The Quest for Hidden Treasure: An Apache Spark Connector for the Riak NoSQL database
by Pavel Hardak
View this notebook in Databricks
This is a guest blog from our friends at Basho. Pavel Hardak is a director of product management at Basho.
This article introduces Riak Spark Connector, an open source library which bridges the gap between Apache Spark and Riak NoSQL database. It brings the full power of Apache Spark to the operational data, managed in Riak distributed clusters. With the Riak Apache Spark Connector, Riak users now have an integrated, scalable solution for Big Data analytics and Spark users now have a resilient, highly available datastore.
About Riak
Riak is open source, distributed NoSQL database, which is developed and supported by Basho Technologies. Basho offers two major products: Riak KV (Key Value) and Riak TS (Time Series). Both products share the same core codebase, but are tuned for different use cases. Riak KV is a highly resilient, scalable, key-value store. Riak KV is known for its ability to scale up and down in a linear fashion, handle huge amounts of reads, updates and writes with low latency while being extremely reliable and fault tolerant. More recently, Riak TS was introduced, specifically optimized for time series data. It adds very fast bulk writes, very efficient “time slice” read queries and supports a subset of the SQL language over Riak TS tables.
Introducing the Riak Connector for Apache Spark
We have found that many leading organizations use a mix of NoSQL and SQL database products in their infrastructure as each one has specific advantages depending on the use case. In the past, some databases were used more for analytical workloads while others were used for operational ones. As modern NoSQL databases, like Riak, are gaining new capabilities, they are being adopted for additional use cases, like IoT, metrics, and edge-device analytics. To make it easier to perform such tasks, Basho has created a Riak Spark Connector, as we believe that Apache Spark is currently the best technology choice to use alongside Riak. Basho selected Spark for this development effort not only due to customer and market demand but also due to the fact that Spark and Riak share major design principles: high performance, scalability, resiliency and operational simplicity.
Implementing the Apache Spark Connector for Riak
Modeled using principles from the “AWS Dynamo” paper, Riak KV buckets are good for scenarios which require frequent, small data-sized operations in near real-time, especially workloads with reads, writes, and updates — something which might cause data corruption in some distributed databases or bring them to “crawl” under bigger workloads. In Riak, each data item is replicated on several nodes, which allows the database to process a huge number of operations with very low latency while having unique anti-corruption and conflict-resolution mechanisms. However, integration with Apache Spark requires a very different mode of operation — extracting large amounts of data in bulk, so that Spark can do its “magic” in memory over the whole data set. One approach to solve this challenge is to create a myriad of Spark workers, each asking for several data items. This approach works well with Riak, but it creates unacceptable overhead on the Spark side.
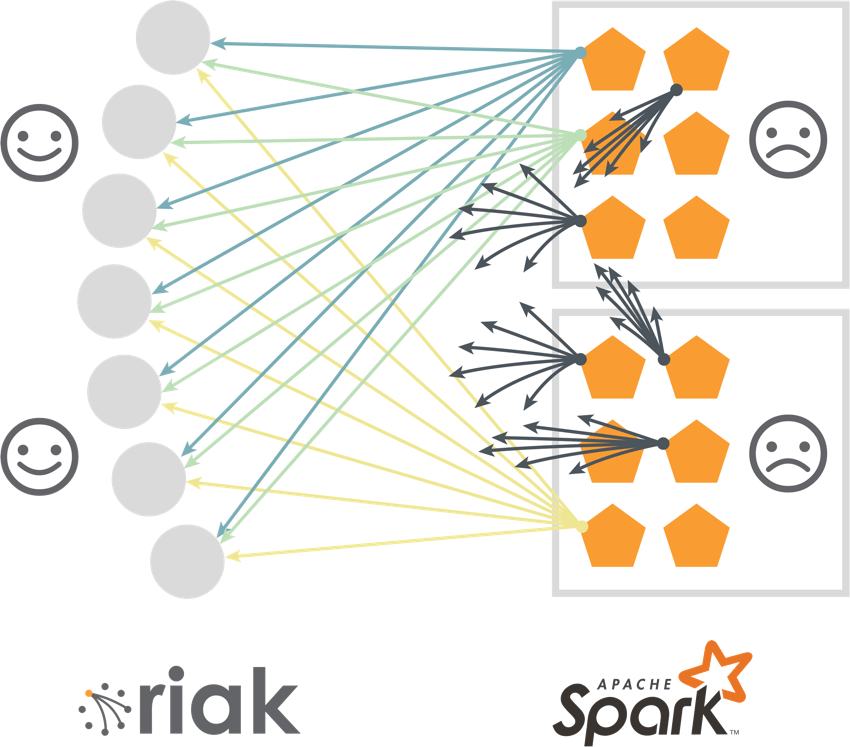
Another option is using Riak’s built-in secondary index query (2i). In this approach, the user’s application contacts any Riak node with a query, then this Riak node, becoming a “coordinating node”, queries all other relevant Riak nodes, collects required keys and streams it back to the user application. Then the user app will loop over the keys to retrieve the values. Alas, it was found that queries with a bigger result set could possibly overload the coordinating node. Again, not a good result, so we had to teach Riak new tricks.
