Continuous Integration and Delivery of Apache Spark Applications at Metacog
by Luis Caro and Doug Stein
This is a guest blog from our friends at Metacog.
Luis Caro is the Lead Cloud and DevOps Architect at Metacog, where he is responsible for the security and scalability of the entire platform.
Doug Stein is the CTO of Metacog, where he is responsible for product strategy and development; he doubles as the product owner and voice of the market.
At Metacog, we have been using Databricks as our development and production environment for over one year. During this time we built a robust continuous integration (CI) system with Databricks, which allows us to release product improvements significantly faster. In this blog, we will describe how we’ve built the CI system with Databricks, GitHub, Jenkins, and AWS.
What is Metacog?
Metacog allows companies to replace simplistic assessment (e.g. multiple-choice) with authentic performance tasks (scored by machine learning algorithms informed by customer-supplied scoring rubrics and training sets). We do this by offering a learning analytics API-as-a-service, which allows us to translate a person’s interactions (i.e., real-time events) with an online manipulative into an accurate assessment of their understanding. The product gives our customers an API and JSON wire format for large-scale ingestion, analysis, and reporting on “Metacognitive activity streams” (how the learner tackles an open-ended performance task - not merely the final answer). The Metacog platform is applicable to learning (instruction, training, or assessment) in K-12, postsecondary, corporate, military, etc.
The Need for Continuous Integration / Delivery
Metacog supports tens of millions of concurrent learners (each of whom might be generating activity at a rate up to tens to a few hundred KB/sec). This is Big Data - and the platform needs to be able to ingest the data without loss and apply various machine learning algorithms with optimal performance, reliability and accuracy. To this end, Metacog implemented Apache Spark with Databricks as the primary compute environment in which to develop and run analysis and scoring pipelines.
The Metacog development team consists of backend developers, devops and data scientists who constantly introduce improvements to the platform code, infrastructure and machine learning functionality. In order to make this “research-to-development-to-production” pipeline a truly streamlined and Agile Process, Metacog deployed a continuous integration production system for all Spark code.
Metacog’s Development Pipeline
The Metacog development pipeline ensures that both hardcore developers and data scientists are able to:
- Access the latest version of the code.
- Develop and run the code within their preferred toolset - our team integrates IDEs such as IntelliJ with Databricks in addition to using the built-in Databricks notebooks.
- Merge improvements that then automatically deploy (without human intervention) to a shared stage environment that mirrors the production environment.
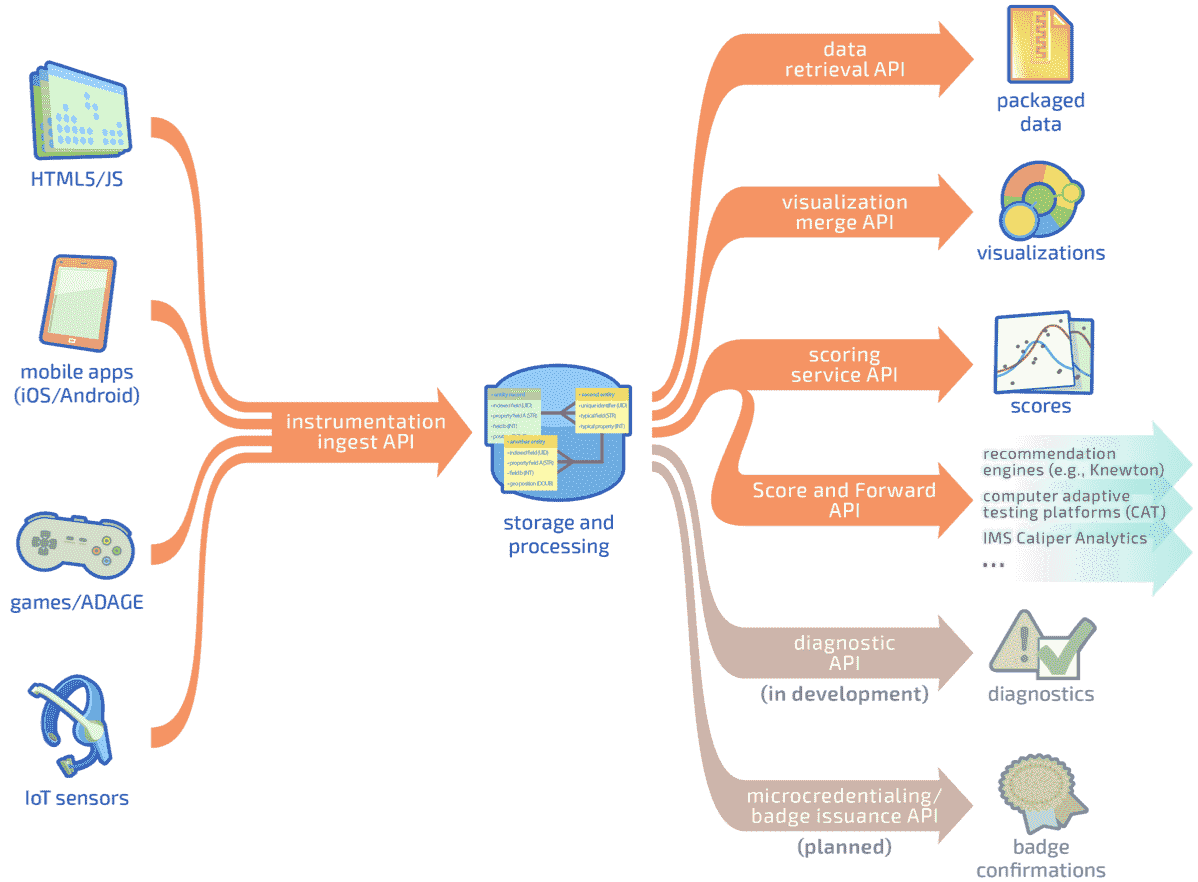
The development pipeline is illustrated in the following figure:

