Integrating Your Central Apache Hive Metastore with Apache Spark on Databricks
Databricks provides a managed Apache Spark platform to simplify running production applications, real-time data exploration, and infrastructure complexity. A key piece of the infrastructure is the Apache Hive Metastore, which acts as a data catalog that abstracts away the schema and table properties to allow users to quickly access the data.
The Databricks platform provides a fully managed Hive Metastore that allows users to share a data catalog across multiple Spark clusters. We realize that users may already have a Hive Metastore that they would like to integrate with Databricks, so we also support the seamless integration with your existing Hive Metastore. This allows Databricks to integrate with existing systems such as EMR, Cloudera, or any system running a Hive Metastore. This blog outlines the technical details.
Apache Hive Metastore Background
Hive is a component that was added on top of Hadoop to provide SQL capabilities to the big data environment. It began with a Hive client and a Hive Metastore. Users would execute queries that were compiled into a MapReduce job. To abstract the underlying data structures and file locations, Hive applied a table schema on top of the data. This schema is placed in a database and managed by a metastore process.
The above examples show that the metastore abstracts the underlying file types, and allows the users to interact with the data at a higher level.
Traditionally, Hadoop clusters will have one Hive Metastore per cluster. A cluster would be composed of Apache HDFS, Yarn, Hive, Spark. The Hive Metastore has a metastore proxy service that users connect to, and the data is stored in a relational database. Hive supports a variety of backend databases to host the defined schema, including MySql, Postgres, Oracle.
Supported Apache Hive Versions
Apache Spark supports multiple versions of Hive, from 0.12 up to 1.2.1. This allows users to connect to the metastore to access table definitions. Configurations for setting up a central Hive Metastore can be challenging to verify that the corrects jars are loaded, the correction configurations are applied, and the proper versions are supported.
Integration How-To
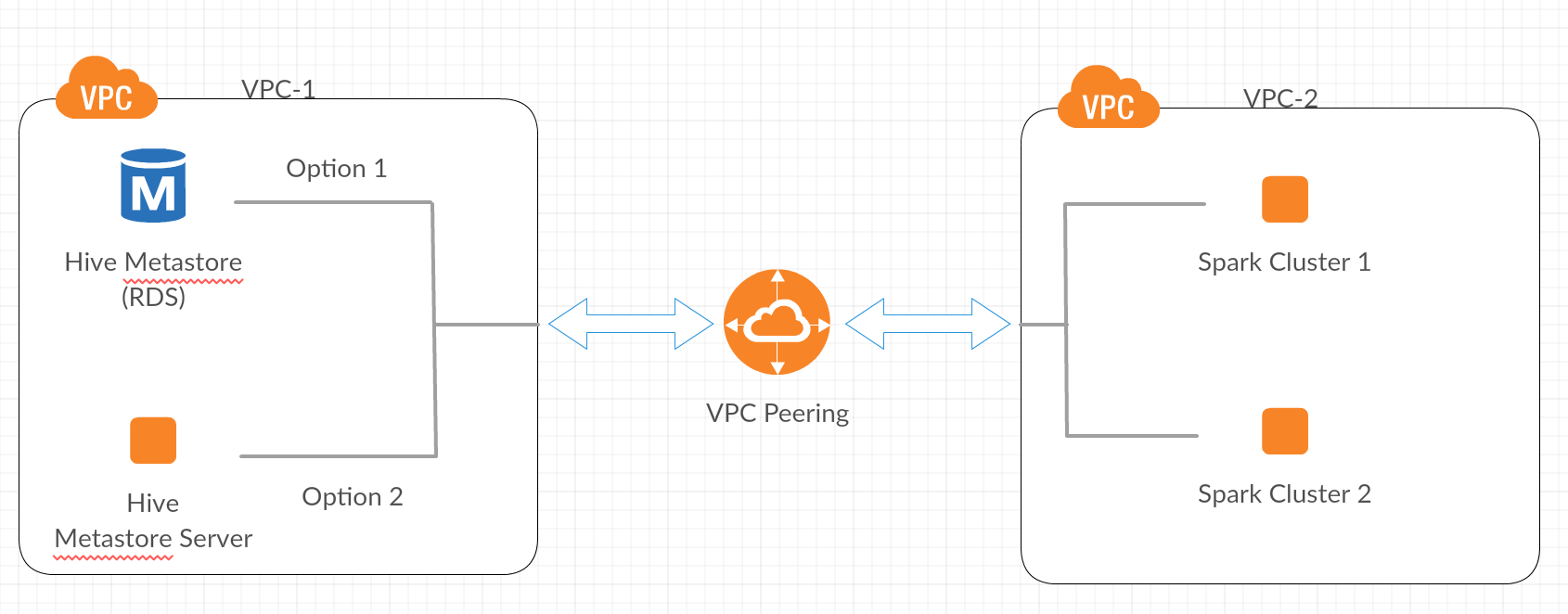
In the cloud, clusters are viewed as transient compute resources. Customers want the flexibility and elasticity of a cloud environment by leveraging the fact that compute resources can be shut down. One item that needs to be highly available is the Hive Metastore process. There are two ways to integrate with the Hive Metastore process.
- Connect directly to the backend database
- Configure clusters to connect to the Hive Metastore proxy server
Users follow option #2 if they need to integrate with a legacy system. Note that this has additional costs in the cloud as the proxy service needs to run 24x7 and only acts as a proxy. Option #1 removes the overhead of proxy services and allows a user to connect directly to the backend database. We can leverage AWS’ hosting capabilities to maintain this as an RDS instance. Option #1 is recommended and discussed below. For instructions on option #2, read our documentation link at the end.
Proposed Configuration Docs
The configuration process will use Databricks specific tools called the Databricks File System APIs. The tools allow you to create bootstrap scripts for your cluster, read and write to the underlying S3 filesystem, etc. Below is the configuration guidelines to help integrate the Databricks environment with your existing Hive Metastore.
The configurations below use a bootstrap script to install the Hive Metastore configuration to a specific cluster name, e.g. replace ${cluster-name} with hive-test to test central metastore connectivity.
Once tested, you can deploy the init script in the root directory to be configured for every cluster.
Configuration
A Word of Caution
The configurations help bootstrap all clusters in the environment, which can lead to an outage if changes are made to the metastore environment.
- Broken network connectivity
- Changes to the underlying Hive version
- Changes to metastore credentials
- Firewall rules added to the metastore
To temporarily resolve the issue, you can use the Databricks Rest API to collect the current contents of the bootstrap script and remove it while you work on fixing the issue.
If you want to configure clusters to connect to the Hive Metastore proxy server, you can find instructions in our Hive Metastore online guide.
What’s Next
Databricks is a very fast and easy way to start coding and analyzing data on Apache Spark. If you would like to get started with Spark and have an existing Hive Metastore you need help to integrate, you can get in touch with one of the solution architects through our Contact Us page. To get a head start, sign up for a free trial of Databricks and try out some of the live exercises we have in the documentation.
If you need help with configuring VPC peering within Databricks, check out our VPC peering documentation.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.