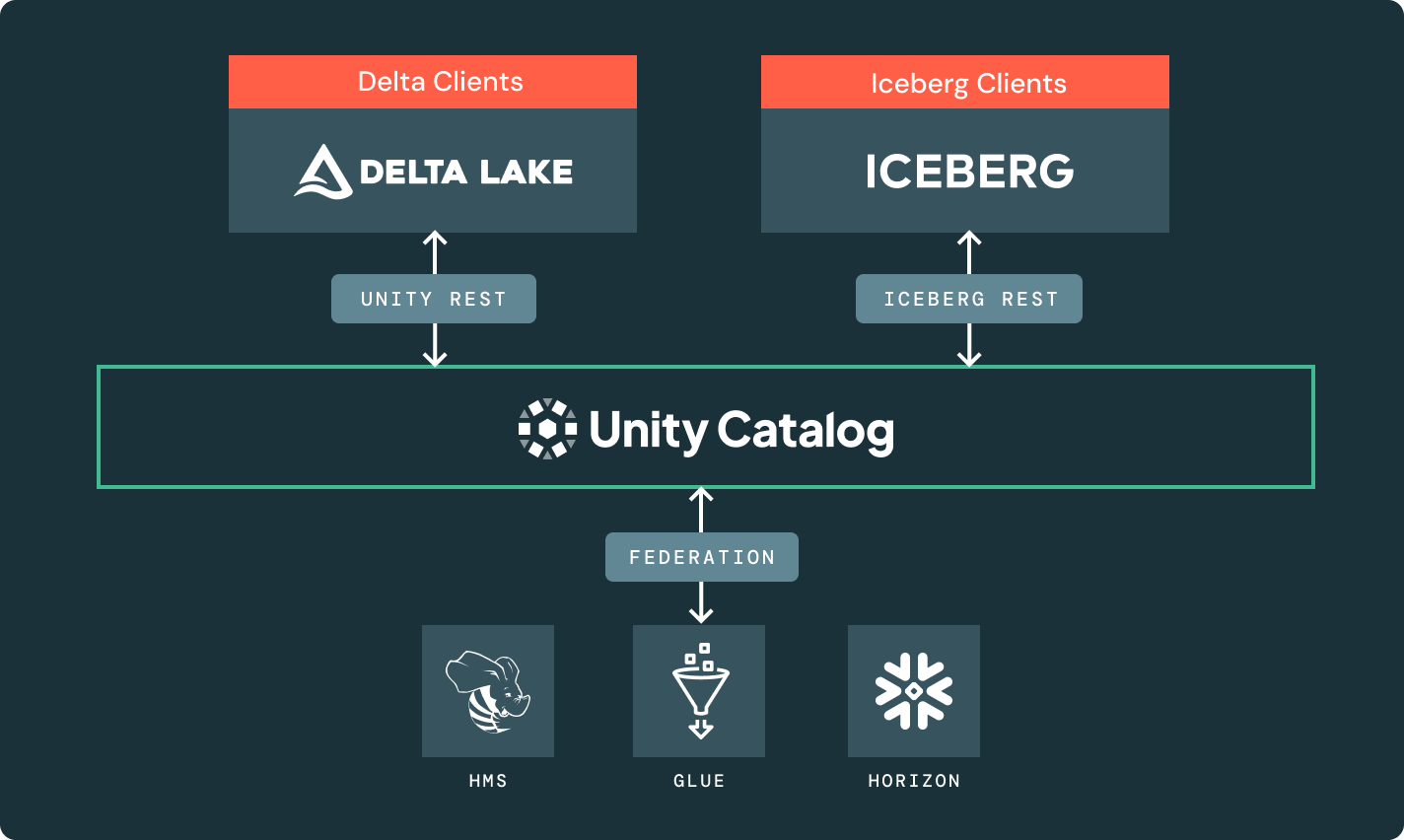
The Unity REST and Iceberg REST Catalog APIs unlock the entire lakehouse ecosystem, across formats and engines.
