Integrating Apache Spark with Cucumber for Behavioral-Driven Development
by Aaron Colcord and Zachary Nanfelt
This is a guest blog from FIS Global
One of the most difficult scenarios in data processing is ensuring that the data is correct and expected. We can take a variety of testing methods to solve this, but often these methods limit the amount of collaboration in a team and don’t directly answer the question, “How do I prove everything works?”
Using Behavior-Driven Development (BDD) patterns to develop our transformations can enable the entire team to participate and focus on the results. The Cucumber project (Cucumber.io) provides an easy to use framework for implementing BDD methods into most projects.
When combining Apache Spark for data processing and Cucumber (Cucumber.io), we make a compelling combination that maintains the scale of a system and can prove that the data is being handled correctly. This not only enables the development team but can bring in other means to successfully test scenarios that have been typically very hard to prove such as Machine Learning.
Why Cucumber and Apache Spark?
The majority of software today is done collaboratively in an agile fashion. This means we get a healthy mix of professionals with varying perspectives trying to play the team sport of building software. One of the biggest problems projects suffer from is low-quality communication between engineers and the domain experts.
Cucumber allows us to write a portion of our software in a simple, language-based approach that enables all team members to easily read the unit tests. Our focus is on detailing the results we want the system to return. Non-Technical members of the team can easily create, read, and validate the testing of the system.
Often Apache Spark is one component among many in processing data and this can encourage multiple testing frameworks. Cucumber can help us provides a consistent unit testing strategy when the project may extend past Apache Spark for data processing. Instead of mixing the different unit testing strategies between sub-projects, we create one readable agile acceptance framework. This is creating a form of ‘Automated Acceptance Testing’.
Best of all, we are able to create ‘living documentation’ produced during development. Rather than a separate Documentation process, the Unit Tests form a readable document that can be made readable to external parties. Each time the code is updated, the Documentation is updated. It is a true win-win.
Our Recipe for Success
In order to be successful, we need a recipe.
Successful BDD Data Transformation Project
1 Cup of Apache Spark
1 Cup of Cucumber.io
2 Cups of IntelliJ (Substitute with Eclipse if you find IntelliJ too salty)
½ Cup of Databricks.
First, add to your Java-Based Project Maven File.
We also need to setup the Junit Runner to recognize Cucumber.
For added fun, dependency Injection can add some spice to your recipe. While Scala is available as a project to use for Spark, We have found that the Java project works even better for Cucumber. The JVM allows us to interact with each language’s interface.
We need to create a .feature file, this is a file written in an executable language called Gherkin. This will have a simple format:
Feature: Eating something good
Scenario: Eat some ice cream
Given an ice cream cone
When I eat the ice cream cone
Then I should be happy
We can notice that there are some keywords at work here: Given, When, Then, Feature, and Scenario. These keywords can be used in any way, the standardization around the few keywords is to enable readability. The feature file really tells the reader what is being done.
You will want to mix in step definitions next. The step definitions are the how or basically the Java code. A cool benefit is that Cucumber can give you the methods to put into the step definitions based on the feature file.
The final and most important step is to actually write a data transformation. For that, we need our killer ingredient. Apache Spark.
What makes Apache Spark killer in our data processing is what it changes fundamentally. Up until now, data processing was a batch process for us. We would put the data in, Wait a while, and then have it processed. At the end of the process, which could be some time of waiting, we could validate the results. We have many types of ‘unit testing’ around this approach, but all were very weak and often ignored. Quality was assumed in the system and not guaranteed.
With Apache Spark, We are able to perform the data processing and verify it immediately. The fact that we have guaranteed speed pushes the boundary. We are able to wrap the data processing in uniform testing frameworks, guarantee speed, and know the results immediately. We can now prove and guarantee quality. When you extend this to the utility of Spark to do machine learning tasks, which has been traditionally very hard and timely to prove, the ability to move fast accelerates.
Data Processing Scenario
We choose to use a rather simple, but perhaps common scenario. When data producers generate data, We often care about when the data was generated. For our purposes, We will assume that the time is always recorded in Epoch Time (Unix time) and the machine generating it is perfectly in tune with all known time synchronizations.
Our consumers, users inside our walls, care about having time in a more readable fashion. For simplicity sake, we will make the assumption that they always want the time to occur in Pacific Daylight Time.
