How to use SparkSession in Apache Spark 2.0
A unified entry point for manipulating data with Spark
by Jules Damji
Generally, a session is an interaction between two or more entities. In computer parlance, its usage is prominent in the realm of networked computers on the internet. First with TCP session, then with login session, followed by HTTP and user session, so no surprise that we now have SparkSession, introduced in Apache Spark.
Beyond a time-bounded interaction, SparkSession provides a single point of entry to interact with underlying Spark functionality and allows programming Spark with DataFrame and Dataset APIs. Most importantly, it curbs the number of concepts and constructs a developer has to juggle while interacting with Spark.
In this blog and its accompanying Databricks notebook, we will explore SparkSession functionality in Spark 2.0.
Exploring SparkSession’s Unified Functionality
First, we will examine a Spark application, SparkSessionZipsExample, that reads zip codes from a JSON file and do some analytics using DataFrames APIs, followed by issuing Spark SQL queries, without accessing SparkContext, SQLContext or HiveContext.
Creating a SparkSession
In previous versions of Spark, you had to create a SparkConf and SparkContext to interact with Spark, as shown here:
Whereas in Spark 2.0 the same effects can be achieved through SparkSession, without expliciting creating SparkConf, SparkContext or SQLContext, as they’re encapsulated within the SparkSession. Using a builder design pattern, it instantiates a SparkSession object if one does not already exist, along with its associated underlying contexts.
At this point you can use the spark variable as your instance object to access its public methods and instances for the duration of your Spark job.
Configuring Spark’s Runtime Properties
Once the SparkSession is instantiated, you can configure Spark’s runtime config properties. For example, in this code snippet, we can alter the existing runtime config options. Since configMap is a collection, you can use all of Scala’s iterable methods to access the data.
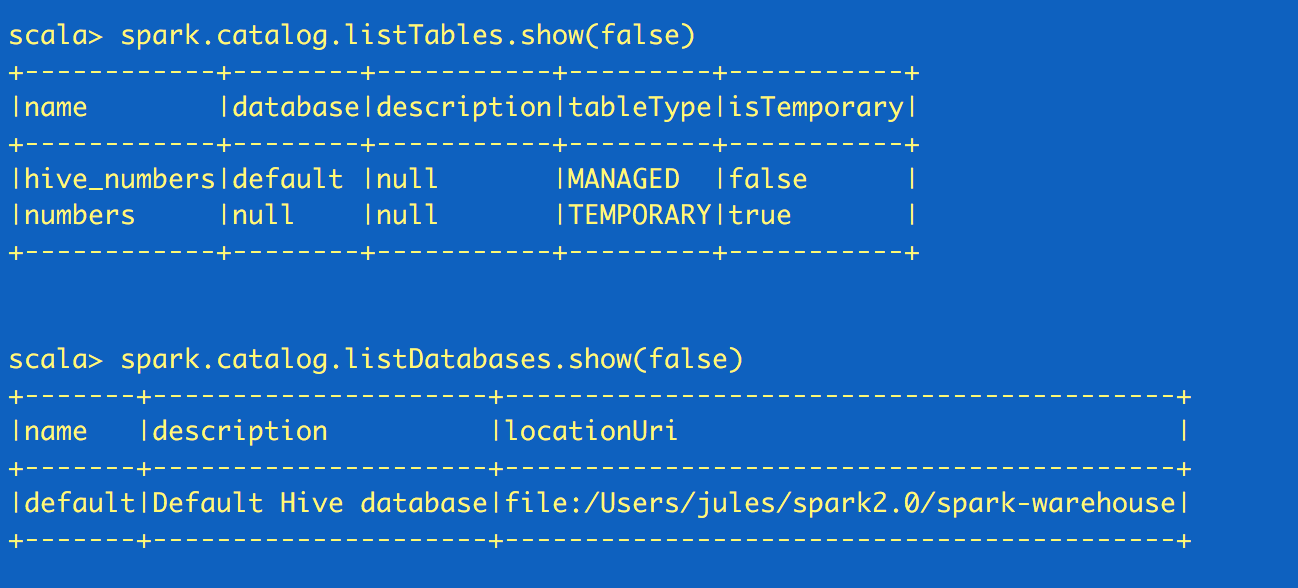
Accessing Catalog Metadata
Often, you may want to access and peruse the underlying catalog metadata. SparkSession exposes “catalog” as a public instance that contains methods that work with the metastore (i.e data catalog). Since these methods return a Dataset, you can use Dataset API to access or view data. In this snippet, we access table names and list of databases.