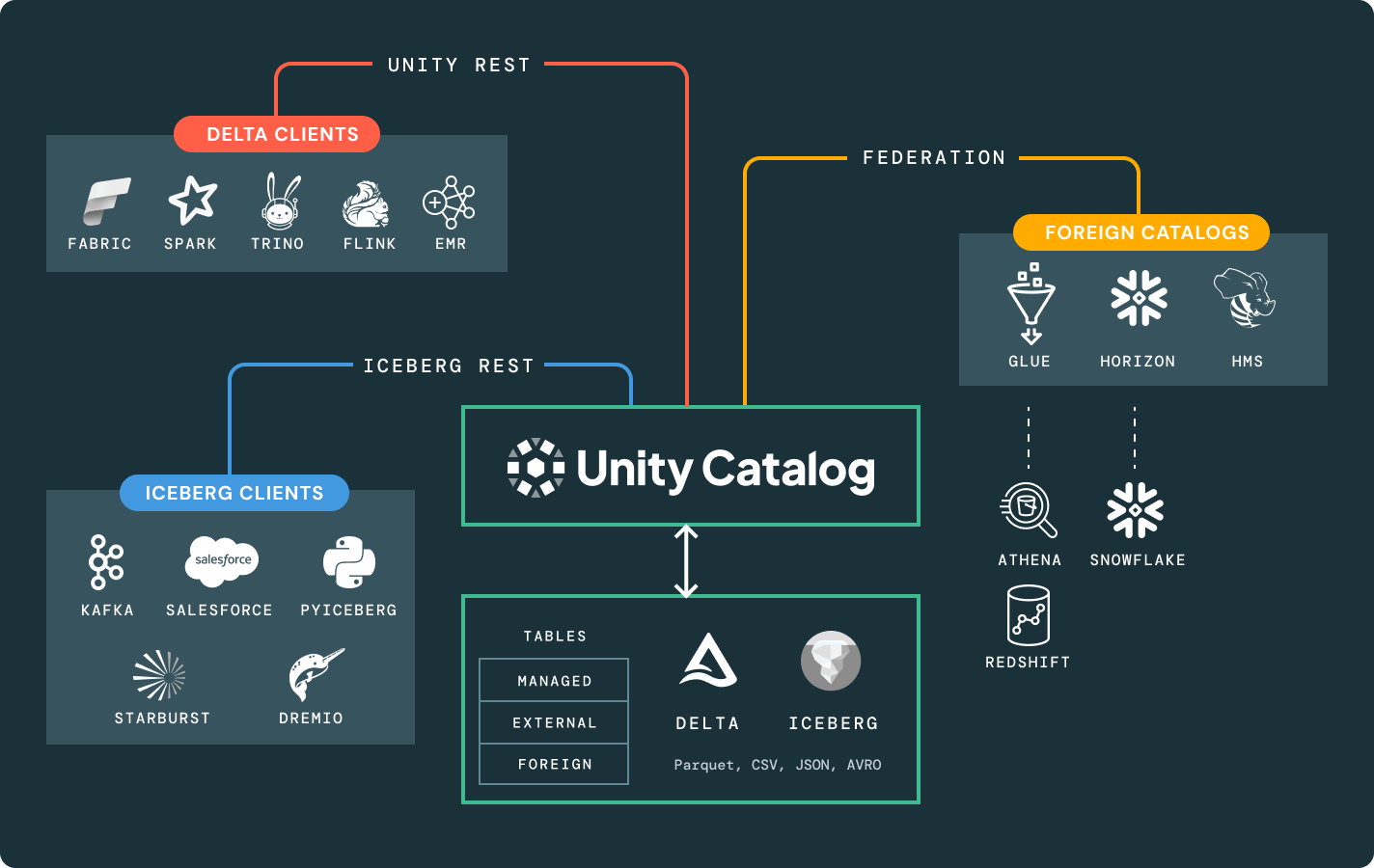
More features
For all your analytics and AI workloads

Build and manage reliable data pipelines
Managed tables act as both batch tables and a streaming source and sink. Streaming data ingest, batch historic backfill and interactive queries all work out of the box and directly integrate with Spark Structured Streaming.
