Databricks: Making Big Data Easy
by Ion Stoica
Our vision at Databricks is to make big data easy so that we enable every organization to turn its data into value. At Spark Summit 2014, we were very excited to unveil Databricks, our first product towards fulfilling this vision.
In this post, I'll briefly go over the challenges that data scientists and data engineers face today when working with big data, and then show how Databricks addresses these challenges.
Today's Big Data Challenges
While the promise of big data to improve businesses, save lives, and advance science is becoming more and more real, analyzing and processing data remains as hard as ever. Software engineers, data engineers, data scientists at both small and large organizations continue to struggle with setting up and maintaining clusters, dealing with a zoo of systems, which are not only hard to integrate but also hard to use.
Set-up and maintain clusters
When an organization starts a big data initiative, typically, the first step is setting up a Hadoop cluster. Unfortunately, this is hard. Today it may take 6-9 months just to set up a cluster on premise. Even if the organization already has an on premise cluster, it may take 2-3 months to get a few more servers for a new big data project.
Integrate a zoo of systems
Once a cluster is in place, the next step is building a data pipeline. As shown in Figure 1, a typical data pipeline based on Hadoop includes ETL, (interactive) data exploration, building dashboards and reports, advanced analytics, and data products, such as a recommendation system.
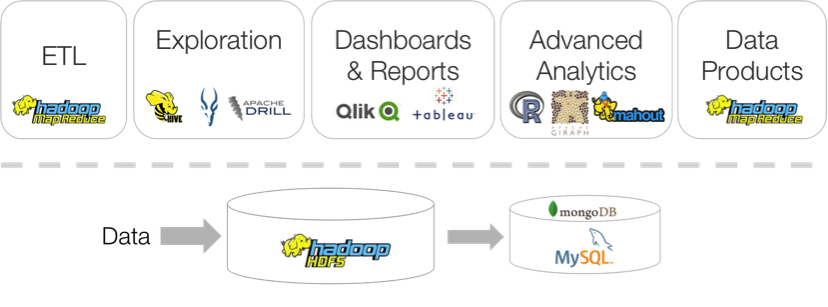
Figure 1: Typical big data pipeline.
Unfortunately, implementing such a data pipeline is very hard, as it requires stitching together a hodgepodge of disparate, complex systems, including batch processing systems (e.g., Hadoop MR), query engines (e.g., Hive, Impala, Apache Drill), business intelligence tools (e.g., Qlik, Tableau), and systems providing support for machine learning and graph-based algorithms (e.g., Giraph, GraphLab, Mahout, R).
Hard to use systems
Unfortunately, even after setting up the pipeline, the systems themselves remain hard to use. Different systems expose different APIs and programming languages (e.g., Java, Clojure, Scala, Python, R), and, at best, they provide a shell interface. Furthermore, performing advanced analytics is hard, and building data applications is even harder.
Databricks
Our goal at Databricks is to address all these challenges. To achieve this goal we have introduced Databricks (Figure 2) an end-to-end platform for data analysis and processing that we believe will make big data easier to use than ever before.

Figure 2: Databricks Cloud
Databricks is built around Apache Spark and consists of two additional components: a hosted platform (Databricks Platform) and a workspace (Databricks Workspace). Next, let's see how these components address each of the three challenges.
Databricks Platform: No need to set-up and maintain clusters
Databricks Platform is a hosted platform that makes it trivially easy to create and manage a cluster. Databricks Platform includes a sophisticated cluster manager which allows users to have a cluster up and running in seconds, while providing everything they need out-of-the-box. In particular, Databricks Platform provides security, resource isolation, it instantiates a fully configured and up-to-date Spark cluster, it allows dynamic scaling, and it provides seamless data import. This way, Databricks Platform obviates the need to set up and maintain an on premise cluster.
Apache Spark: Unifying existing big data systems
Databricks is built around Apache Spark, which unifies many of the functionalities provided by today's big data systems. In particular, Apache Spark provides support for batch processing, interactive query processing, streaming, machine learning, and graph based computations, all with a single API. This enables developers, data scientists, and data engineers to implement their entire pipeline in one system.