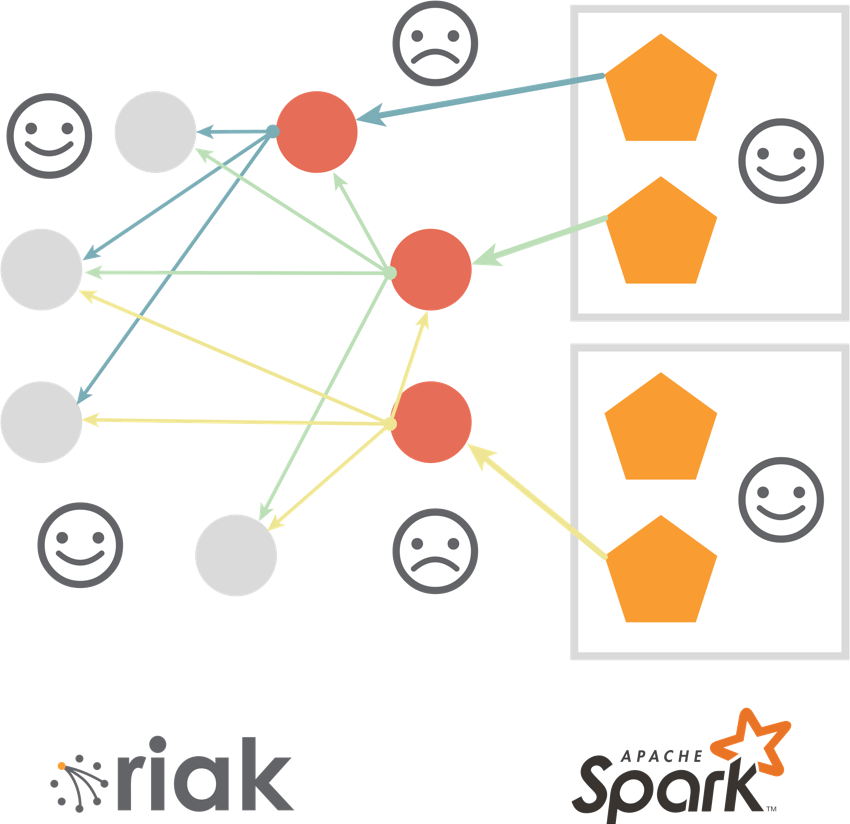
The solution was found in enhancing the 2i query with a smart Coverage Plan and Parallel Extract APIs. In the new approach, the user application contacts the coordinating node, but this time instead of doing all the work, this node returns the locations of the data using cluster replication and availability information. Then “N” Spark workers open “N” parallel connections to different nodes, which allow the application to retrieve the desired dataset “N” times faster, without generating “hot spots”. To make it even faster, we implemented a special type of bulk query, called a “full bucket read”, which extracts the whole logical bucket without the need for a query condition. Also, it returns both keys and values, saving another round-trip to the server.