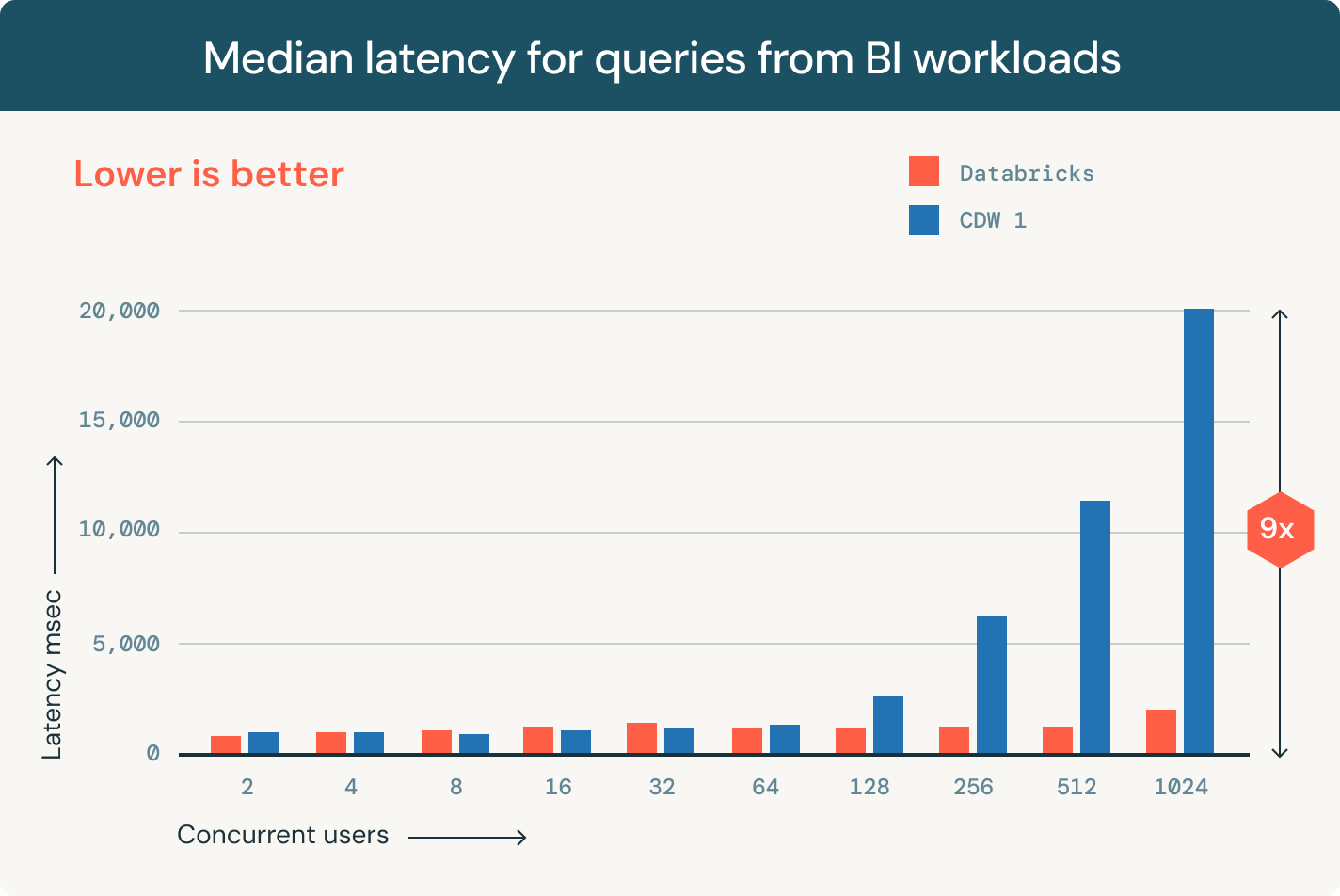
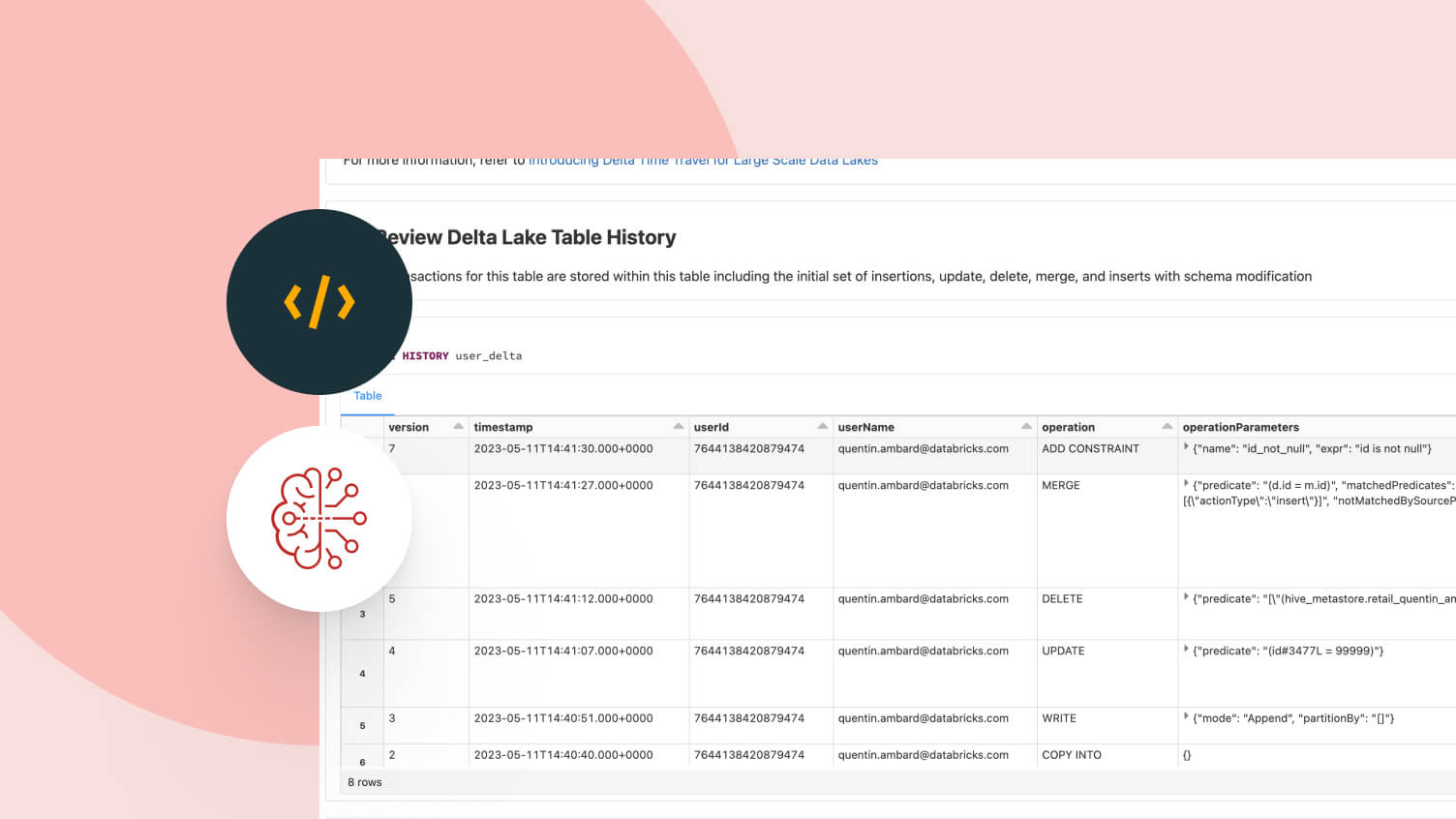
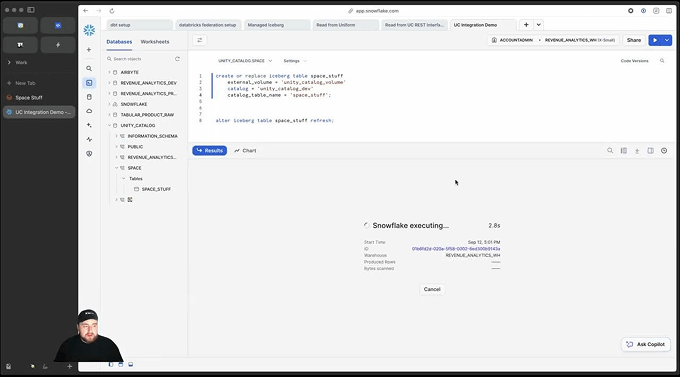

Discover, govern and share your data and AI assets
Learn more about how the Databricks Data Intelligence Platform empowers your data teams across all your data and AI workloads.
