Making Databricks Better for Developers: IDE Integration

We have been working hard at Databricks to make our product more user-friendly for developers. Recently, we have added two new features that will allow developers easily use external libraries - both their own and 3rd party packages - in Databricks. We will showcase these features in a two-part series. Here is part 1, introducing how to upload your own libraries to Databricks. Stay tuned for the second installment on how to upload Apache Spark Packages and other 3rd party libraries!
Using your favorite IDE with Databricks
Sometimes you prefer to stick to the development environment you are most familiar with. However, you also want to harness the power of Apache Spark with Databricks. We now offer the option to upload the libraries you wrote in your favorite IDE to Databricks with a single click.
To provide this functionality, we have created an SBT plugin (for more information on SBT, see http://www.scala-sbt.org/). This plugin, sbt-databricks, (https://github.com/databricks/sbt-databricks) provides Databricks users the ability to upload their libraries to Databricks within an IDE, like IntelliJ IDEA, or from the terminal. This means that anyone who has SBT can seamlessly upload their custom libraries to Databricks in a single click. This greatly simplifies the iteration time during development and provides users the freedom to develop in the environment that they are most comfortable with.
Uploading your own libraries to Databricks in 4 simple steps
Here is a simple example of how this works with IntelliJ IDEA:
0. Install the SBT plugin. (IntelliJ IDEA -> Preferences)
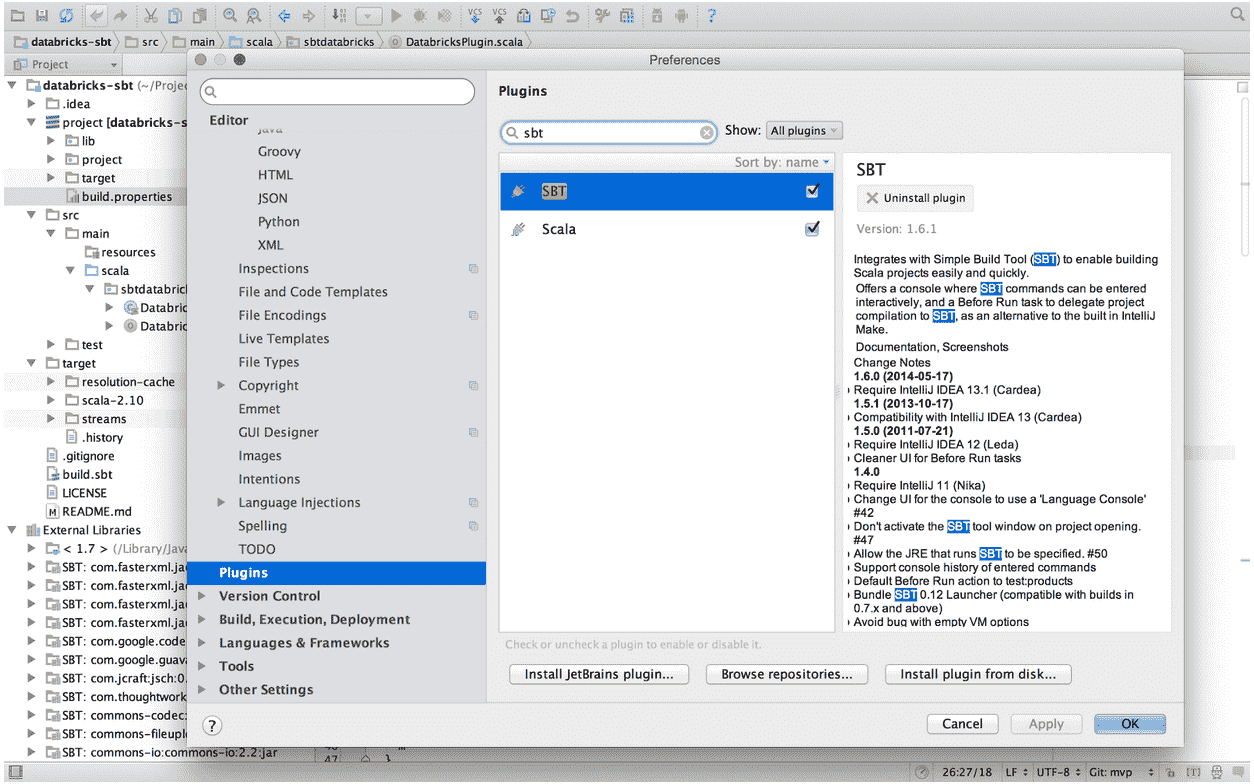
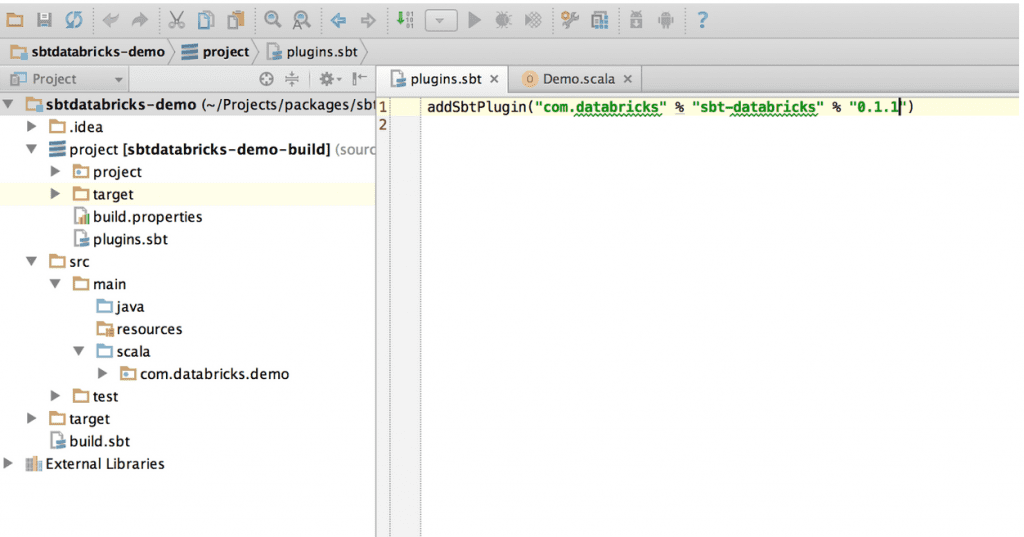
