Simplify the Machine Learning Lifecycle
Shift from organizational and technological silos to an open and unified platform for the full data and ML lifecycle

Building ML models is hard. Moving them into production is harder. Maintaining data quality and model accuracy over time are just a few of the challenges. Databricks uniquely streamlines ML development, from data preparation to model training and deployment, at scale.
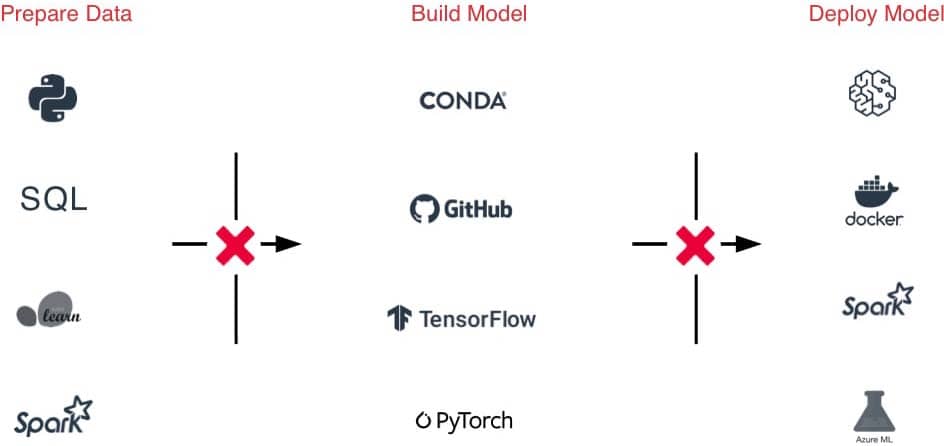
The Challenge
The sheer amount of diversity of ML frameworks makes it hard to manage ML environments
Difficult handoffs between teams due to disparate tools and processes, from data prep, to experimentation, and production
Hard to track experiments, models, dependencies and artifacts makes it hard to reproduce results
Security & compliance risks
The Solution
One-click access to ready-to-use, optimized and scalable ML environments across the lifecycle
One platform for data ingest, featurization, model building, tuning, and productionization simplifies handoffs
Automatically track experiments, code, results and artifacts and manage models in one central hub
Meet compliance needs with fine-grained access control, data lineage, and versioning.
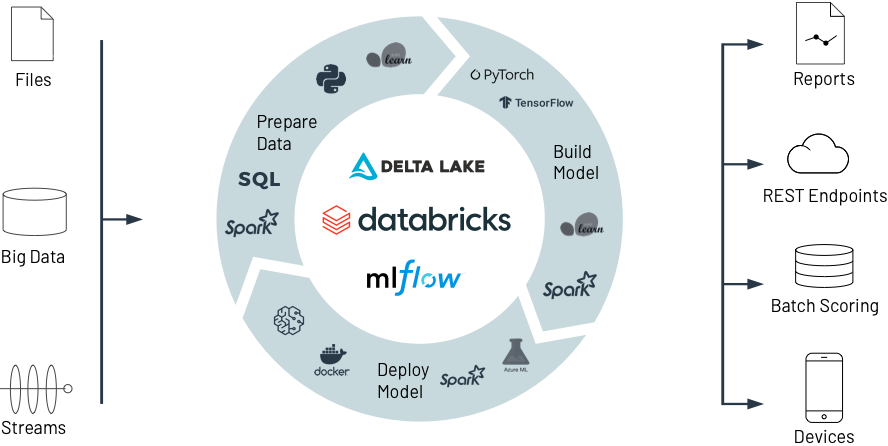
Databricks for Machine Learning
See how Databricks helps collaboratively prep data, build, deploy, and manage state of the art ML models, from experimentation to production, at unprecedented scale.