The pipeline works as follows: A developer syncs his/her local development environment (which can be either a notebook or an IDE) using GitHub. Whenever the developers commit on a specific branch, the Metacog Jenkins server automatically tests the new code; if the tests pass the code is then built and deployed to the live testing infrastructure. This infrastructure consists of an exact replica of production resources to permit load testing and final checks before deploying changes to production. In the case of Spark code, live testing employs multiple Spark clusters created using the Databricks Jobs functionality.
The main components in the pipeline are:
- Databricks notebooks: Provide a collaborative and online editing environment that allows both developers and data scientists to run their code on a real Spark cluster (instead of using Spark on local mode on their laptops). Notebooks allow Data Scientists to test and tune machine learning algorithms and methods over big data sets. Similarly, notebooks allow developers to evaluate algorithm performance and detect/fix bugs that are only present on big data sets.
- Jenkins continuous integration server: Metacog uses Jenkins for continuous testing and delivering all of the developer code. Jenkins guarantees that different commits from several developers pass all unit test and that code gets delivered and deployed without developer or devops assistance. Every time a developer performs a commit on a master branch, Jenkins automatically tests and builds that branch code.
- Databricks workspace Library: When notebooks need to use code from external sources or libraries this interface allows a JAR to be attached to the clusters that will run the notebooks. This way the notebook code can reference and use the attached libraries.
- Amazon Web Services S3: An object storage service, used by Jenkins to store all build files for both Spark and non-Spark code.
- Databricks Jobs: The job interface deploys code to a cluster based on schedules and custom triggers. Metacog uses this interface to deploy and maintain both the live testing and production Spark clusters guaranteeing their stability and scalability. Thanks to the Databricks Jobs interface, the Metacog infrastructure team can easily provision a specific set of clusters based on the platform needs and expected usage. It simplifies version management and server provisioning enabling the team to optimize cost and performance. (Added benefit: DevOps doesn’t have to keep reminding developers or data scientists to clean up after themselves and shut down unused clusters!)
In the sections below we will describe in detail how we used Databricks APIs to automate two key capabilities in the pipeline: Deploying built JARs as libraries (Components #1 and #3) and updating stage and production resources with latest builds (Components #5).
Using Deployed Libraries with Databricks Notebooks
Both developers and data scientists need to be able to use any methods or classes from the production code inside their notebooks. Having these libraries allows them to have access to production data and test or evaluate performance of different versions of production code. Using the library API, a Jenkins server can build and deploy JAR files as libraries into a special folder on the Databricks workspace. When Databricks loads such libraries it recognizes versioning - so that developers can use a compatible version of the library for the code they’re developing. This allows developers to control when they adopt new library versions and gives them a stable environment for benchmarking and regression testing. Every time someone commits code to the stage repo, Jenkins follows the following steps:
- Build the repo code and if the tests pass, it generates a JAR with an incremented version number and uploads it to S3.
- Execute a Python script that uses the AWS SDK with the JAR S3 URL, generates a pre signed URL for the JAR and calls the Databricks API “libraries/create” endpoint. Since the libraries/create call needs a JAR url, the S3 pre-signed URL fits perfectly enabling us to generate a public URL with an expiration of a couple of minutes. By using a pre-signed URL we grant the Databricks API time-limited permission to download the build JAR, reducing the risk of the JAR being exposed.
def createlibrary(path,jarurl):
head = {'Authorization':DBAUTH}
endpoint = DBBASEENDPOINT + 'libraries/create'
newpath = "/" + path
data = {"path": newpath, "jar_specification": {"uri":jarurl}}
r = requests.Session().post(endpoint,headers=head,data=json.dumps(data))
if r.status_code == 200:
print "library uploaded for notebooks"
else:
print r.content
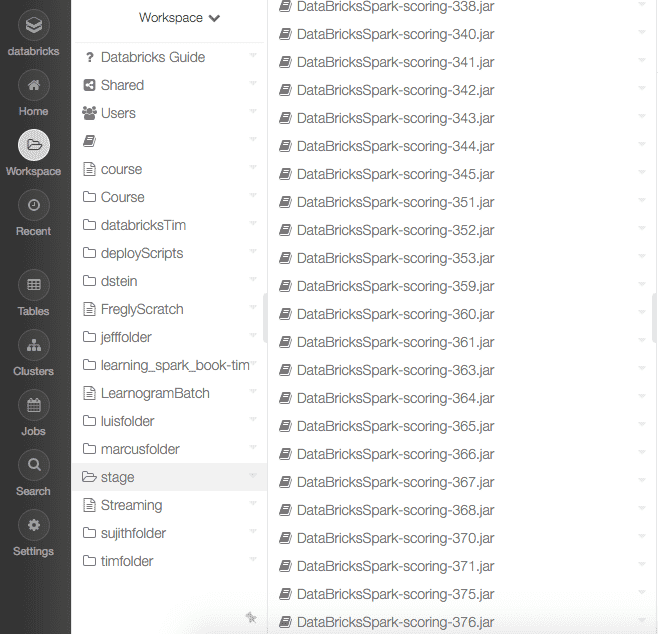
After the process is complete developers can attach these libraries to any notebook cluster or job using Databricks web console. Here is an example of the Jenkins build output:

