4 SQL High-Order and Lambda Functions to Examine Complex and Structured Data in Databricks
by Jules Damji
Read Rise of the Data Lakehouse to explore why lakehouses are the data architecture of the future with the father of the data warehouse, Bill Inmon.
Try this notebook on Databricks
A couple of weeks ago, we published a short blog and an accompanying tutorial notebook that demonstrated how to use five Spark SQL utility functions to explore and extract structured and nested data from IoT Devices. Keeping with the same theme, I want to show how you can put to a wide use of the four high-order functions introduced in SQL as part of Databricks Runtime Beta 3.0.
Knowing why offers insight but doesn’t make you productive. Knowing how does. Whereas our in-depth blog explains the concepts and motivations of why handling complex data types such as arrays with high-order functions are important in SQL, this blog is a preamble to how as a notebook tutorial to use high-order functions in SQL in processing structured data and arrays in IoT device events.
In particular, you can put them to good use if you enjoy functional programming. Far more important, these high-order functions offer three benefits. For instance, you don’t need to:
- unpack arrays into individual rows and apply your function and repack them;
- depend on limited built-in functions; and
- write UDFs in Scala or Python.
All can be done in SQL. For this tutorial, we will explore four SQL functions, and how you can use them to process array types:
Again, as in the previous tutorial, the takeaway from this tutorial is simple: There exist myriad ways to slice and dice nested JSON structures with Spark SQL utility functions, namely the aforementioned list. These dedicated high-order functions are primarily suited to manipulate arrays in SQL, making the code easier to write and more concise to express when processing table values with arrays or nested arrays.
To give you a glimpse, consider this nested schema that defines what your IoT events may look like coming down an Apache Kafka stream or deposited in a data source of your choice.
And its corresponding sample DataFrame/Dataset data may look as follows:
If you examine the corresponding schema in our Python notebook, you will see the nested structures: array of integers for temp and c02-level.
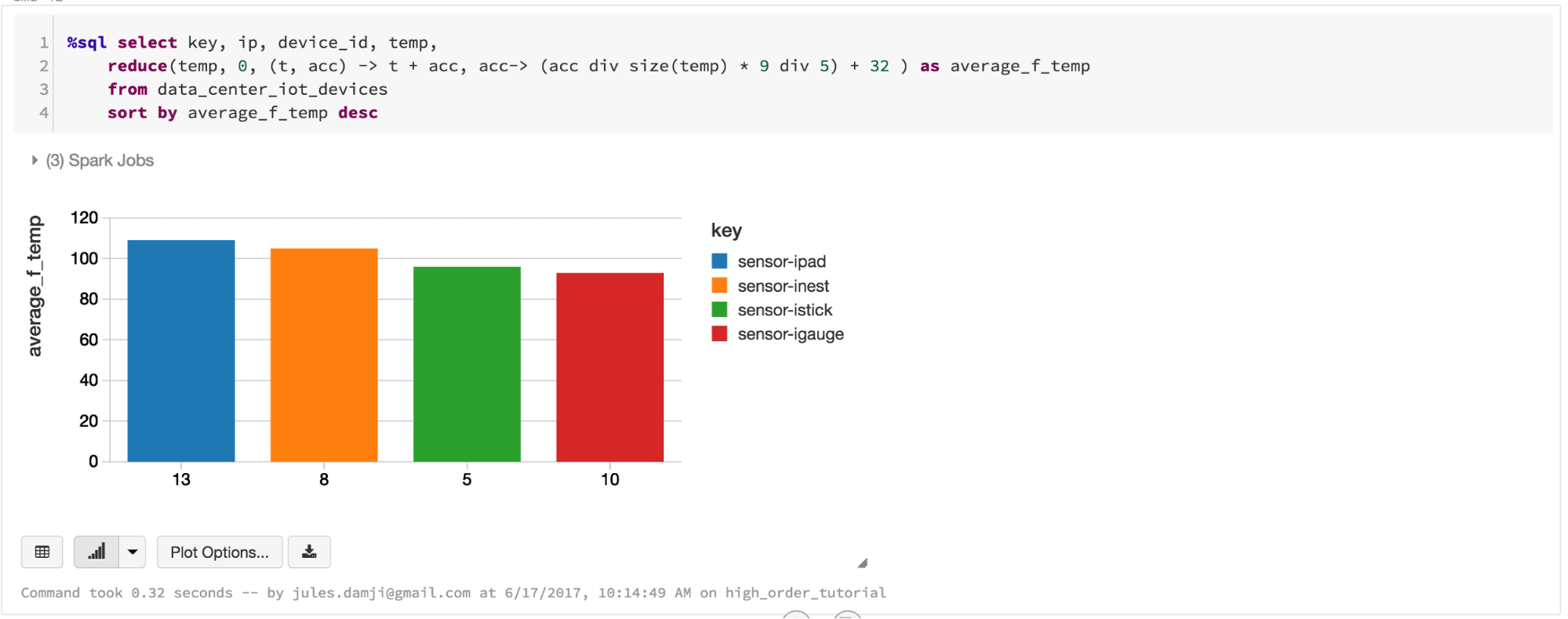
I use a sample of these JSON event data from IoT devices to illustrate how to use these SQL functions. Instead of repeating myself here what I already demonstrated in the notebook, I encourage that you explore the accompanying notebook, import it into your Databricks workspace, and have a go at it.
What’s Next
Try the accompanying tutorial on Databricks. If you have not read our previous related blog and its tutorial on Spark SQL utility functions, do read them. Also, If you don’t have a Databricks account, get one today.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.