Announcing an Apache Spark 1.6 Preview in Databricks
by Patrick Wendell, Reynold Xin and Michael Lumb
Today we are happy to announce the availability of an Apache Spark 1.6 preview package in Databricks. The Apache Spark 1.6.0 release is still a few weeks away - this package is intended to provide early access to the features in the upcoming Spark 1.6 release, based on the upstream source code. Using the preview package is as simple as selecting the “1.6.0 (Preview)” version when launching a cluster:
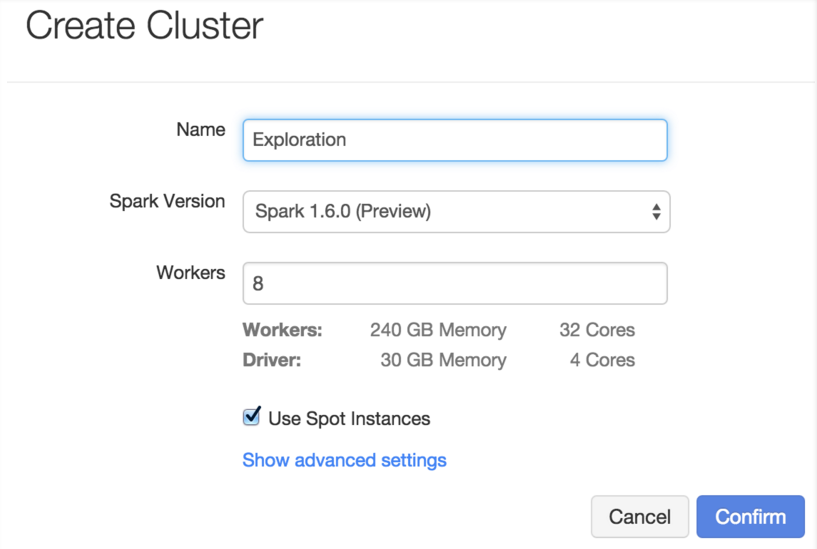
Once you have created a cluster, you will have access to new features from the upcoming Spark release. You can also test existing jobs or notebooks with Spark to see performance improvements from earlier versions of Spark. Of course, until the upstream Apache Spark 1.6 release is finalized, we do not recommend fully migrating any production workload onto this version. This feature will be rolling out to Databricks customers over the next week as part Databricks 2.8.
So - what is coming in Spark 1.6? We have curated a list of major changes along with code examples. We’ll also be running a webinar on December 1st to outline the features in this release. A few of the major features are:
A new Dataset API. This API is an extension of Spark’s DataFrame API that supports static typing and user functions that run directly on existing JVM types (such as user classes, Avro schemas, etc). Dataset’s use the same runtime optimizer as DataFrames, but support compile-time type checking and offer better performance. More details on Datasets can be found on the SPARK-9999 JIRA.
Automatic memory configuration. Users no longer need to tune the size of different memory regions in Spark. Instead, Spark at runtime will automatically grow and shrink regions according to the needs of the executing application. For many applications, this will mean a significant increase in available memory that can be used for operators such as joins and aggregations.
Optimized state storage in Spark Streaming. Spark Streaming’s state tracking API has been revamped with a new “delta-tracking” approach to significantly optimize programs that store large amounts of state. The state tracking feature in Spark Streaming is used for problems like sessionization, where the information for a particular session is updated over time as events stream in. In Spark 1.6, the cost of maintaining this state scales with the number of new updates at any particular time, rather than the total size of state being tracked. This can be a 10X performance gain in many workloads.
Pipeline persistence in Spark ML. Today most Spark machine learning jobs leverage the ML Pipelines API. Starting in Spark 1.6, this API supports persisting pipelines so that they can be re-loaded at runtime from a previous state. This can be useful when certain pipeline components require significant computation time, such as training large models.
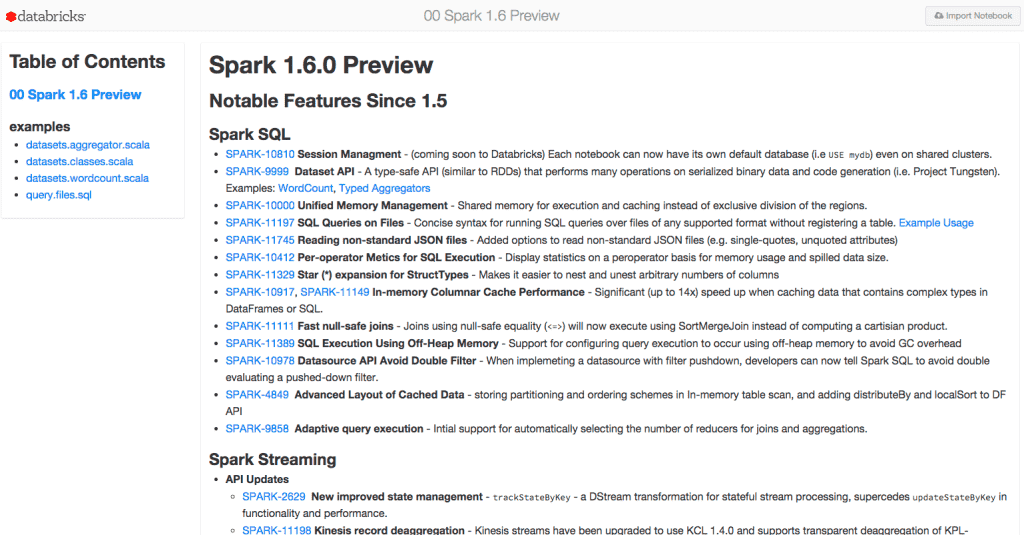
An overview of Spark 1.6 changes and some code examples to demonstrate new features
(click on image to see full list)
We are looking forward to finalizing the formal Apache Spark 1.6.0 release. In the meantime, we invite you to take the Spark 1.6 preview package for a spin in Databricks!
To try Databricks today, sign up for a free 14-day trial.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.