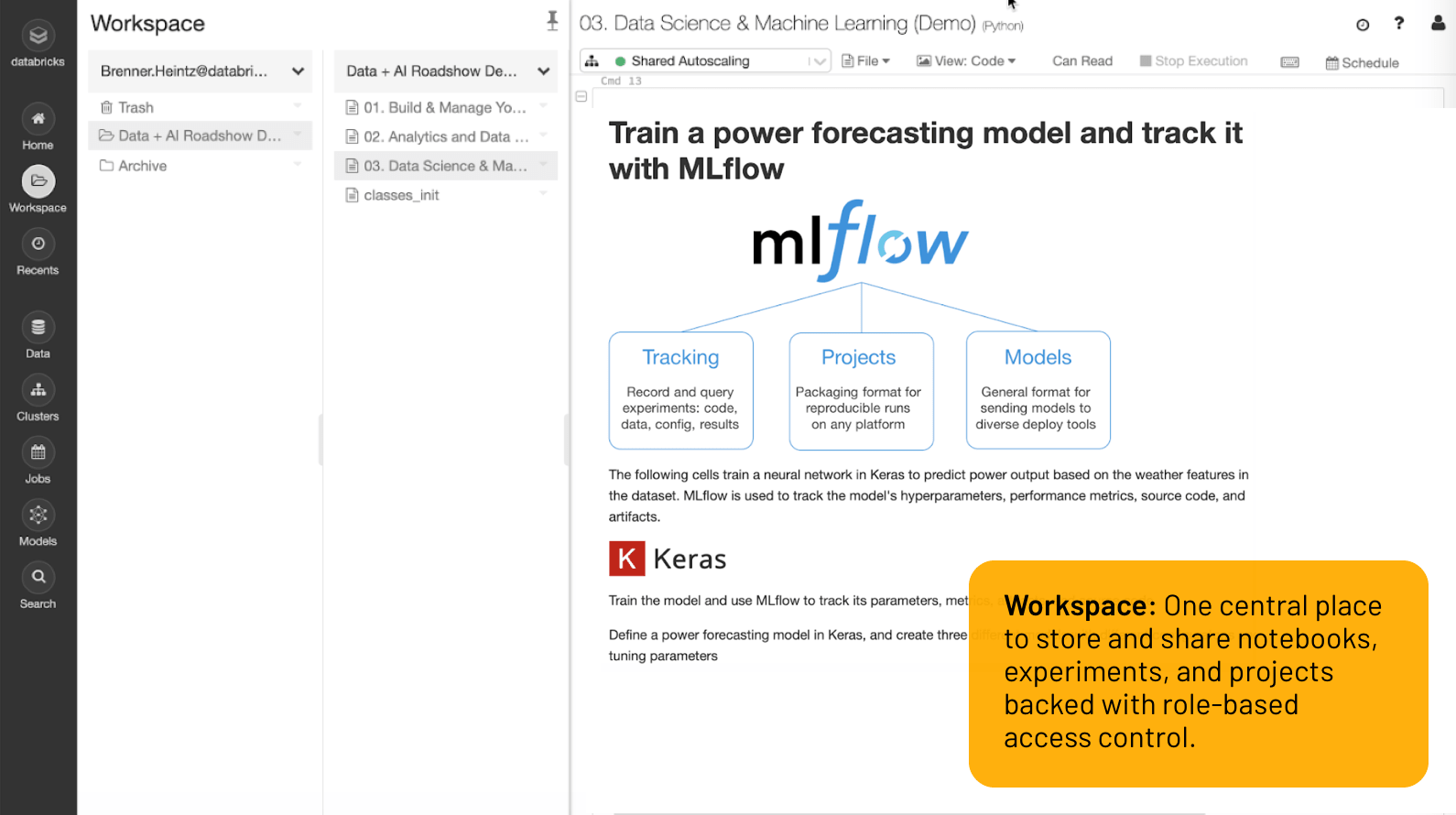
Workspace
One central place to store and share notebooks, experiments, and projects backed with role-based access control.
From experimentation to production ML at unmatched scale
Best in class developer environment
Everything you need to get the job done is one click away in the Workspace: data sets, ML environments, notebooks, files, experiments, models, are all securely available in one place.
Collaborative notebooks with multi-language support (Python, R, Scala, SQL) make it easier to work as a team while co-authoring, Git integration, versioning, role-based access control, and more, help you stay in control. Or simply use familiar tools like Jupyter Lab, PyCharm, IntelliJ, RStudio with Databricks to benefit from limitless data storage and compute.