Creating Datasets and Dataframes
There are a number of ways to create DataFrames and Datasets using SparkSession APIs
One quick way to generate a Dataset is by using the spark.range method. When learning to manipulate Dataset with its API, this quick method proves useful. For example,
Reading JSON Data with SparkSession API
Like any Scala object you can use spark, the SparkSession object, to access its public methods and instance fields. I can read JSON or CVS or TXT file, or I can read a parquet table. For example, in this code snippet, we will read a JSON file of zip codes, which returns a DataFrame, a collection of generic Rows.
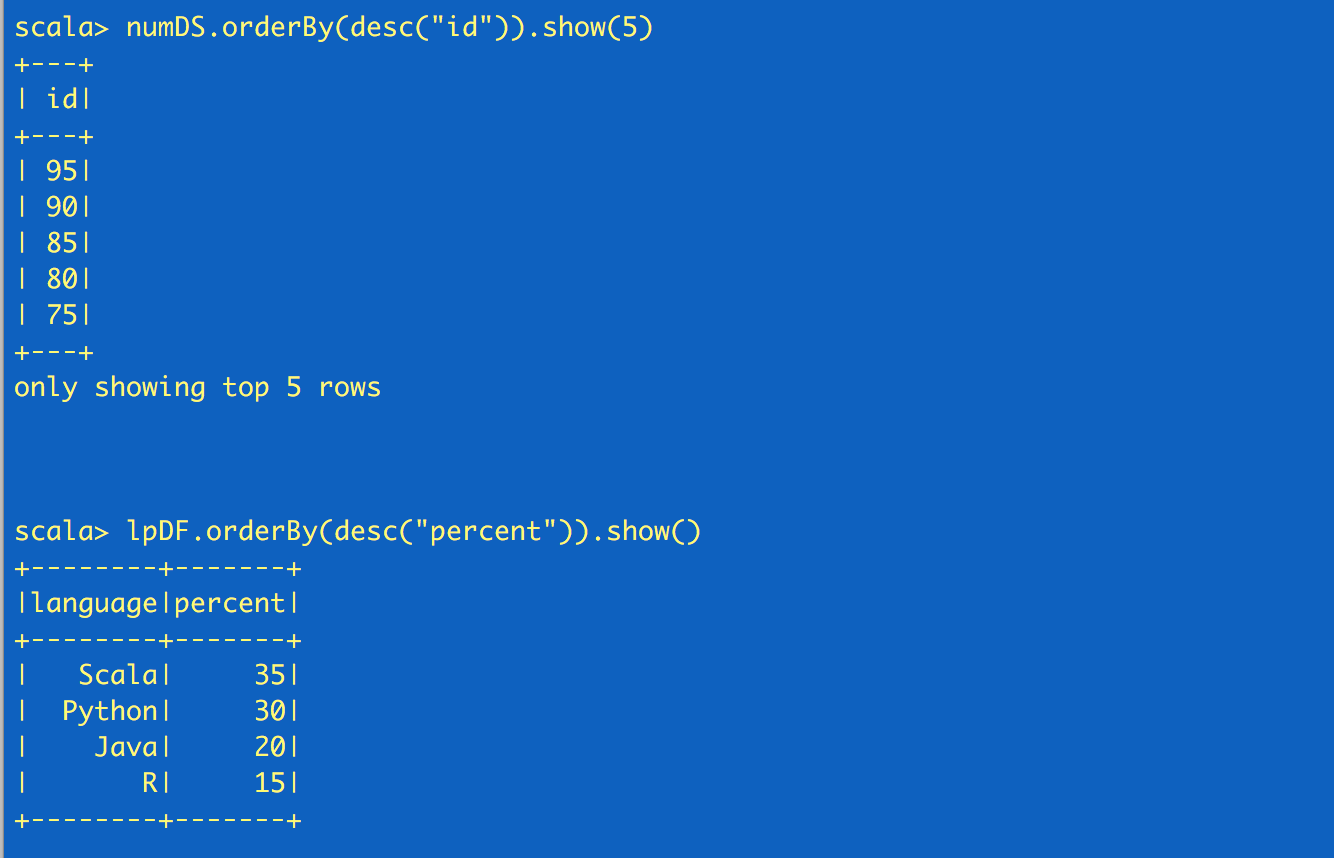
Using Spark SQL with SparkSession
Through SparkSession, you can access all of the Spark SQL functionality as you would through SQLContext. In the code sample below, we create a table against which we issue SQL queries.