When, Given, Then, AND
Gherkin is our language parser that provides a lightweight structure for documenting ‘executable specifications’. Its primary goal is readability. For this scenario, we will write the following unit test:
Stepping It Up
This is where the real magic occurs. Our Gherkin file is written and is clearly explainable to our team. So we need to execute it and find out how our plainly understandable file will execute a unit test. So if we run it, We will get back some output:
The Cucumber framework has auto-generated the method we need to implement. Now we need to hook our feature file together with the actual calls that are running the unit tests. So let’s fill it in.
This seems like extra work over simply implementing our unit test in JUnit. But if we had implemented in JUnit alone, our tests would be fully readable only to the developers of the system. The hooks were truly not a lot of extra work, and Cucumber actually helped out by creating the stubs needed to complete the work.
What we did do is create a means to document our system for the users of the system in an agile fashion. We can remove the extra work to document elsewhere because we already did the work. We could also do variations of the process and ask our expert quality folks to write our Gherkin file and then fill in the step hooks later.
Using Cucumber with Databricks
Now let’s extend this scenario into Databricks. Databricks is an excellent platform for the Data Scientist through its easy-to-use notebook environment. The true value shines through in having a platform built by the team that created Apache Spark.
Our Data Scientists can spend a lot of time prepping the data. They are applying the business rules of the company and cleaning the data for preparation. We begin losing the value of these statistical masters by having them mired inside the minutia. The data scientist should be focusing in on unlocking insights from the data, but often we have business-specific logic that represents how the data was formed. We want actionable insights, not encouraging a ‘spreadmart’ of varying observations based on the preparation technique used.
Now bring forward our above scenario. We can bring data alignment to our scientist by codifying the preparation rules into a compilable jar. This logic can easily be wrapped around by Cucumber. The benefit of unit testing is fantastic, but we now have a new pair of eyes looking at our code. These eyes may not be able to read the arcane Java as their preferred language. Because we used a ubiquitous language, The data scientist can now look at the way the module was built and tested. They can build and validate our scenarios!
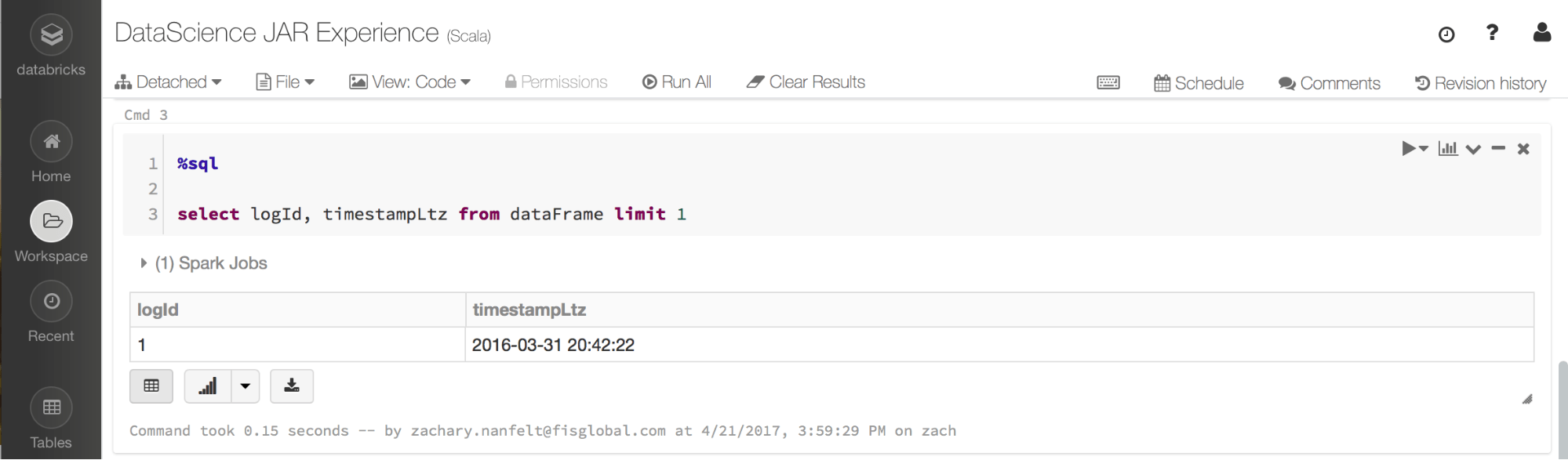
Through the Databricks notebooks, we can load and prepare the data through our compiled jars and switch to a different preferred language for the scientists. Since Databricks allows us to attach jars to a cluster, we can ensure that the business logic is well tested and understood and then extend it into Databricks. This allows an agile process to discover new data value, while ensuring complex business logic is well tested.
