Oil and Gas Asset Optimization with AWS Kinesis, RDS, and Databricks
by Don Hillborn
The key to success is consistently making good decisions, and the key to making good decisions is having good information. This belief is the main impetus behind the explosive interest in Big Data. We all know intuitively that access to more data presents the potential to obtain better data and therefore better decisions, yet more data in-and-of itself does not necessarily result in better decisions. We must also sift through the data and discover the good information. Doing so effectively is especially important in capital intensive industries.
The oil and gas industry is an asset-intensive business with capital assets ranging from drilling rigs, offshore platforms and wells to pipelines, LNG terminals, and refineries (Figure 1). These assets are costly to design, build, operate, and maintain. Analysis of the financial statements of the five super-majors (BP, ConocoPhillips, ExxonMobil, Shell, Total) shows that plant, property and equipment on average accounts for 51% of total assets. Effectively managing these assets requires oil and gas industry to leverage advanced machine learning and analytics on extreme large volumes of data, in batch and real-time. Apache Spark is ideal for handling this type of workload and Databricks is the ideal platform for building Apache Spark solutions.
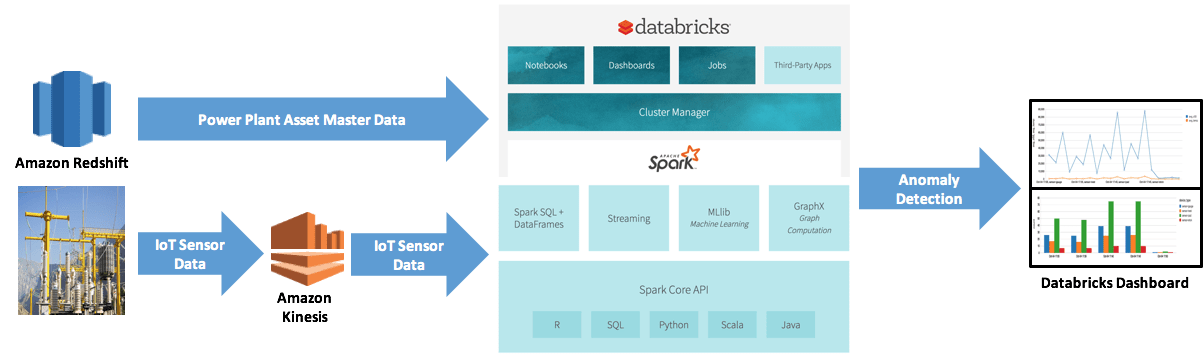
In this blog we will solve a typical problem in the oil and gas industry - asset optimization. We will demonstrate a solution with three components:
- AWS Kinesis to stream the real time data;
- AWS RDS to store our historical data;
- Databricks to process the data from RDS and Kinesis to determine the optimal asset levels.
Background on asset optimization
“Asset” refers to tangible goods used by the business to generate revenue - raw material, equipment, etc. Business operations consume assets (i.e., wearing down a piece of equipment), and must replenish them to continue revenue generation. The estimation of timing and quantity of the replenishment is the heart of asset optimization because errors are costly: revenue stops flowing if the business runs out of raw materials, while excess stockpiles incur holding costs. Ideally, asset optimization accurately determines the correct asset levels based on analytics of near real-time consumption data. The goal is to precisely estimate how much stock will be used in the time it takes for an order to arrive with pinpoint accuracy.
Asset optimization example
In the capital intensive oil and gas industry, every single hour of inefficient asset operation or unscheduled downtime cost millions. In the current Internet-of-Things (IoT) Big Data era, asset optimization focuses on continuously monitoring key operating characteristics of assets and applying advanced machine learning to maximize asset performance and minimize unplanned outages. That is where Big Data and advance analytics come in. The remainder of the blog we will look at a power generation plant example, where we monitor asset meters in real-time and model key measurements to determine whether assets are functioning optimally.
We model this by fitting a distribution to the limited lead time data we have and then sampling from that distribution. Fitting the distribution is the slowest part as it must be done numerically using Markov chain Monte Carlo (MCMC), for our asset this requires a loop of 100,000 iterations which cannot be done in parallel. This whole process must be done for each material in the data set, depending on the plant this can be 3,000+. Each material can be analyzed independently and in parallel.
Let’s see how we can do this with AWS Kinesis, RDS, and Databricks together (Note: You can also see the sample code in a Databricks notebook).