Databricks Workspace: Making the platform easy to use
Databricks Workspace makes it dramatically easier to use big data frameworks, in general, and Spark, in particular, by providing three powerful web-based applications: notebooks, dashboards, and a job launcher.
Notebooks allow users to interactively query and visualize data. Notebooks also provide support for online collaboration, thus allowing multiple users to cooperate on data exploration in real-time. Currently, notebooks allows users to query and analyze data using Python, SQL, and Scala.
Once users create one or more notebooks, they can take the most interesting results from these notebooks and create sophisticated dashboards. They can do so through a powerful yet intuitive dashboard builder, and then publish a dashboard just with the click of a button to other employees in the organization, or to their customers. Dashboards are interactive, as every plot can depend on one or more variables. When these variables are updated, the query behind each plot is automatically re-executed, and the plot is regenerated.
Finally, Databricks Workspace includes a job launcher that enables users to programmatically run arbitrary Spark jobs. For instance, users can schedule jobs to run periodically, or run when their inputs change.
Building big data pipelines with Databricks
Figure 3 shows how Databricks can dramatically simplify the big data pipeline shown in Figure 1.
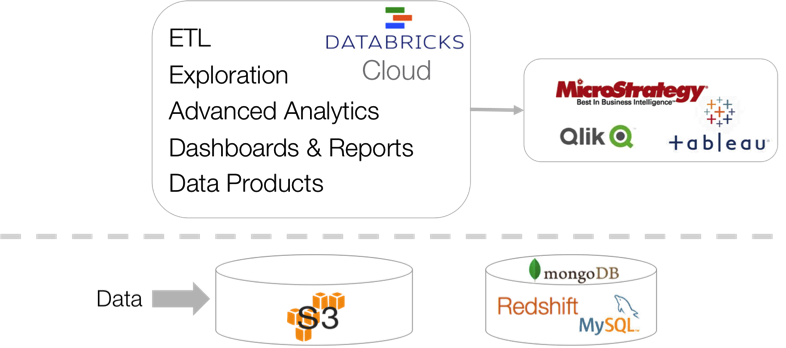
Figure 3: Databricks Cloud, big data pipeline
Let's assume for simplicity that most customer's data is in S3. Then, Databricks can operate on S3 data in place (no need to copy it) and implement the entire data pipeline:
- One can do ETL using Spark jobs or notebooks, which can run periodically or when their inputs change
- One can do interactive exploration and advanced analytics using notebooks
- One can create dashboards in reports using the Dashboard builder
- Finally, one can create, build and run data products as Spark jobs or notebooks.
In addition, Databricks can read inputs from other storage systems and databases available in AWS, and lets users use their favorite business intelligence tools through an ODBC connector.
This way Databricks allows users to focus on finding answers and building great data products rather than wrestling with setting up clusters, and stitching together disparate systems that are difficult to use.
Third Party Applications
While Databricks Workspace makes Databricks instantly useful out-of-the-box and it allows users to build non-trivial data pipelines, we are planning to add support for third party applications, beyond our own applications.

Figure 4: Supporting 3rd party apps
We are already working with some of the certified Spark application developers to run their applications on top of Databricks. We are looking forward to extending Databricks with a vibrant application ecosystem.
Databricks and Spark Community
Databricks will have a beneficial impact on the Apache Spark project, and it reaffirms our commitment to making Spark the best big data framework. Databricks will dramatically accelerate Spark's adoption, as it will make it much easier to learn and use Apache Spark. In addition, Databricks runs 100% Apache Spark. This means that there is no lock in. Users can take their jobs and applications they develop on Databricks and run them on any certified Spark distribution be it on premise or in the cloud.
Summary
It is our belief that Databricks will dramatically simplify big data analysis, and it will become the best place to develop, test, and run data products. This will further fuel the growth of the Spark community by making big data easier to use than ever before.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.