Guest blog: SequoiaDB Connector for Apache Spark
by Tao Wang
This is a guest blog from Tao Wang at SequoiaDB. He is the co-founder and CTO of SequoiaDB, leading its long-term technology vision, and is responsible for the leadership of advanced technology incubations. SequoiaDB is a JSON document-oriented transactional database.
Why We Chose Apache Spark
SequoiaDB is a NoSQL database that has the capability to replicate data on different physical nodes and allows users to specify which “copy of data” that the application should access. It is capable of running analytical and operational workloads simultaneously on the same cluster with minimal I/O or CPU contention.
The joint solution of Apache Spark and SequoiaDB allows users to build a single platform such that a wide variety of workloads (e.g., interactive SQL and streaming) can run together on the same physical cluster.
Making SequoiaDB Work with Spark: The Spark-SequoiaDB Connector
Spark-SequoiaDB Connector is a Spark data source that allows users to read and write data against SequoiaDB collections with Spark SQL. It is used to integrate SequoiaDB and Spark, combining the advantages of a schema-less storage model with dynamic indexing and the power of Spark clusters.
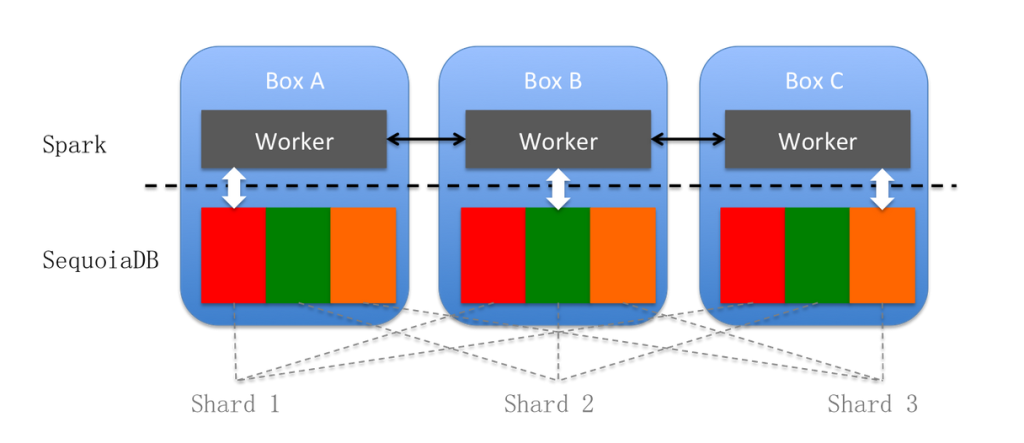
Spark and SequoiaDB can be installed in the same physical environment or in different clusters. The Spark-SequoiaDB Connector pushes down the search conditions to SequoiaDB, and only retrieves the records that match the query predicates. This optimization enables analytics against operational data sources without the need to perform ETL between SequoiaDB and Spark.
Here is a code example of how to use the Spark-SequoiaDB Connector in SparkSQL:
Financial Services Industry Use Case: Improved Transaction History Archiving System
The joint solution of Spark and SequoiaDB can help organizations to retain more and get more value out of their data. Here we will showcase a financial services industry example, where a bank implemented an improved transaction history archiving system with Spark and SequoiaDB.