Streaming sensor readings with AWS Kinesis
Step 1: Import the proper Kinesis Libraries.
This example assumes a Spark 2.0.1 (Scala 2.11). In this particular notebook, make sure you have attached Maven dependencies spark-streaming-kinesis for same version of Spark as your cluster and corresponding kinesis-client library.
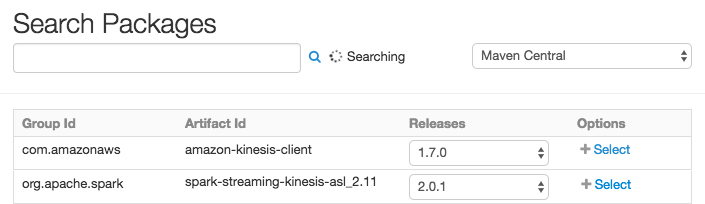
Step 2: Configure your Kinesis Stream.
Step 3: Define the function that consumes the Stream.
This function consumes a dummy stream that we have created for the sake of demonstrating Kinesis. The data that we use latter is staged as JSON files.
Storing historical data in AWS RDS
Let's connect to a relational database to look at our master data and choose the Power Plant we want to create our first model for. We will be using Redshift as our database but the steps are essentially the same for connecting to any database. For our simulation, Redshift is where master data regarding the assets is stored. In the real world, this data could be stored in any relational database.
Step 1: Create a DataFrame from an entire Redshift table

Step 2: Create a Temporary View

Step 3: Select and View list of Power Plants
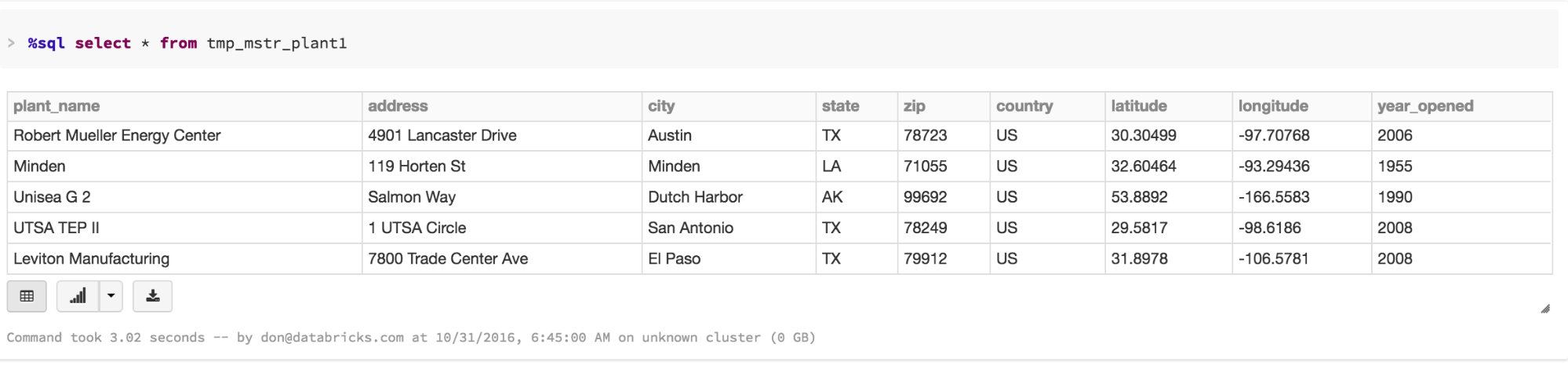
We can use ANSI SQL to explore our master data and decide what asset we would like to use for our initial analysis.
Monitoring and anomaly detection with Databricks
Step 1: Let's Load Our Data
Source measurement data from staged JSON data. In the real world, this would be sourced directly from Kinesis or another streaming technology as I showed with the dummy example above.
