Application Spotlight: Pentaho
This post is guest authored by our friends at Pentaho after having their data integration and analytics platform “Certified on Apache Spark.”
One of Pentaho’s great passions is to empower organizations to take advantage of amazing innovations in Big Data to solve new challenges using the existing skill sets they have in their organizations today. Our Pentaho Labs prototyping and innovation efforts around natively integrating data engineering and analytics with Big Data platforms like Hadoop and Storm have already led dozens of customers to deploy next-generation Big Data solutions. Examples of these solutions include optimizing data warehousing architectures, leveraging Hadoop as a cost effective data refinery, and performing advanced analytics on diverse data sources to achieve a broader 360-degree view of customers.
Not since the early days of Hadoop have we seen so much excitement around a new Big Data technology as we see right now with Apache Spark. Spark is a Hadoop-compatible computing system that makes big data analysis drastically faster, through in-memory computation, and simpler to write, through easy APIs in Java, Scala and Python. With the second annual Spark Summit taking place this week in San Francisco, I wanted to share some of the early proof-of-concept work Pentaho Labs and our partners over at Databricks are collaborating on to integrate Pentaho and Spark for delivering high performance, Big Data Analytics solutions.
Big Data Integration on Spark
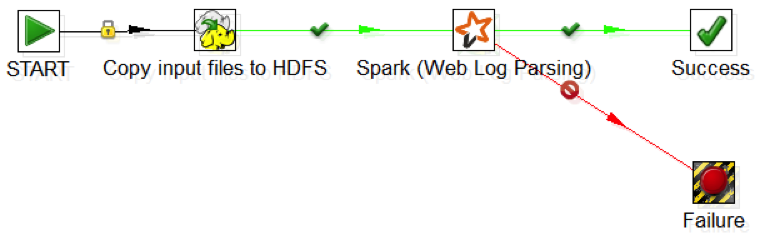
At the core of Pentaho Data Integration (PDI) is a portable ‘data machine’ for ETL which today can be deployed as a stand-alone Pentaho cluster or inside your Hadoop cluster though MapReduce and YARN. The Pentaho Labs team is now taking this same concept and working on the ability to deploy inside Spark for even faster Big Data ETL processing. The potential benefit for ETL designers is the ability to design, test and tune ETL jobs in PDI’s easy-to-use graphical design environment, and then run them at scale on Spark. This dramatically lowers the skill sets required, increases productivity, and reduces maintenance costs when to taking advantage of Spark for Big Data Integration.
Advanced Analytics on Spark
Last year Pentaho Labs introduced a distributed version of Weka, Pentaho’s machine learning and data mining platform. The goal was to develop a platform-independent approach to using Weka with very large data sets by taking advantage of distributed environments like Hadoop and Spark. Our first pilot implementation proved out this architecture by enabling parallel, in-cluster model training with Hadoop.
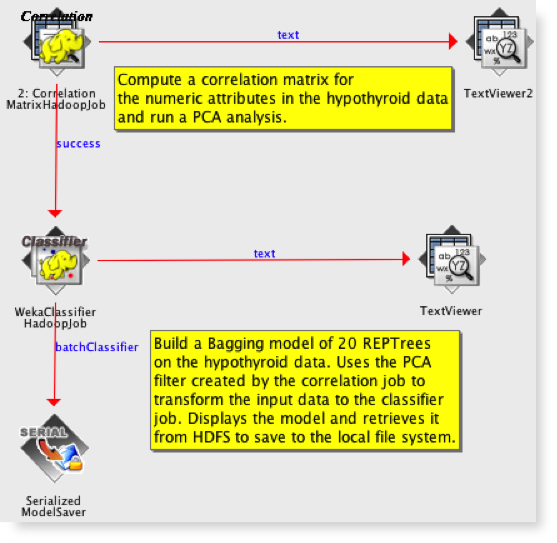
We are now working on a similar level of integration with Spark that includes data profiling and evaluating classification and regression algorithms in Spark. The early feedback from Pentaho Labs confirms that developing solutions on Spark is faster and easier than with MapReduce. In just a couple weeks of development, we have demonstrated a proof-of-concept to perform in-cluster Canopy clustering and are very close to having k-means++ working in Spark as well!
Next up: Exploring Data Science Pack Integration with MLlib
MLlib is already one of the most popular technologies for performing advanced analytics on Big Data. By integrating Pentaho Data Integration with Spark and MLlib, Data Scientists will benefit by having an easy-to-use environment (PDI) to prepare data for use in MLlib-based solutions. Furthermore, this integration will make it easier for IT to operationalize the work of the Data Science team by orchestrating the entire end-to-end flow from data acquisition, to data preparation, to execution of MLlib-based jobs to sharing the results, all in one simple PDI Job flow. To get a sense for how this integration might work, I encourage you to look at a similar integration with R we recently launched as part of the Data Science Pack for Pentaho Business Analytics 5.1.
Experiment Today with Pentaho and Spark!
You can experiment with Pentaho and Spark today for both ETL and Reporting. In conjunction with our partners at Databricks, we recently developed prototypes for the following use cases combining Pentaho and Spark*:
- Reading data from Spark as part of an ETL workflow by using Pentaho Data Integration’s Table Input step with Apache Shark (Hive SQL layer runs on Spark)
- Reporting on Spark data using Pentaho Reporting against Apache Shark
We are excited about this first step in what we both hope to be a collaborative journey towards deeper integration.
Jake Cornelius Sr. Vice President, Product Management Pentaho
* Note that these Databricks integrations constitute a proof-of-concept and are not currently supported for Pentaho customers.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.