Databricks is now Generally Available
by Ion Stoica and Matei Zaharia
We are excited to announce today, at Spark Summit 2015, the general availability of the Databricks – a hosted data platform from the team that created Apache Spark. With Databricks, you can effortlessly launch Spark clusters, explore data interactively, run production jobs, and connect third-party applications. We believe Databricks is the easiest way to use big data.
Our vision at Databricks is to make big data simple and enable every organization to turn its data into value. We first unveiled Databricks at Spark Summit 2014, and launched it in limited availability in November. The excitement for the platform has been fantastic, with thousands of people requesting access and tremendous feedback from users. We’re now delighted to take the next step towards this vision by making Databricks available to everyone.
We want to enable that instant productivity for all of your data problems.
[embed]https://vimeo.com/130273206[/embed]
Why Databricks?
As many data scientists and engineers can attest, the majority of their time is spent not on the data analysis itself but on the supporting infrastructure. Key issues include deploying software, keeping production jobs up, and connecting disparate tools to process and visualize data. Equally problematic is the need for data engineers to re-implement the models developed by data scientists for production. With Databricks, data scientists and engineers can eliminate these issues and just spend their time focusing on their data.
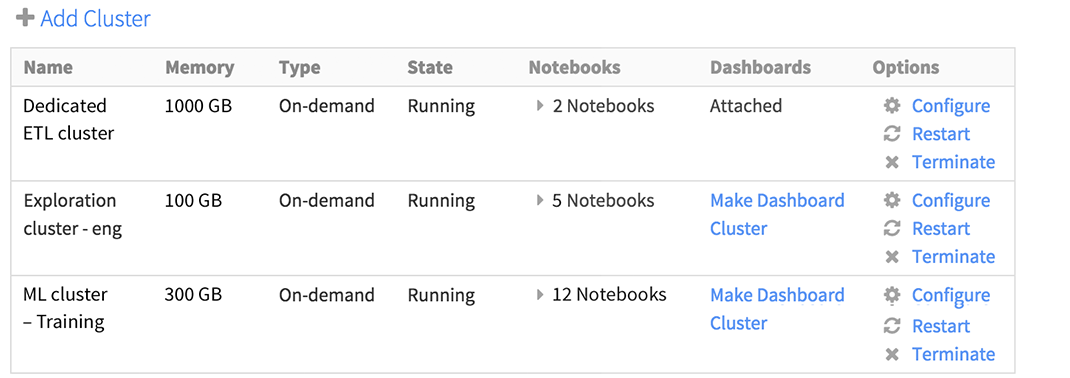
Instant Spark Clusters
Instead of taking weeks to months to provision hardware, instantly launch and manage optimized Spark clusters on Amazon EC2. You can scale from a few nodes to hundreds, all with just a few clicks. You can also use Amazon spot instances to save on costs.
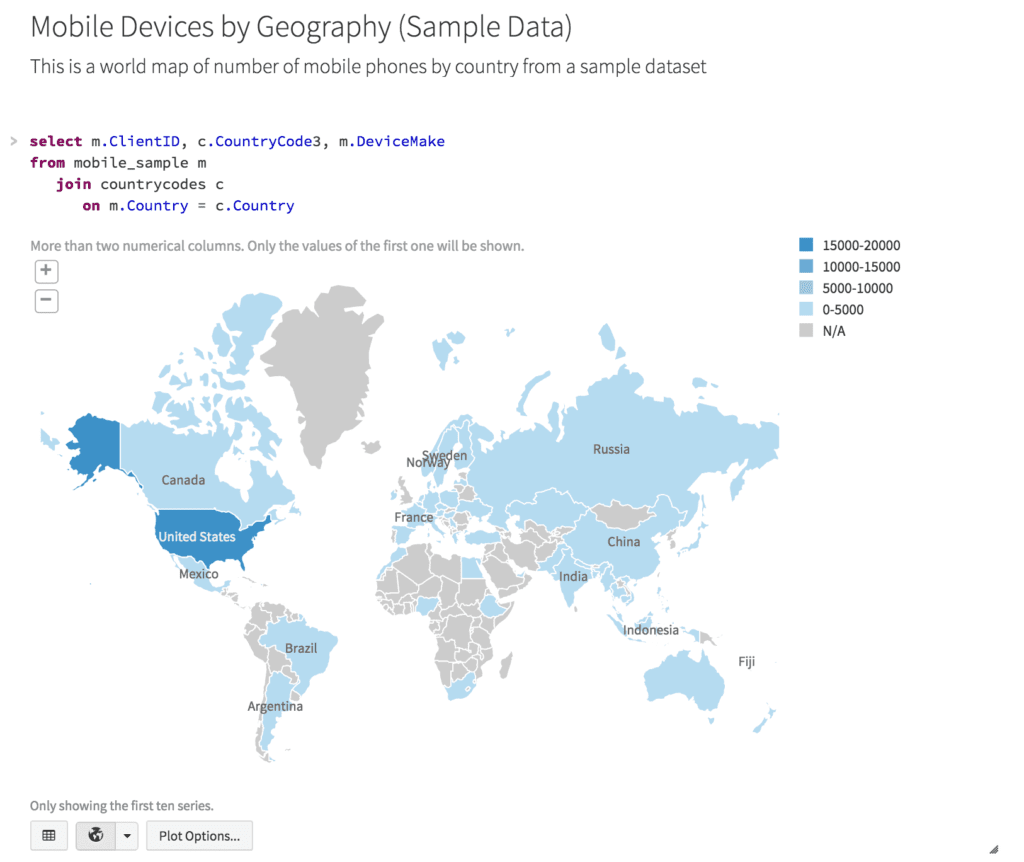
Interactively Explore and Visualize Your Data
Databricks includes notebooks, an interactive and collaborative multi-user environment for exploration and visualization. You can combine text, code execution, visualization, and advanced analytics such as machine learning (MLlib) and graphs (GraphX) – all within the same notebook. You can write notebooks in SQL, Python, Scala, Java, and R. This way Databricks allows you to be instantly productive in your language of choice.
