Samsung SDS uses Apache Spark for prescriptive analytics at large scale

Business Challenge
Samsung SDS is the business and IT solutions arm of Samsung Group. A global ICT service provider with over 17,000 employees worldwide and 6.7 billion USD in revenues, Samsung SDS tackles the challenges of some of the largest global enterprises in such industries as manufacturing, financial services, health care and retail.
In the different areas Samsung is focused on, the ability to make timely decisions that maximize the value to a business becomes critical. Prescriptive analytics methods have been used effectively to support decision making by leveraging probable future outcomes determined by predictive models and suggesting actions that provide maximal business value.
One of the main challenges in applying prescriptive analytics in these areas is the need to analyze a combination of structured and unstructured data at large scale, which requires a flexible and comprehensive computation framework.
To demonstrate the effectiveness of prescriptive analytics algorithms implemented by scalable technologies in realizing decision making use-cases, Samsung SDS Research America (SDSRA) has prototyped a framework that Samsung SDS business units can leverage and incorporate as part of the go-to-market products.
Your compact guide to modern analytics

Why Apache Spark
Developing such a solution required three main areas of effort:
- high volume data processing for feature extraction as a means of modeling business environment state;
- prescriptive model training on historical events;
- real-time processing of decision requests and corresponding prescribed actions;
There are different technologies that can be used to support these effort threads but integrating these technologies can turn into a significant undertaking, one which is not directly bringing value to the project. SDSRA turned to Apache Spark due to its ability to provide efficient solutions for all three areas of effort through multiple components that are unified in one single distributed computation paradigm, at the same time as providing the level of fault tolerance expected.
Our first direct contact with Spark was at the Strata Conference earlier in 2014 in Santa Clara, attending the Berkeley Data Analytics Stack tutorial, when the power of the framework and simplicity of the API became apparent. Coming back to the lab, the team experimented with the framework by attempting to implement data mining algorithms such as Apriori, for finding frequent item sets. After this initial experience, the decision was made to apply the framework in our prescriptive analytics proof-of-concept project, triggering two parallel efforts: one to implement a prescriptive analytics algorithm at scale with Spark and a second effort thread to develop a real-time framework based on Spark Streaming to get prescriptions as a response to a continuous stream of requests.
With Spark, the original raw data can be loaded into a resilient distributed dataset (RDD) and transformed into the set of features that define state. The states constitute the input for the prescriptive model training, also performed on the Spark framework through a series of RDD transformations. The resulting transformed data set is then used as input for an MLlib regression model for approximation of a value function, which is the main element of the prescriptive model.
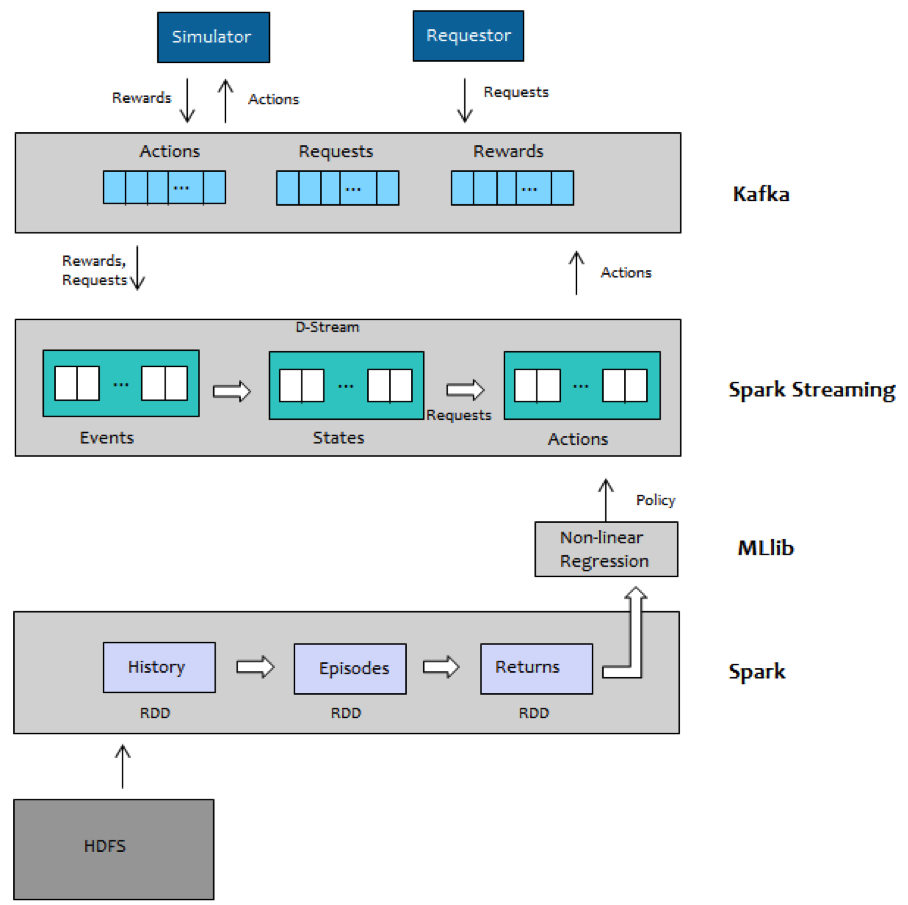
After deriving a policy from the trained model, Spark Streaming is applied for processing the stream of requests, using the model for prescribing actions and maintaining the states as part of the stream.
There are three main characteristics of the Spark ecosystem that makes it a perfect match for this solution: the ability to cache Spark data sets and Spark Streaming data streams in memory, the distributed architecture (allowing horizontal linear scalability on commodity server clusters), and a single development paradigm across all components.
What is next
At SDSRA, we see Spark as a key technology providing high throughput and low latency in processing large volume of data ingested at high speed. We look forward to experimenting with additional components of the ecosystem such as SparkSQL and GraphX, as we evolve our decision making engine into a full solution.
To learn more about SDSRA and this platform, feel free to contact me directly at [email protected]