Apache Spark 1.5 Preview Now Available in Databricks
by Reynold Xin and Michael Lumb
We are excited to announce that starting today, Apache Spark 1.5.0 is available as a preview in Databricks. Our users can now choose to provision clusters with Spark 1.5 or previous Spark versions ready-to-go with a few clicks.
Officially, Spark 1.5 is expected to be released in a few weeks, and the community is doing QA testing for the release. Given the fast-paced development of Spark, we feel it is important to enable our users to leverage the new development and features as soon as possible. With traditional on-premise software deployment, it can take months, and sometimes even years, to receive software updates from vendors. With Databricks’ cloud model, we can push updates in a matter of hours and let users try their Spark version of choice.
What’s New?
The last few releases of Spark focus on making data science more accessible, through high-level programming APIs such as DataFrames, machine learning pipelines, and R language support. A large part of Spark 1.5, on the other hand, focuses on under-the-hood changes to improve Spark’s performance, usability, and operational stability.
Spark 1.5 delivers the first phase of Project Tungsten, a new execution backend for DataFrames/SQL. Through code generation and cache-aware algorithms, Project Tungsten improves the runtime performance with out-of-the-box configurations. Through explicit memory management and external operations, the new backend also mitigates the inefficiency in JVM garbage collection and improves robustness in large-scale workloads.
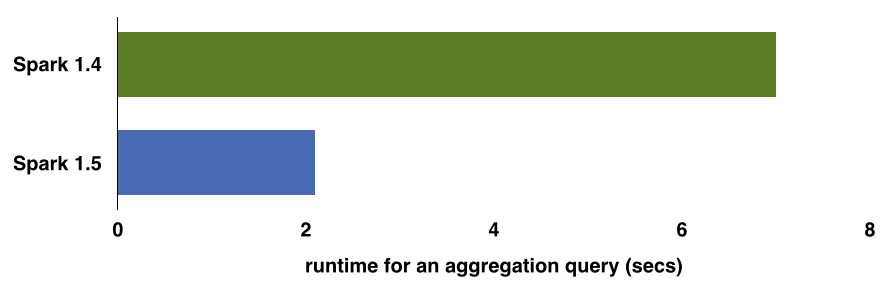
Over the next few weeks, we will be writing about Project Tungsten. To give you a sneak peek, the above chart compares the out-of-the-box (i.e. no configuration changes) performance of an aggregation query (16 million records and 1 million composite keys) using Spark 1.4 and Spark 1.5 on my laptop.
Streaming workloads typically run 24/7 and have stringent stability requirements. In this release, Typesafe has introduced Backpressure in Spark Streaming. With this feature, Spark Streaming can dynamically control the data ingest rates to adapt to unpredictable variations in processing load. This allows streaming applications to be more robust against bursty workloads and downstream delays.
Of course, Spark 1.5 is the work of more than 220 open source contributors from over 80 organizations, and includes a lot more than the above two. Some examples include:
- New machine learning algorithms: multilayer perceptron classifier, PrefixSpan for sequential pattern mining, association rule generation, etc.
- Improved R language support and GLMs with R formula.
- Better instrumentation and reporting of memory usage in web UI.
Stay tuned for future blog posts covering the release as well as deep dives into specific improvements.
How do I use it?
Launching a Spark 1.5 cluster is as easy as selecting Spark 1.5 experimental version in the cluster creation interface in Databricks.
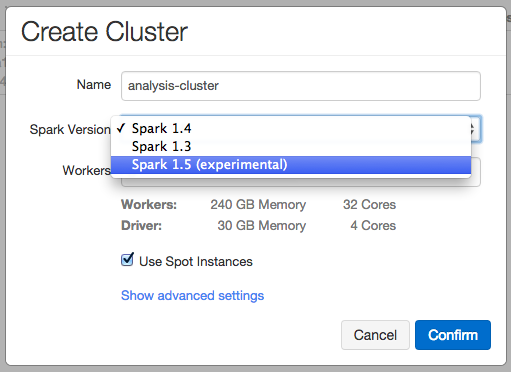
Once you hit confirm, you will get a Spark cluster ready to go with Spark 1.5.0 and start testing the new release. Multiple Spark version support in Databricks also enables users to run Spark 1.5 canary clusters side-by-side with existing production Spark clusters.
You can find the work-in-progress documentation for Spark 1.5.0 here. Please be aware that just like any other preview software, Spark 1.5.0 support is experimental. There will be bugs and quirks that we find and fix in the next couple of weeks. The good news is that you don’t have to worry about following the development or upgrading yourself. As we discover and fix bugs in the open source project, the Spark 1.5 option in Databricks will also be updated automatically. If you encounter a bug, please report it by filing a JIRA ticket.
To try Databricks, sign up for a free 30-day trial.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.