Load staged data from JSON files:
Define a schema for the JSON Device data so that Spark doesn't have to infer it:
Read the JSON files from the mounted directory using the specified schema. Providing the schema avoids Spark to infer Schema, hence making the read operation faster:
Step 2: Let’s Explore Our Data

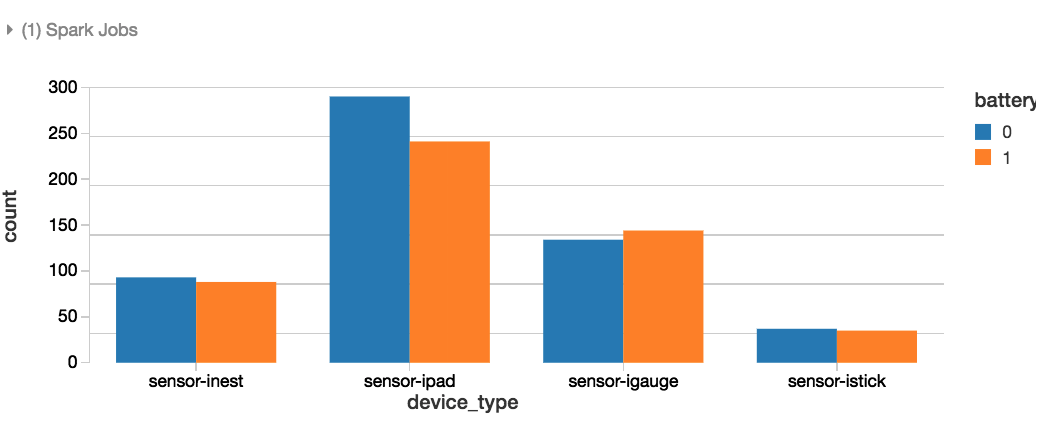
Step 3: Visualize our Data
Step 4: Stream Processing
Read the stream.
Step 5: Monitor the Stream in Real Time
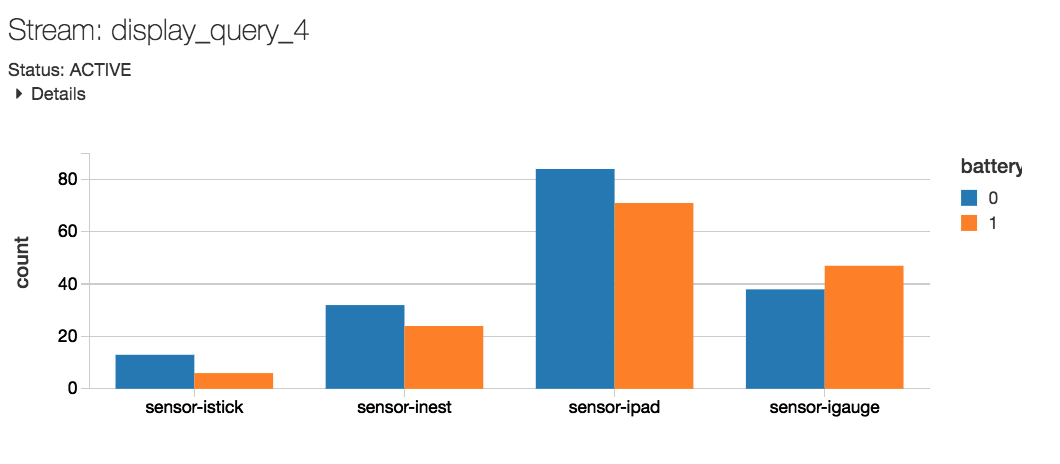
Step 6: Model the Data and Optimize the Asset
We have staged some sensor data as a CSV. In the real world, you would read this off the stream as I have shown above. Lets create a temporary table we will use in our analysis.
The next step is to prepare the data. Since all of this data is numeric and consistent this is a simple task for us today. We will need to convert the predictor features from columns to Feature Vectors using the org.apache.spark.ml.feature.VectorAssembler. The VectorAssembler will be the first step in building our ML pipeline.
The linear correlation is not as strong between Exhaust Vacuum Speed and Power Output but there is some semblance of a pattern. Now let's model our data to predict what the power output will be given a set of sensor readings.