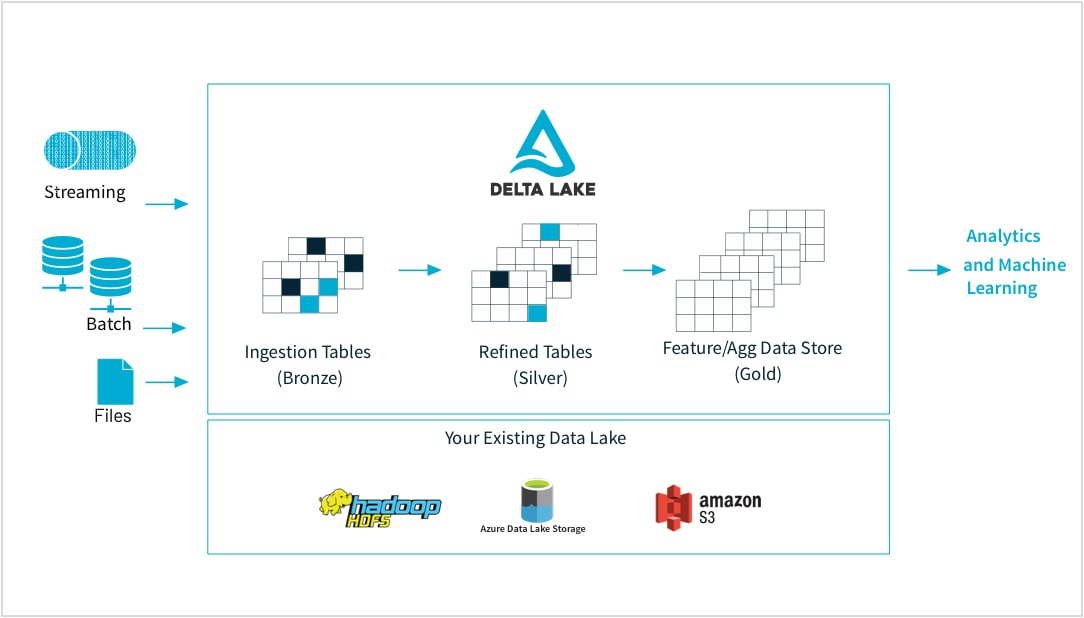
From raw data to high-quality feature store
Machine learning practitioners train models on a large variety of data forms and formats: small or large data sets, DataFrames, text, images, batch or streaming. All require specific pipelines and transformations
Databricks lets you ingest raw data from virtually any source, merge batch and streaming data, schedule transformations, version tables, and perform quality checks to make sure data is pristine and ready for analytics for the rest of the organization. So now you can seamlessly and reliably work on any data, CSV files or massive data lake ingests, based on your needs.

The best place to run scikit-learn, TensorFlow, PyTorch, and more…
ML frameworks are evolving at a frenetic pace making it challenging to maintain ML environments. The Databricks ML Runtime provides ready to use and optimized ML environments including the most popular ML frameworks (scikit-learn, TensorFlow, etc…) and Conda support.
Built-in AutoML like hyperparameter tuning help get to results faster, and simplified scaling helps you go from small to big data effortlessly so you don’t have to be limited by how much compute is available to you anymore. For example, train deep learning models faster by distributing compute across your clusters with HorovodRunner and squeeze more performance out of each GPU in your cluster by running the CUDA-optimized version of TensorFlow.