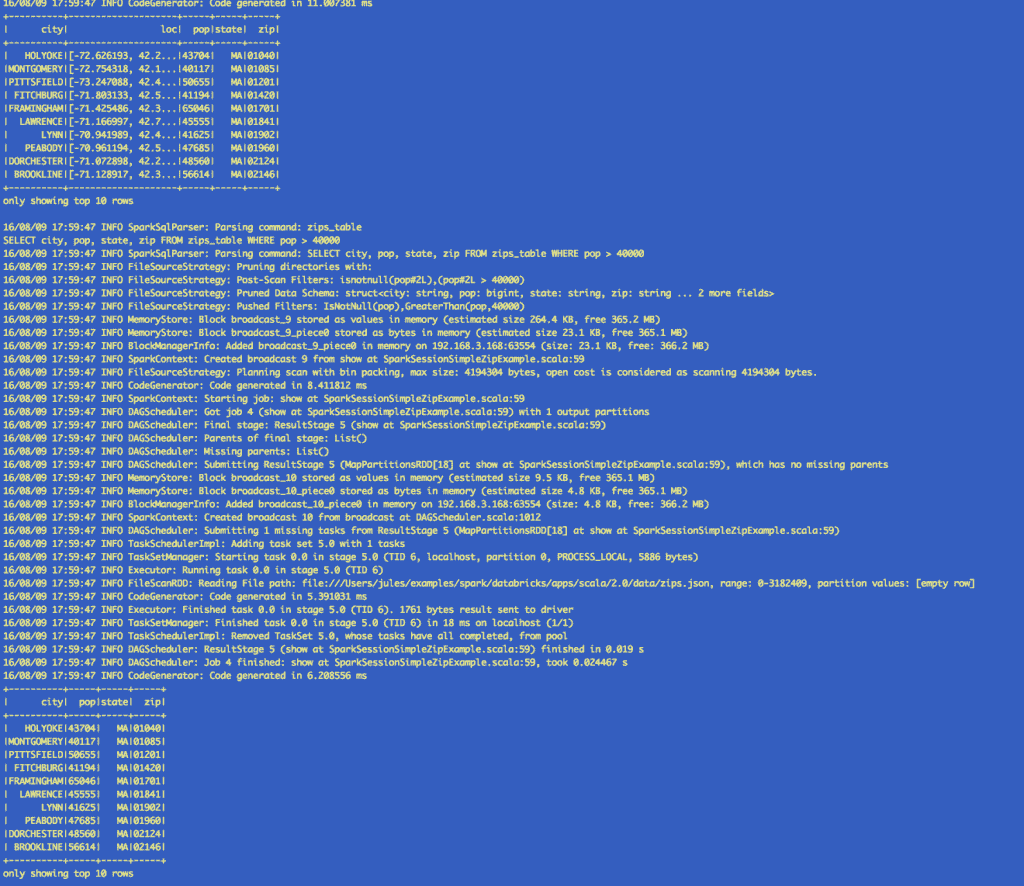
Saving and Reading from Hive table with SparkSession
Next, we are going to create a Hive table and issue queries against it using SparkSession object as you would with a HiveContext.