Unity Catalog
The industry’s only unified and open governance solution for data and AI, built into the Databricks Data Intelligence Platform.

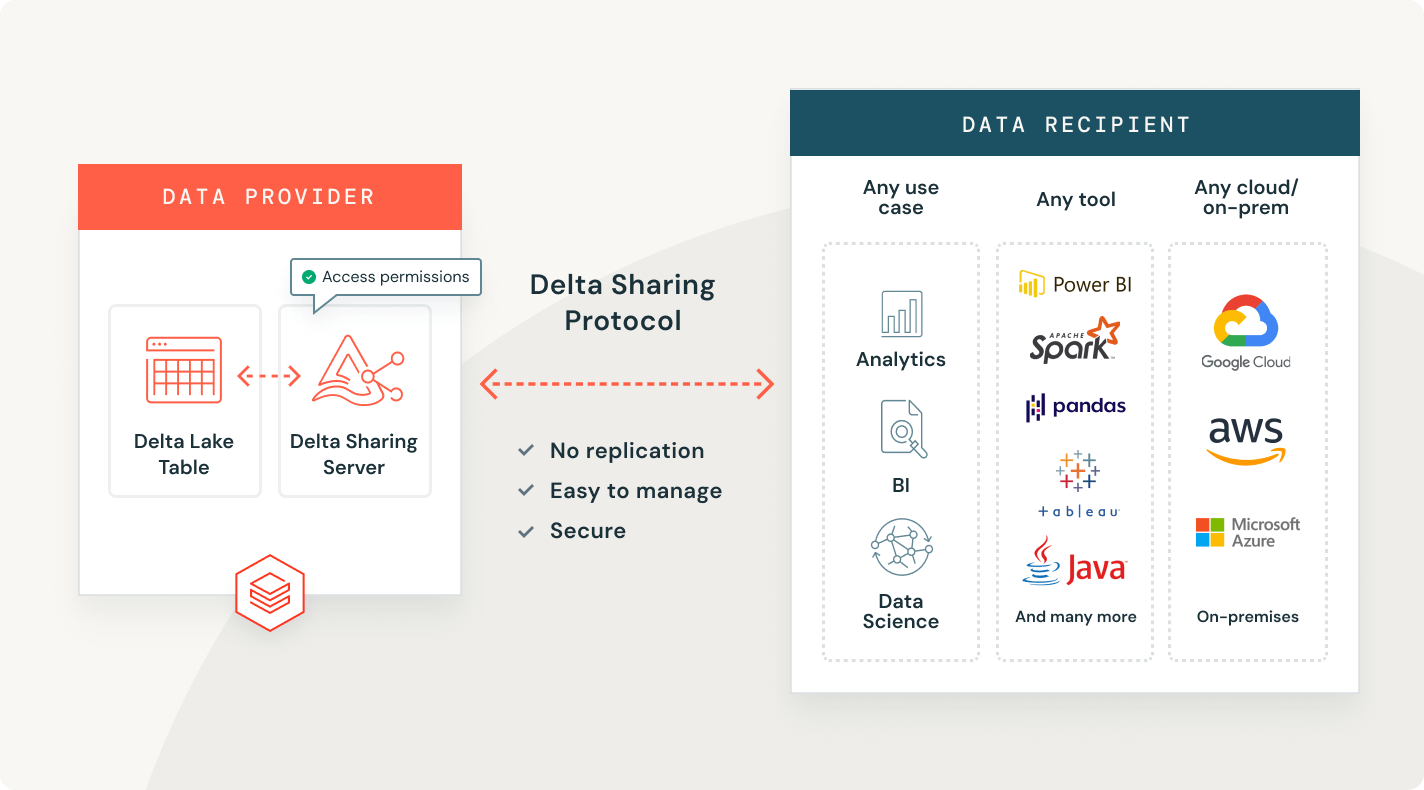
Delta Sharing
The first open source approach to data sharing across data, analytics and AI. Securely share live data across platforms, clouds and regions.

Data Intelligence Platform
Explore the full range of tools available on the Databricks Data Intelligence Platform to seamlessly integrate data and AI across your organization.
Learn more




Lakehouse storage FAQ
Ready to become a data + AI company?
Take the first steps in your transformation