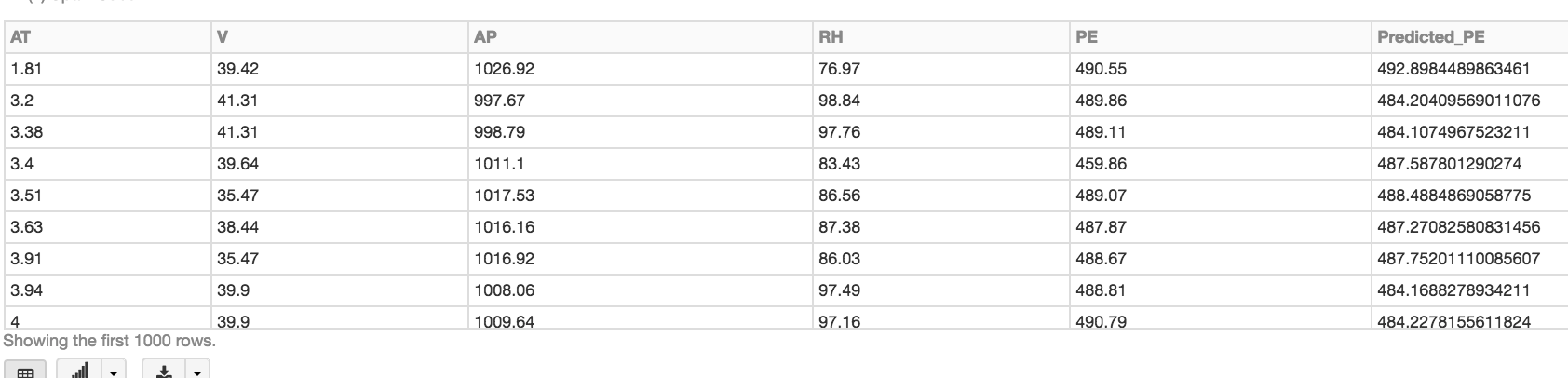
Now that we have real predictions we can use an evaluation metric such as Root Mean Squared Error to validate our regression model. The lower the Root Mean Squared Error, the better our model.
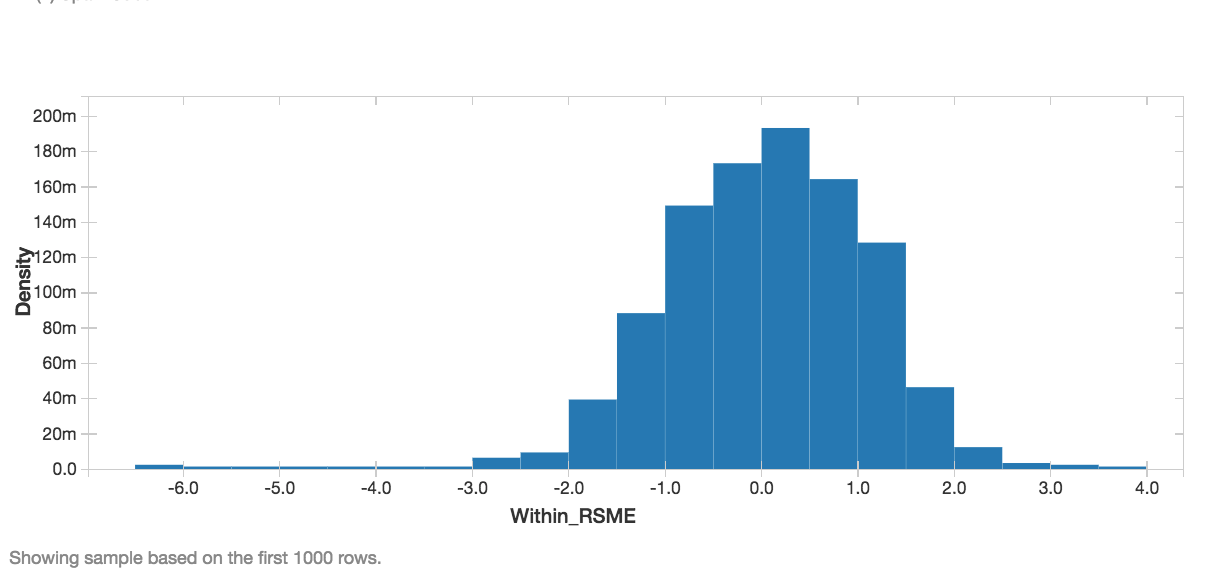
Now we can display the RMSE as a Histogram. Clearly this shows that the RMSE is centered around 0 with the vast majority of the error within 2 RMSEs.
As you can see the Predictions are very close to the real data points. Now we can predict the optimal operating parameters for this plant and apply this model to other plants in real-time.
What’s Next
The example code we used in this blog is available as a Databricks notebook, you can try it with a free trial of Databricks.
This just one of many examples of how Databricks can seamlessly work with other AWS components to deliver advanced solutions. To learn how Databricks helped an energy company analyze IoT data, check out our case study with DNV GL. If you want to get started with Databricks, sign-up for a free trial or contact us.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.