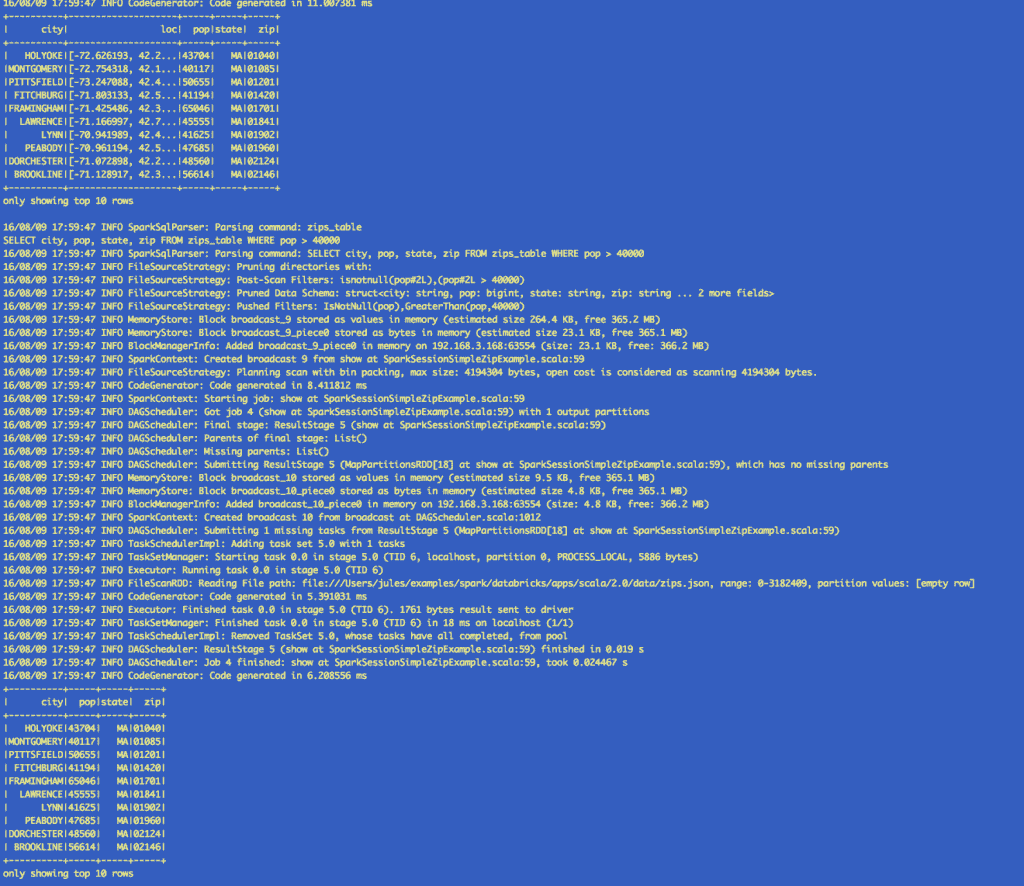
As you can observe, the results in the output runs from using the DataFrame API, Spark SQL and Hive queries are identical.
Second, let’s turn our attention to two Spark developer environments where the SparkSession is automatically created for you.
SparkSession in Spark REPL and Databricks Notebook
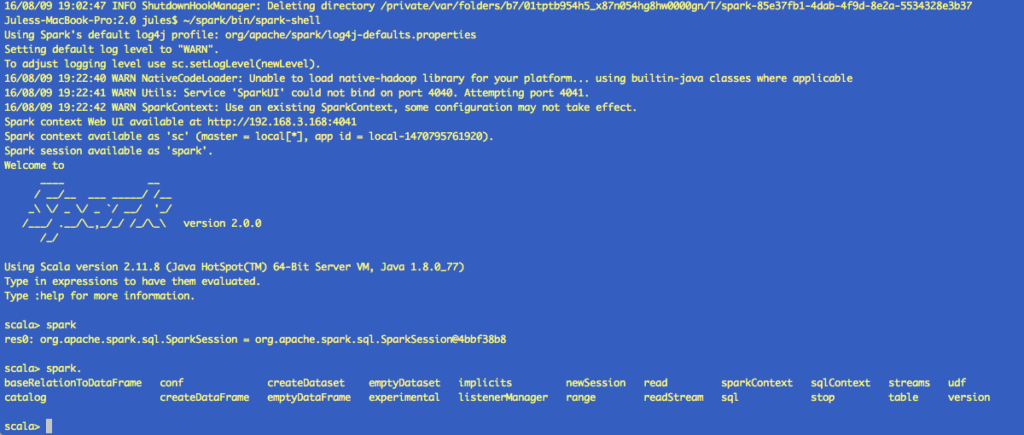
First, as in previous versions of Spark, the spark-shell created a SparkContext (sc), so in Spark 2.0, the spark-shell creates a SparkSession (spark). In this spark-shell, you can see spark already exists, and you can view all its attributes.
