Building a Just-In-Time Data Warehouse Platform with Databricks
by Wayne Chan
Read Rise of the Data Lakehouse to explore why lakehouses are the data architecture of the future with the father of the data warehouse, Bill Inmon.
Data warehouses have been designed to deliver value out of data and it has long served enterprises as the de-facto solution to do just that. But in today’s big data landscape where enterprises are dealing with a new level of volume, variety, and velocity of data, it is too challenging and costly to move that data into your data warehouse and make sense of the entire dataset in a timely manner. Common pain points that data engineers and data scientists experience when working with traditional data warehousing solutions include:
- Inelasticity of compute and storage resources: Traditional data warehouses require you to plan for the maximum load at any given time. This inelasticity makes it very difficult to optimize compute and storage to meet ever-changing demands which can be a very costly way to manage your resources.
- Rigid architecture that's difficult to change: Traditional data warehouses are inherently rigid due to its schema-on-write architecture. This results in having to build costly and time-consuming ETL pipeline to access and manipulate the data. And as new data types and sources are introduced, the need to augment your ETL pipelines exacerbates the problem.
- Limited advanced analytics capabilities: Traditional data warehouses are limited to SQL queries which can hamper the depth of analysis, impeding your ability to solve more complex problems with machine learning, streaming, and graph computations.
The Databricks Solution: Just-In-Time Data Warehousing Made Simple
Powered by Apache Spark, Databricks provides a fast, simple, and scalable way to augment your existing data warehousing strategy by combining pluggable support for common data sources and the ability to dynamically scale nodes and clusters on-demand. Additionally, Databricks’ Spark clusters have built-in SSD caching to complement Spark’s native in-memory caching to provide optimal flexibility and performance. This enables organizations to read data on-the-fly from the original data source and perform “just-in-time” queries on data wherever it resides rather than investing in complicated and costly ETL pipelines.
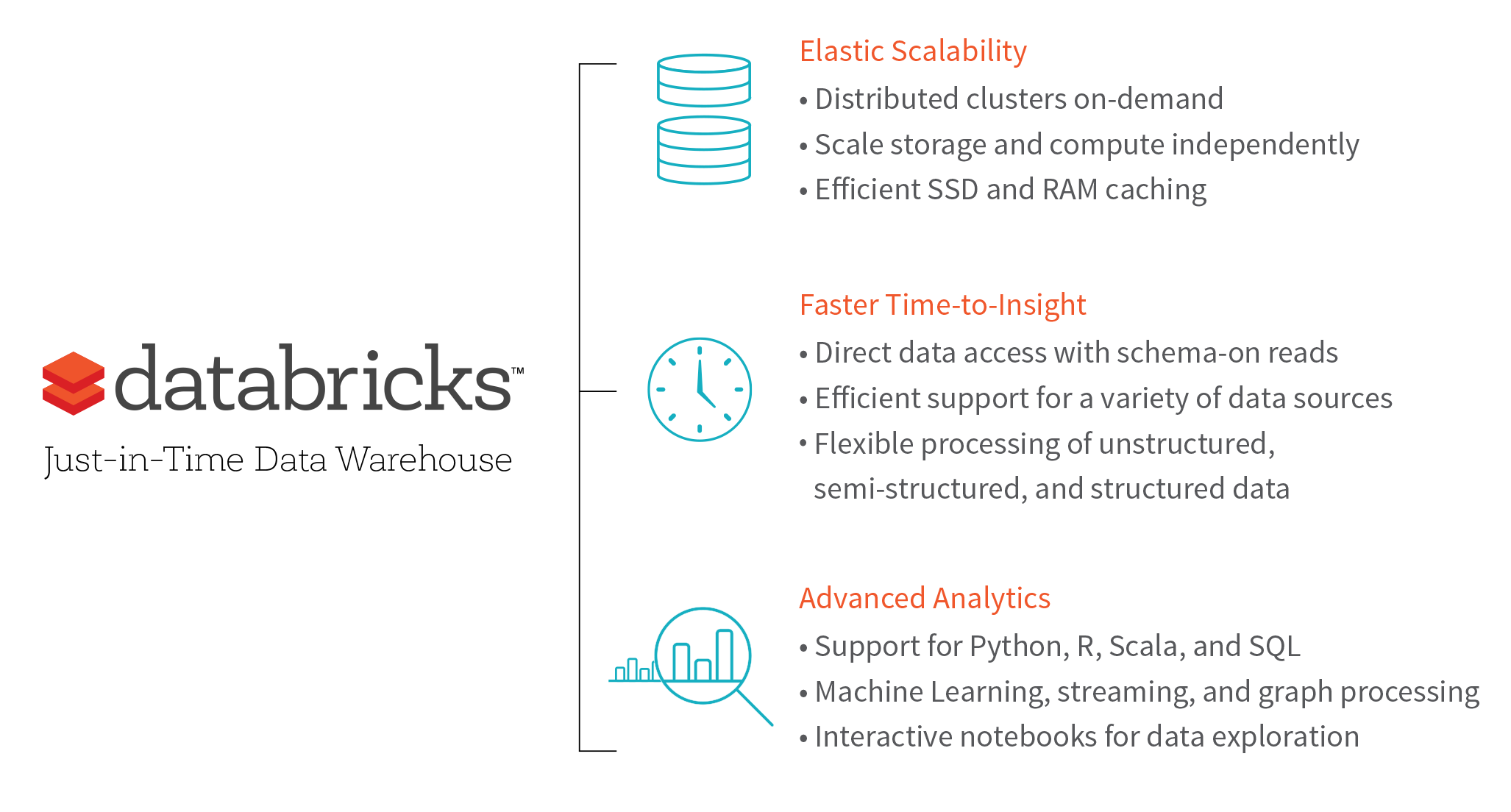
How exactly does Databricks deliver on this promise?
- Unified platform for a variety of data sources: Rationalize the ETL process with APIs in your language of choice and JDBC/ODBC connectors, allowing enterprises to more easily and cost-effectively process data on-demand from any source directly. You also have the flexibility to combine Databricks with an existing data warehouse to achieve a unified view of your data.
- On-schema reads for direct data access: Define the schema at the point in time of reading, avoiding the need to declare, load, partition, and index the data before querying.
- Scale on-demand for maximum elasticity: Independently scale resources according to your data processing and querying needs with a few clicks of a button, allowing data teams to optimize resources.
- SSD caching for distributed performance: Databricks’ Spark in-memory clusters have built-in SSD caching that minimizes pre-processing and speeds up your queries by caching your files upon extraction.
- Support for advanced data analytics: Empower your team to easily take data science to the next level with built-in advanced capabilities like machine learning, graph processing, real-time streaming analytics, and more.
Take a look at Databricks to implement or extend your current data warehousing strategy to utilize more of the data you already have and deliver insights faster.
Ready to take your data warehousing to the next level? Check out our Just-in-Time Data Warehouse Solution Brief to learn more.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.