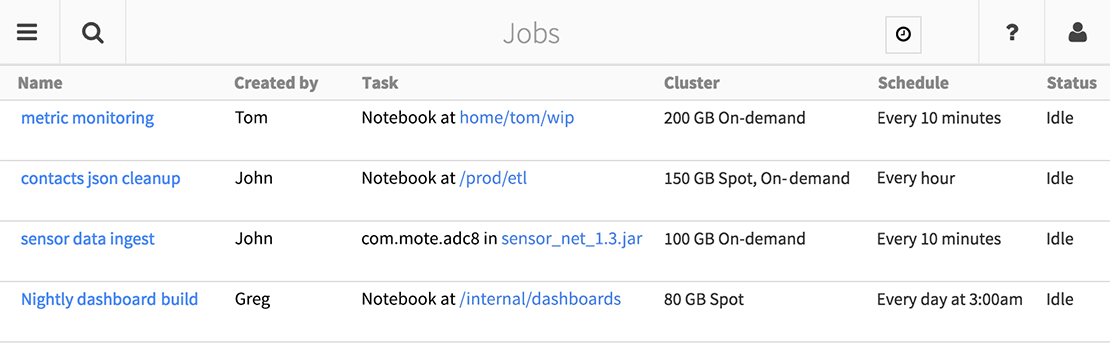
Easily Deploy Production Pipelines
Databricks has a powerful Jobs feature for taking applications from prototype to production. With Jobs, you can run both notebooks and standalone Spark or Spark Streaming programs. Jobs include a flexible scheduler, email alerts, automatic retries, run history, and cluster reuse. Furthermore, Databricks Jobs are the first Software as a Service platform to support Spark Streaming, making it easy to deploy scalable, fault-tolerant streaming applications. Databricks Jobs are simply the easiest way to run Spark applications.
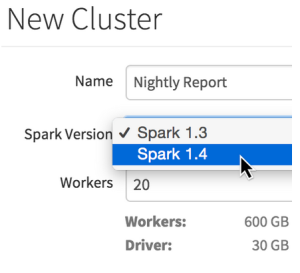
New Features for GA
With the launch of General Availability today, we’re also releasing three new features that users have been requesting. These are immediately available in Databricks deployments:
- Spark 1.4 support: Choose Apache Spark 1.4 when provisioning a Databricks cluster.
- Spark Streaming in notebooks: Experiment with Spark Streaming interactively in notebooks, or deploy it in production jobs.
- Improved commenting: Comment on individual text selections within a notebook and respond to comments via the new sidebar.
What’s Coming Next?
In addition to general availability, at Spark Summit we have also announced several major new features that we are rolling out over the next few months. Expect to see these in your Databricks deployments soon:
- R-language notebooks: Analyze data using R and SparkR, including all of R’s standard visualization and statistics packages.
- Access control and private notebooks: Manage permissions to view and execute code at an individual level.
- Version control and GitHub: Track changes to source code in Databricks, and store notebooks in GitHub to work with them from outside the platform.
How to Get Started
Databricks runs in your own Amazon Web Services account or Virtual Private Cloud. To try it out, sign up for a 14-day free trial today.
For more information on Databricks, check out:
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.