Second, in the Databricks notebook, when you create a cluster, the SparkSession is created for you. In both cases it’s accessible through a variable called spark. And through this variable you can access all its public fields and methods. Rather than repeating the same functionality here, I defer you to examine the notebook, since each section explores SparkSession’s functionality—and more.
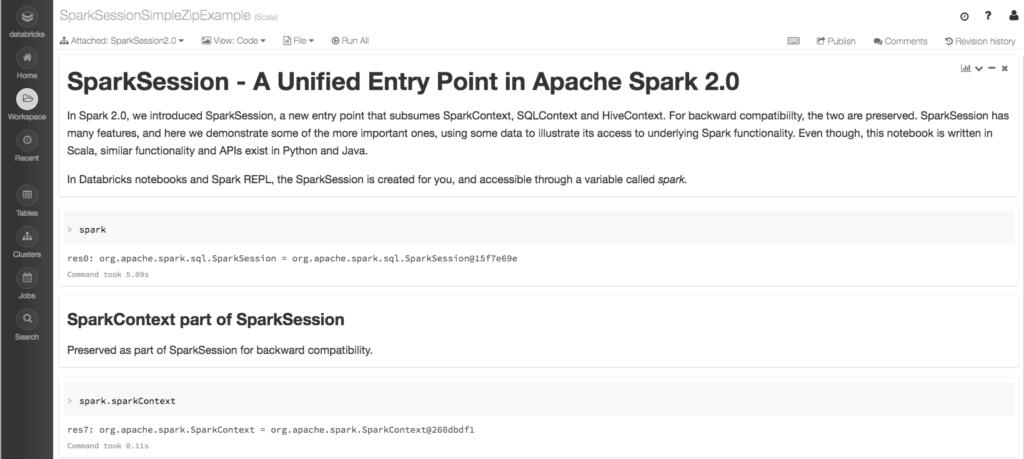
You can explore an extended version of the above example in the Databricks notebook SparkSessionZipsExample, by doing some basic analytics on zip code data. Unlike our above Spark application example, we don’t create a SparkSession—since one is created for us—yet employ all its exposed Spark functionality. To try this notebook, import it in Databricks.
SparkSession Encapsulates SparkContext
Lastly, for historical context, let’s briefly understand the SparkContext’s underlying functionality.
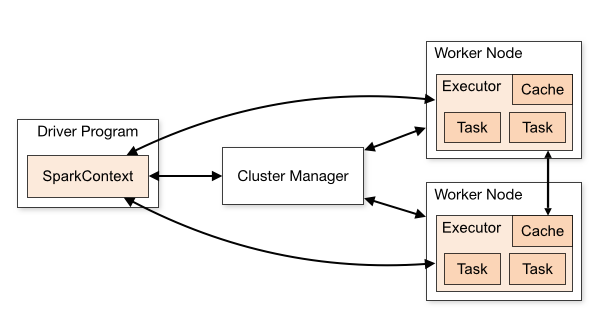
As shown in the diagram, a SparkContext is a conduit to access all Spark functionality; only a single SparkContext exists per JVM. The Spark driver program uses it to connect to the cluster manager to communicate, submit Spark jobs and knows what resource manager (YARN, Mesos or Standalone) to communicate to. It allows you to configure Spark configuration parameters. And through SparkContext, the driver can access other contexts such as SQLContext, HiveContext, and StreamingContext to program Spark.
However, with Spark 2.0, SparkSession can access all aforementioned Spark’s functionality through a single-unified point of entry. As well as making it simpler to access DataFrame and Dataset APIs, it also subsumes the underlying contexts to manipulate data.
In summation, what I demonstrated in this blog is that all functionality previously available through SparkContext, SQLContext or HiveContext in early versions of Spark are now available via SparkSession. In essence, SparkSession is a single-unified entry point to manipulate data with Spark, minimizing number of concepts to remember or construct. Hence, if you have fewer programming constructs to juggle, you’re more likely to make fewer mistakes and your code is likely to be less cluttered.
What's Next?
This is the first in the series of how-to blog posts on new features and functionality introduced in Spark 2.0 and how you can use them on the Databricks just-time-data platform. Stay tuned for other how-to blogs in the coming weeks.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.