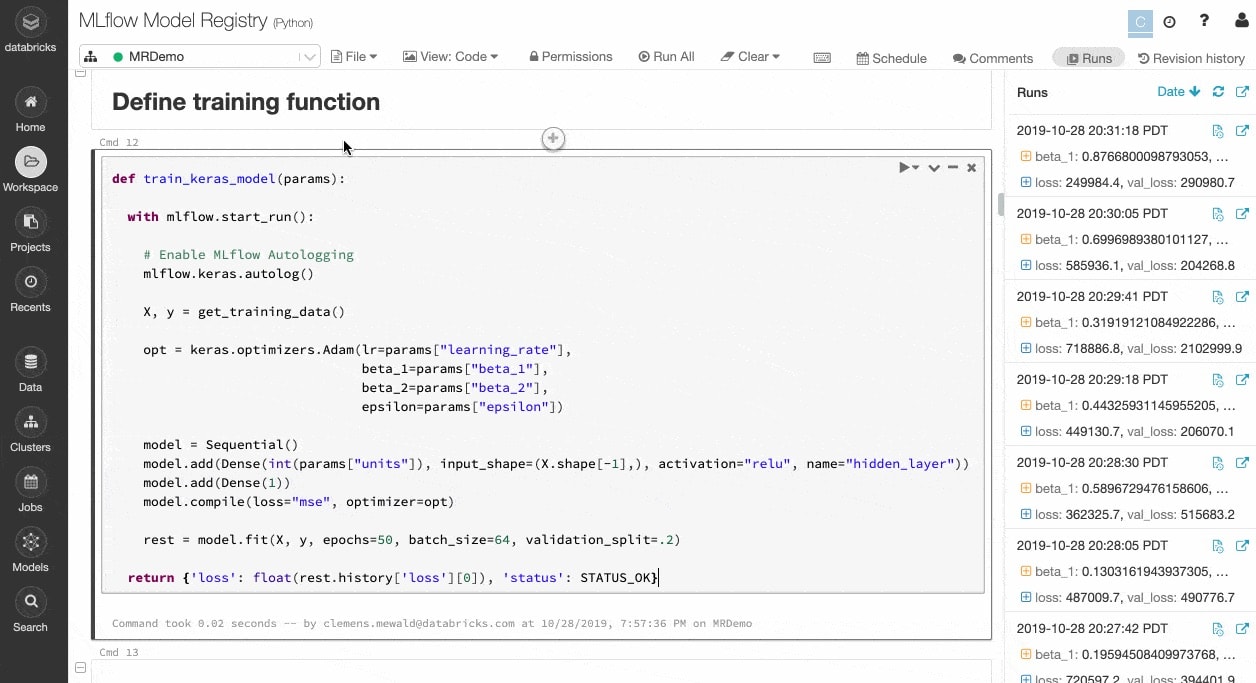
Track experiments and artifacts to reproduce runs later
ML algorithms have dozens of configurable parameters, and whether working alone or as a team, it is difficult to track which parameters, code, and data went into each experiment to produce a model.
MLflow automatically keeps track of your experiments along with artifacts like data, code, parameters and results for each training run from within notebooks. So you can quickly see at a glance previous runs, compare results, and revert to a previous version of your code as needed. Once you have identified the best version of a model for production, register it in a central repository to submit it for deployment and simplify handoffs.
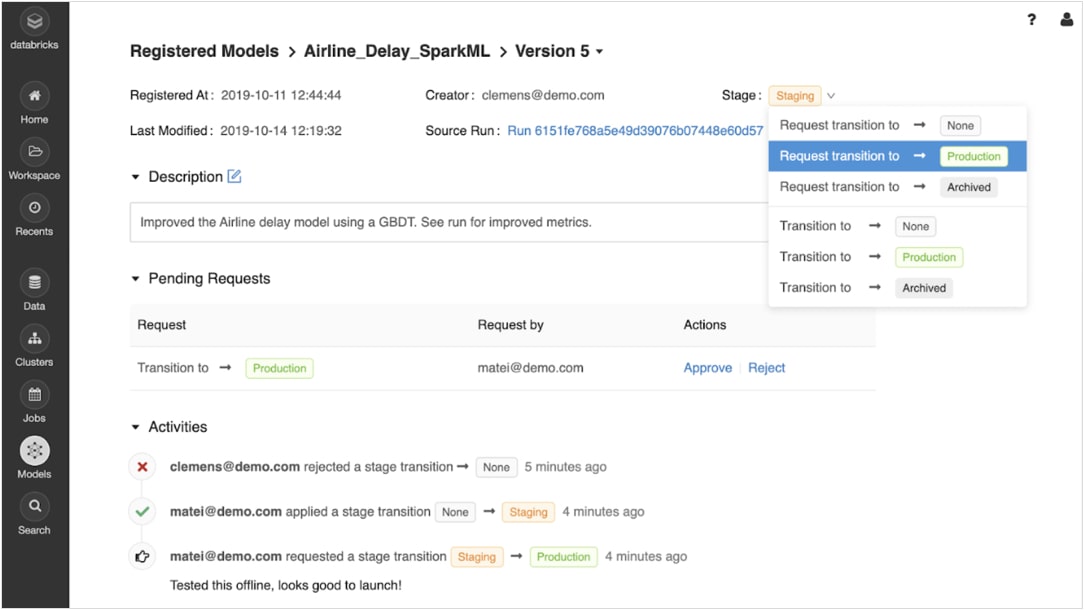
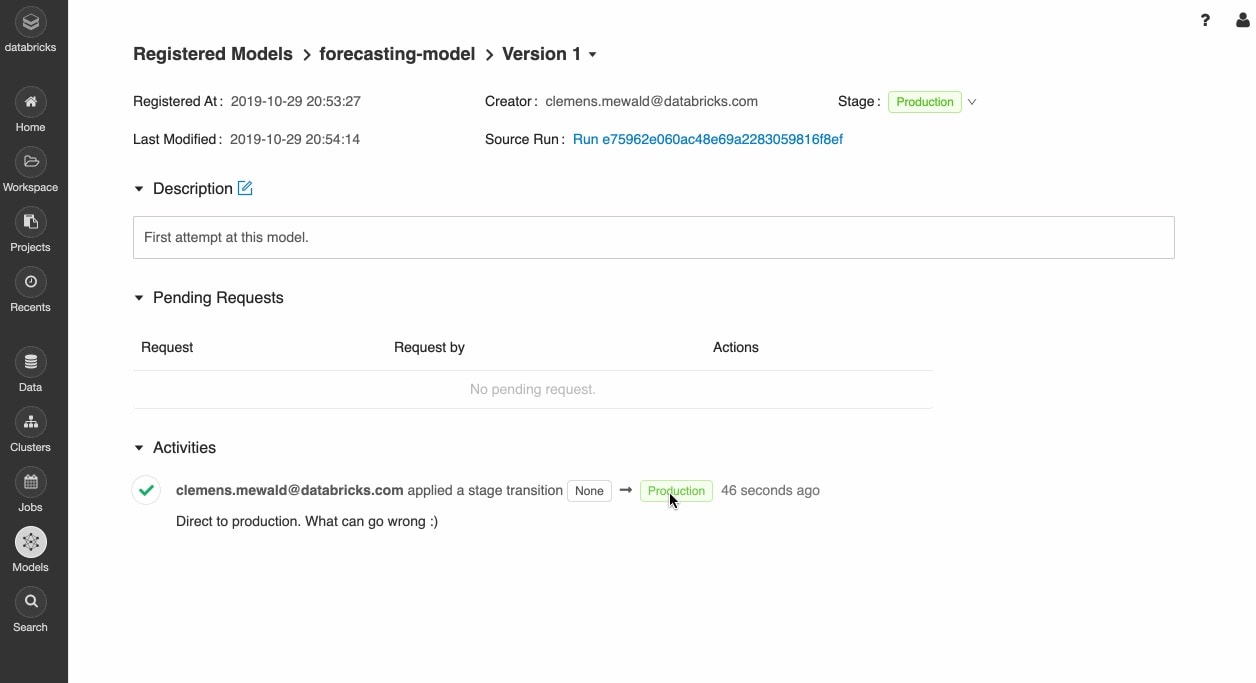
Confidently move from prototyping to production
Once trained models are registered, you can collaboratively manage them through their lifecycle with the MLflow model registry.
Models can be versioned and moved through various stages, like experimentation, staging, production and archived. Stakeholders can comment and submit requests to change stage. All of the lifecycle management integrates with approval and governance workflows and role-based access controls.
Deploy models anywhere
Quickly deploy production models for batch inference on Apache Spark™, or as REST APIs using built-in integration with Docker containers, Azure ML, and Amazon SageMaker.
Operationalize production models using jobs scheduler and auto-managed clusters to scale as needed based on business needs.
Quickly push the latest versions of your models to production and monitor model drift with Delta Lake and MLflow.
Resources
Report

eBook

eBook

Ready to get started?