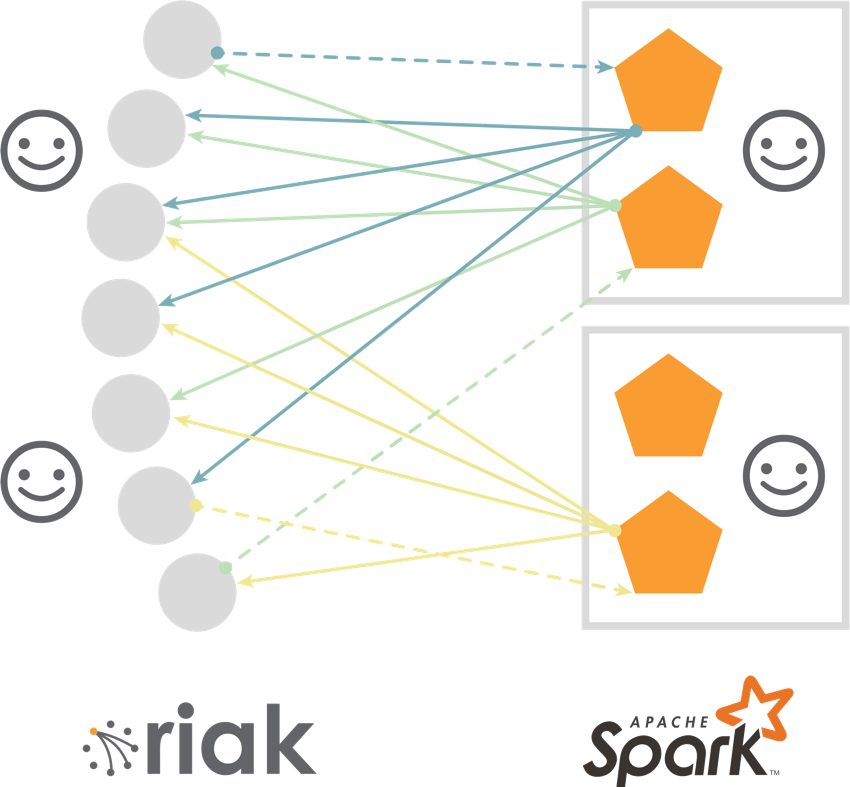
The strength of a Riak KV bucket is its ability to store unstructured data in a schema-less architecture with the “values” being opaque. But for many Spark use cases, data must be mapped into a record with Scala or Java types. Fortunately, many Riak applications use JSON, which allows Spark developers to easily convert it into a Spark DataFrame by providing a user-defined schema. The conversion happens “on the fly” and makes it easier for a Spark programmer to work with the retrieved data.
Riak TS meets Spark SQL
Being a distributed, master-less, highly available and linearly scalable NoSQL datastore, Riak TS adds a number of SQL-like capabilities. It includes a DDL for tables (yeah, CREATE TABLE ...) with named attributes and data types, primary keys (used both for local indexing and clustering), a subset of SQL query language with filters and aggregations and more (additional SQL commands are being added as we speak).
Adding SQL support for a NoSQL database is not a trivial endeavor by itself and we were happy to leverage SQL capabilities, mapping them to well-known Spark constructs, such as DataFrames and Spark SQL. Riak Spark Connector automatically partitions SQL queries between Spark workers. Riak TS also supports key/value functionality, which does not have a schema, so we used Spark RDDs to integrate with key/value (KV) buckets. It is convenient and more efficient to store device metadata, configuration information, and profiles in key/value buckets.
Conclusion
As mentioned earlier in this post, there is no “best” NoSQL database for every possible use case. Riak KV and Riak TS provide an excellent solution for a number of popular use cases, as evidenced by the fact that Riak is the underlying database supporting many of the world’s most highly trafficked applications. The Riak Spark Connector gives users the ability to efficiently analyze the data in Riak utilizing the power of Apache Spark. This makes the quest for discovering incredible insights hidden in the enormous volumes of data being driven by modern applications, a lot easier. Riak Spark Connector fully supports Riak TS 1.3 for both time-series tables and key/value buckets1.
Working closely with the Databricks team, we created a notebook, showing Spark and Riak TS integration, which can be found in Databricks at ‘Data Sources / Databases & Other Data Sources / RiakTS Tutorial’.
Additionally, there are a couple of nice tutorials/demonstrations on Basho.com. The first gives a demonstration of Riak TS using a publicly available data set and the second builds on this example by using the same data set and analyzing it using the Apache Spark Connector.
[breadcrumb slug="footnote-1"]
1 Riak KV will gain Spark support soon, contact me if you are interested to check it out once it is available.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.