Here is an example of the Databricks workspace after job is updated (note the newly-built V376 JAR at the end of the listing):
Updating Databricks Jobs and Cluster Settings with Jenkins
Metacog uses the Jobs API to deploy and manage production and stage Spark clusters. In addition to the steps described above, when a new version of the library gets built, Jenkins must update all jobs to make sure clusters use the new build JAR and the correct Spark version for that jar. This functionality is achieved by using the build file stored on S3 together with a python script that updates the jobs using the Databricks Jobs API.

This is done in three steps (illustrated in the figure above):
- Step 1: Jenkins Uploads the build JAR to S3 together with a lastBuild.txt specifying the JAR version number
- Step 2: Jenkins runs a python script that executes a job called deployJar that runs a notebook that copies the JAR built by Jenkins from S3 to the “dbfs:/FileStore/job-jars”. The Python script uses the “jobs/runs/list” and “/jobs/run-now” endpoints to trigger the deployJar and wait until it finished. The deployJar notebook looks like this:

- Step 3: For updating the production and stage jobs with the new JAR and any other Spark cluster settings (e.g. a new Spark version) Jenkins executes a Python script that calls the Databricks API “jobs/reset” endpoint. The “jobs/reset” endpoint the “dbfs:/FileStore/job-jars” path created on Step 2. Here is the updated job of the previous example:

Results and Benefits
Thanks to the Databricks environment and APIs we succeeded in implementing a continuous delivery pipeline all of our Spark code. Some of the main benefits that the Metacog team now enjoys are:
- Reduced time for launching features into production: Before implementing the pipeline, new features took around 1 month to be incorporated into the production version of the platform. With the pipeline this time was reduced to only the 1 or 2 weeks that are scheduled for live testing. This means that the release cadence was improved from 12 times per year to at least 24 times per year.
- Better management of AWS EC2 costs: DevOps doesn’t have to keep reminding developers or data scientists to clean up after themselves and shut down unused clusters. Thanks to the job interface developers do not have to worry about shutting down clusters after they’ve finished using them. This represents at least a 28% AWS EC2 cost saving - since developers often forget to shut down a cluster when they were not going to use it over the weekend.
- Faster onboarding: Since we have production libraries available within the Databricks workspace, new data scientists joining the Metacog team take one week instead of one month to become productive with real data generated with production code.
- More time to develop instead of maintenance: Both devops, developers and Data Science have more time to work developing algorithms instead of spending it managing Jobs and uploading libraries to the Databricks environment. We estimate that around 20% of the developers time was being wasted on these tasks.
- Big Data experimentation and tuning: Thanks to this pipeline, we have been able to solve performance bugs that are only present on big data sets in half the time.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.