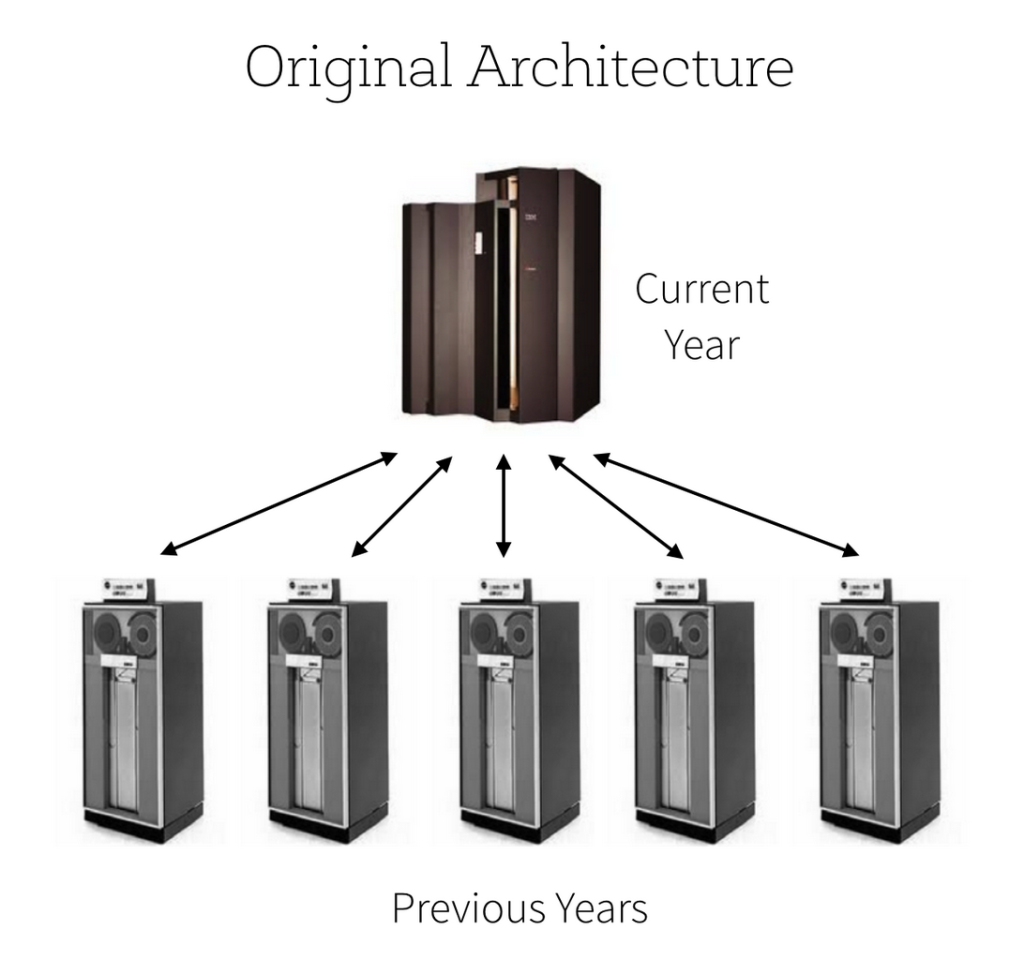
For the past few decades, most banks run their core banking systems on mainframes. The technical limitations of their mainframe systems meant that transaction history older than one year had to be removed from the mainframes and archived on tapes.
However, banking customers today have much higher expectations of customer service than the past, driven by the broad adoption of online and mobile banking. To compete for customers more effectively, one of our customers - who is a large bank - wanted to improve its offering by allowing their customers to search for transactions older than one year.
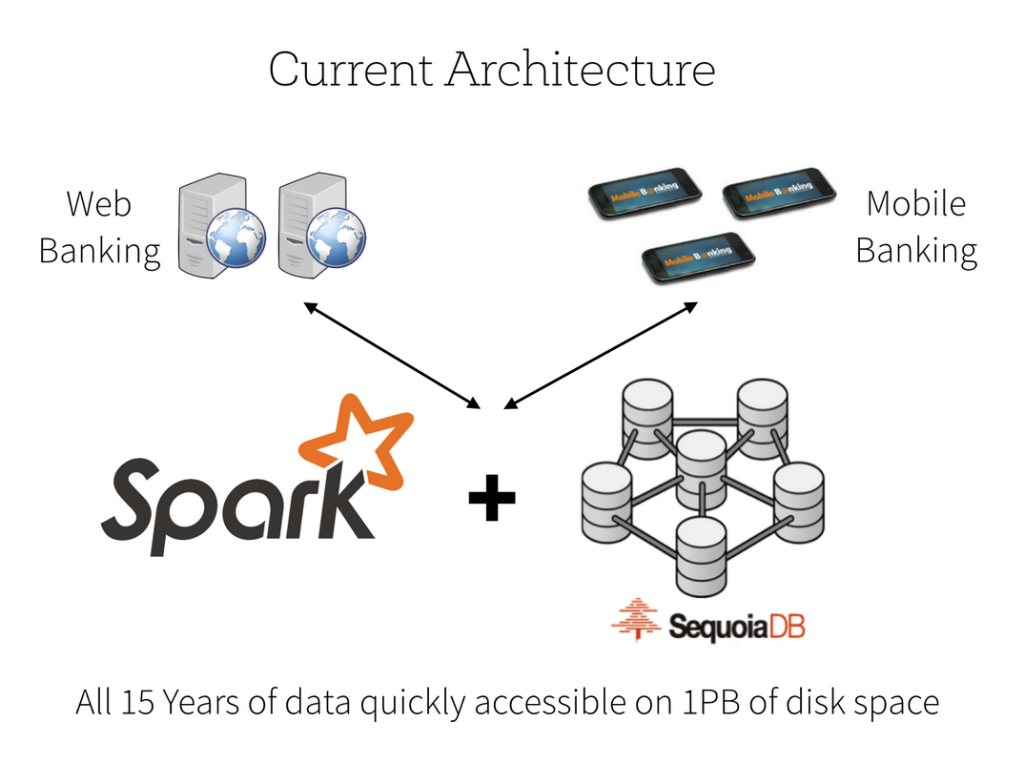
Using SequoiaDB, this bank can save 15 years of all customer transaction data in 50 physical nodes (occupying more than 1PB disk space). This new system allows customers to access their full transaction history easily on the mobile device as well as the website.
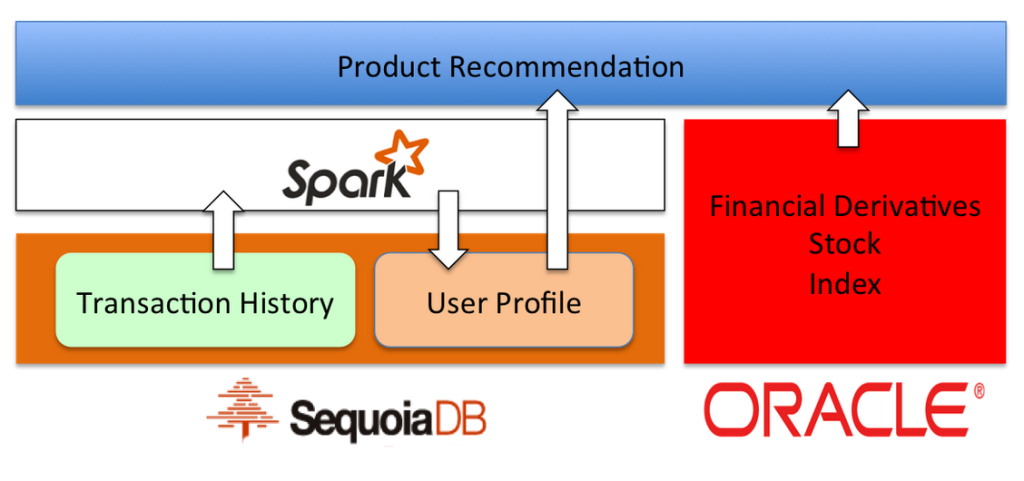
Financial Services Industry Use Case: Product Recommendation with Spark and SequoiaDB Integration
Once the full transaction history of all customers is readily available, the bank built a customer profiling system based on the transaction data to find the appropriate investment products for each customer.
Once the customer profiling system calculates product recommendations when processing all of the transaction data and logs, these properties are written back to a collection with a tag array for each customer.
These properties are used by the front desk staff and the recommendation engine to identify the potential interests of each customer. After deploying this system, the success rate of financial derivatives recommendation increased by more than ten times.
What next with Spark at SequoiaDB
Most of our financial customers are interested in streaming (for anti-money laundering and high-frequency trading use cases) or interactive SQL processing (for government supervision). We intend to put more efforts to improve the features and stability of these Apache Spark components, such as helping SparkSQL to support standard SQL2003.
For more information about Spark-SequoiaDB Connector please visit:
https://github.com/SequoiaDB/spark-sequoiadb
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.