Helping the Democratization of Big Data
by Ali Ghodsi
When we started Databricks, we thought that extracting insights from big data was insanely difficult for no good reason. You almost needed an advanced degree to be able to get any meaningful work done. As a result, only a select few in each organization could ask questions from their big data, the people who set up the clusters and knew how to use advanced tools such as Hive and MapReduce. We therefore set out to build a software as a service product that would drastically simplify big data processing.
Soon after launching we learned something interesting. In many organizations, a democratization effort was taking place with more and more people starting to use Databricks to ask questions from the data. They were no longer bottlenecked by the chosen few that knew how to talk to the data. However, as some organizations had over hundreds of users using Databricks, a new set of challenges had risen. First, users wanted to control access to their data. Second, they wanted version control and management of multiple Apache Spark versions. Third, they wanted R-support. These requirements were all interlinked. I'm proud to announce that after much hard work, we are now releasing Databricks with all these features. Below I explain the story of how each of these came about and the lessons that are behind these features.
As employees with different functions started asking questions from the data, it very soon became a hard requirement to be able to control who in their organization should see or modify their queries, which could contain very sensitive information or could not be shared due to security compliance reasons. This is natural in a large organization. In our case, this requirement became even more important because we had developed a new way in which hundreds of users could use separate notebooks on the same shared Spark cluster, enabling huge cost savings for their organizations. This was not possible before, as before this feature, each notebook and user would have to have a separate isolated cluster. By enabling such cluster sharing, it was even more important that your coworkers couldn't snoop on your most sensitive notebooks. Databricks now comes with access control features that let you control who can see, who can run and parameterize, and who can edit and manage your notebooks. We are the first vendor to offer this feature for Spark.
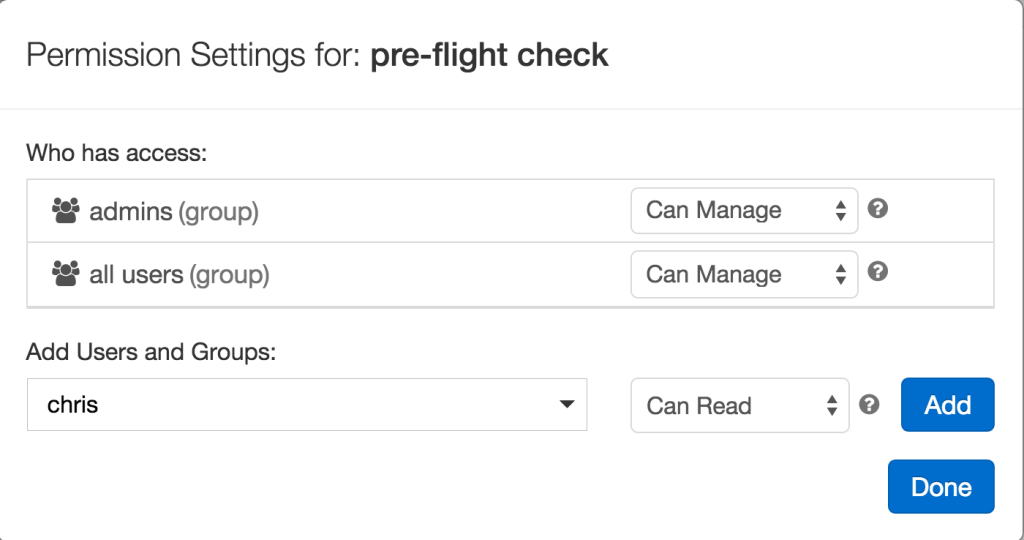 Setting permissions in Databricks
Setting permissions in Databricks
We tried from day one to make it really easy to collaborate on live notebooks, with features such as real-time updates and commenting features. But as collaboration started to seriously happen, users wanted to have auditability. Who modified my notebooks and how can I go back to an earlier version? Furthermore, many users were already using external version control systems, such as GitHub. Finally, many users wanted to sometimes explore some new features of a Spark release on a small experimental cluster, but continue to use old Spark versions on production clusters. As they gained more experience with the new Spark version, they would like to reuse their old notebooks on the new Spark version. Hence, they wanted to manage multiple Spark versions and be able to easily go between these with their jobs and notebooks. Databricks current release now comes with these features for version control, GitHub integration, and management of multiple Spark versions.
Finally, as more job functions started asking questions from the data, we heard that more and wanted to use R as their preferred language to talk to the data. SQL and Python were already supported for a while and these were wildly popular. But we did not have R support. This trend seemed to be very prominent as a lot of people without computing degrees were being trained in R at universities, in classes, and other settings. We therefore accelerated the incorporation of SparkR into Spark and also added R as a first class language as part of Databricks, making us the first company to commercially support SparkR.
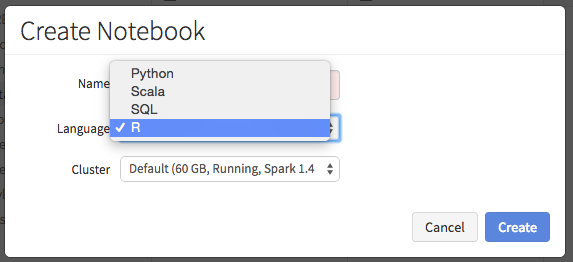 R Notebooks in Databricks
R Notebooks in Databricks
This release of Databricks is dubbed "version 2.0" since it contains many all of the above features that enable the democratization effort inside many organizations. I used quotes around the version number, because as a SaaS product versions don't play the same role as for traditional software. We will continue to maintain a two week release cadence, each containing new exciting features that our users requested.
Try these features yourself and please let us know what you think.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.