Steps:
- Create local jar using
mvn packagewhich has the great benefit of running the Cucumber tests to ensure data quality. - Upload jar to Databricks as a library and attach the library to the cluster (https://www.databricks.com/blog/2015/07/28/using-3rd-party-libraries-in-databricks-apache-spark-packages-and-maven-libraries.html).
- Import class, access public methods you are interested in using, then create DataFrame view to access from any language.
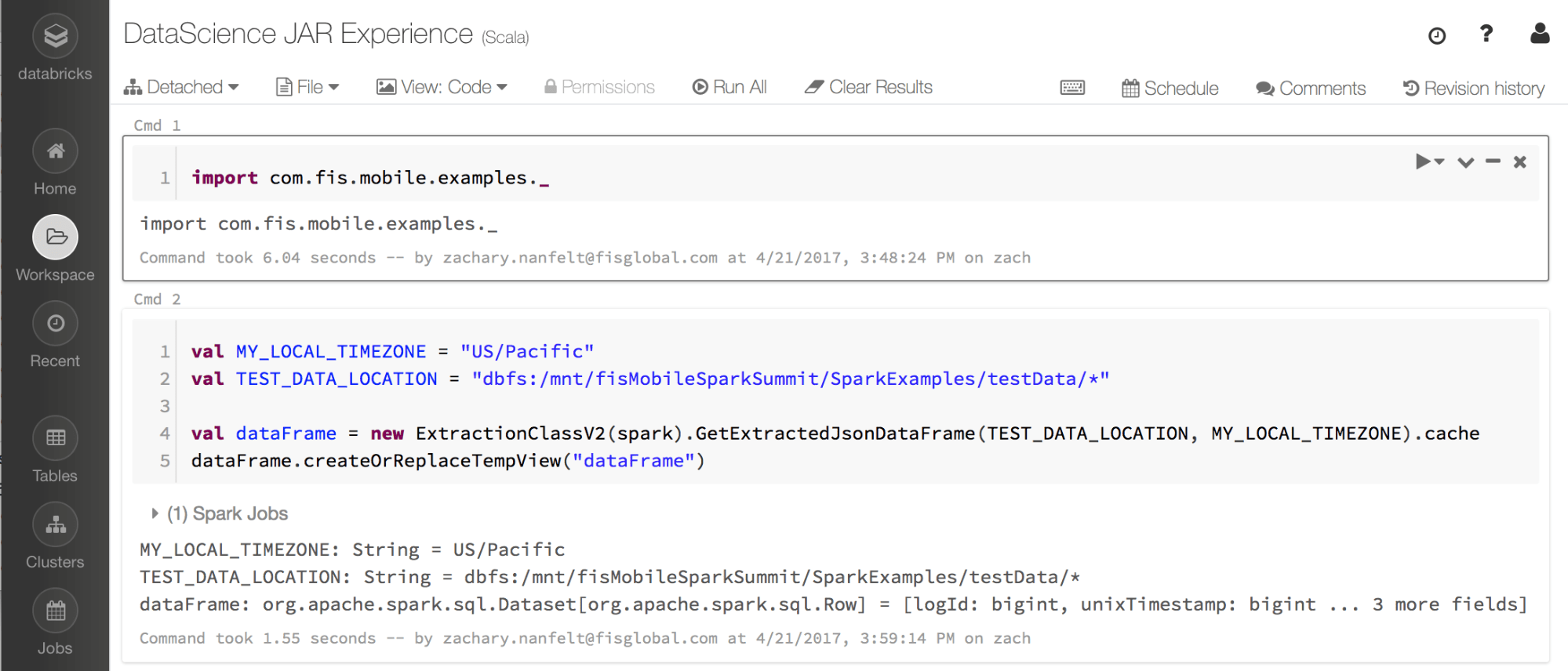
- Do your data science thing in the language of your choice knowing that the data sources are prepped tested.
Lessons Learned
Databricks is a powerful unifying platform for data processing that fosters a collaborative environment during the development process. We showed how we can not only unify the expensive data preparation work of the Data Scientist but also enable the preparation work to be easily validated.
We are also able to unify multiple data processing components that support Apache Spark under one readable unit testing framework and produce ‘Living Documentation’ about how the system works. Everyone from the developer to the tester all the way up to the executive stakeholders can now read and collaborate on the system tests and understand its behavior.
The true value comes when documentation is created at development time and not done as a separate process. Your project becomes truly oriented around the results in a fully-agile fashion.
Are you interested in hearing more about Spark and BDD testing? Come to our session at the Spark Summit 2017!
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.