1. Import the sbt-databricks plugin
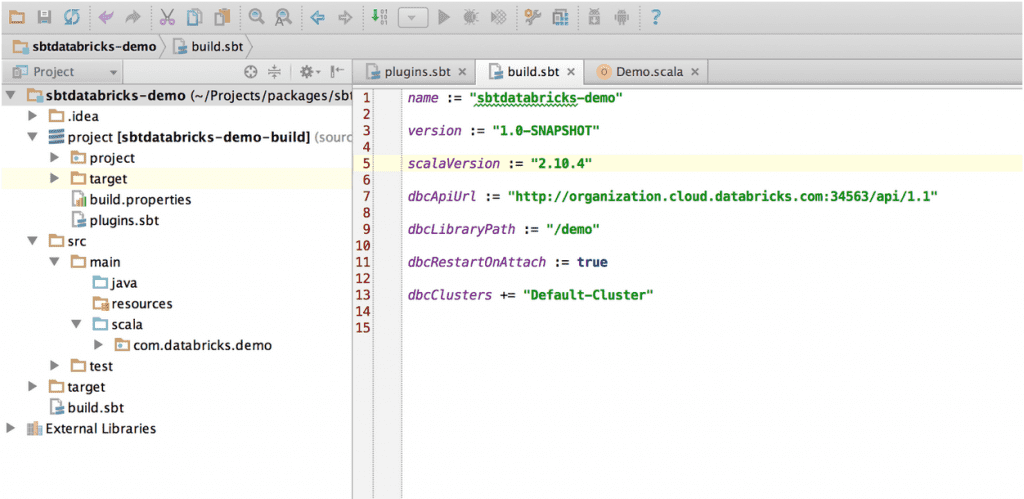
2. Set up configurations in your build file
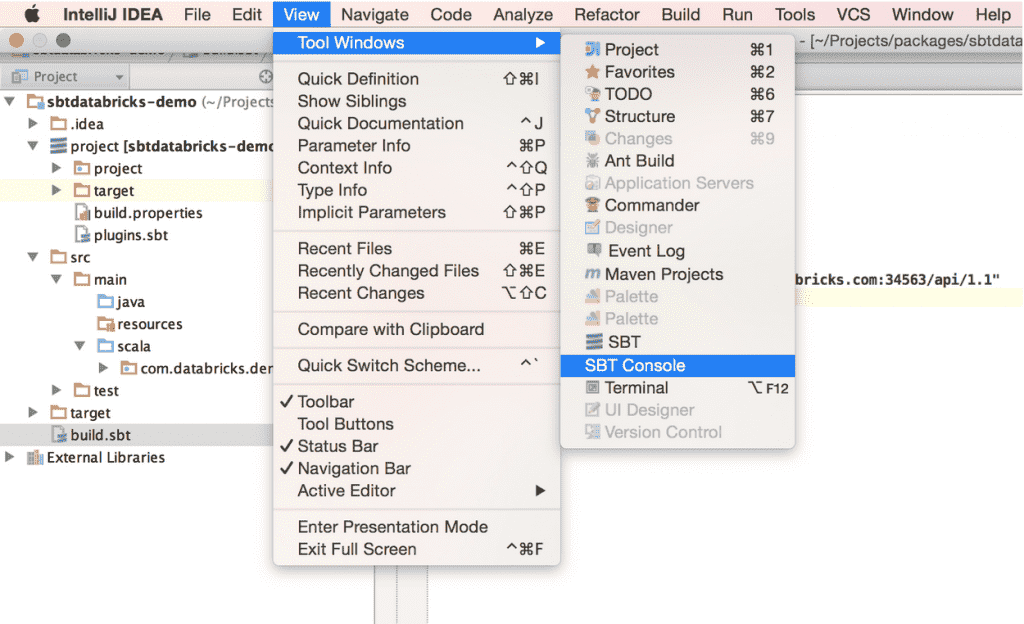
3. Open up the SBT console (through IDE or terminal)
4. Execute "dbcDeploy" and hit "Enter"!
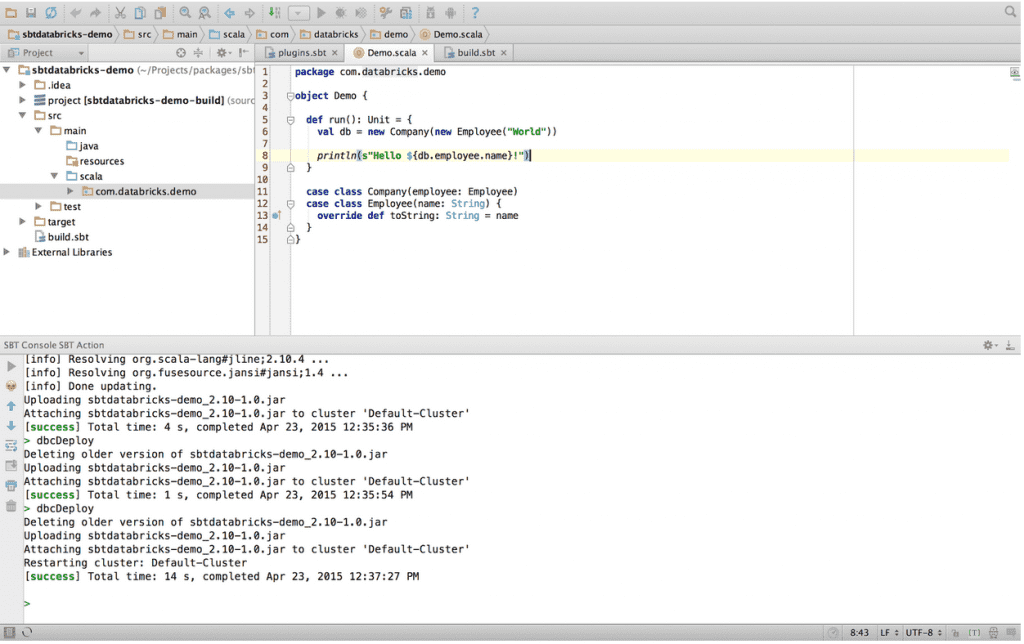
Congratulations! Your library is now in Databricks
Your compact guide to modern analytics

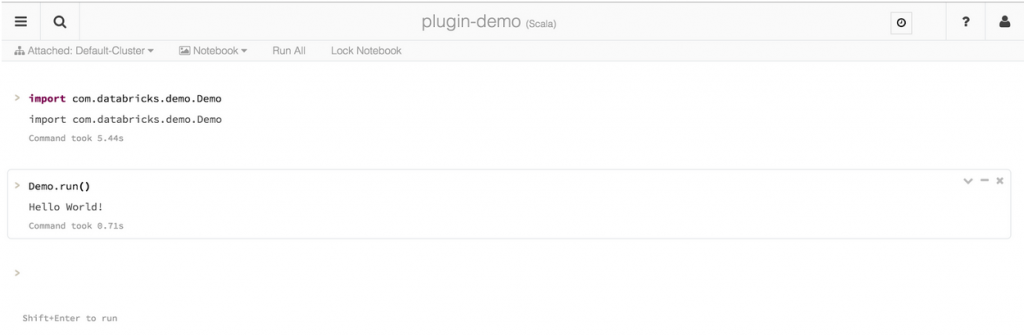
An example of using a custom library in Databricks
Now your libraries are imported to Databricks,
You can use them in Notebooks during an interactive data exploration session...
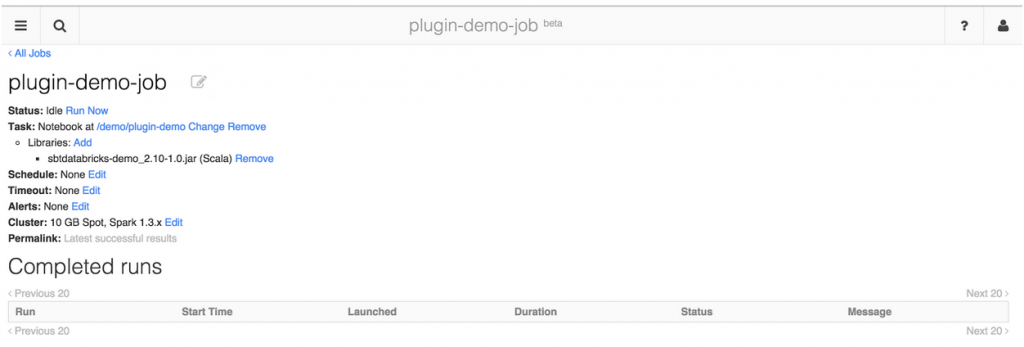
...or you can also use them in a production setting with Jobs! (both in Notebook Jobs and Jar Jobs, see our Jobs blog for more details on how this works)
Summary
In this blog post we introduced sbt-databricks, an SBT plugin that allows users to easily deploy their own libraries to Databricks straight from their IDEs (SBT support for different IDEs can be found here). At Databricks, our goal is to keep simple things simple, and make complex things possible. This includes providing developers with the flexibility to work in the environments they prefer - IDEs or Notebooks. We are developers ourselves after all!
If you have more questions, please check out the additional resources for more detailed information on how to use this plugin.
Stay tuned for the next installment, where we will show how to search for, and import 3rd Party Libraries from Spark Packages and/or Maven Central!
Additional resources
- Download sbt-databricks from github
- Get Documentation and sbt tips and tricks
- Find SBT Plugins for other IDEs
- Learn more about Databricks
- Sign-up for a 14-day free trial of Databricks