Build, Scale, and Deploy Deep Learning Pipelines with Ease
by Sue Ann Hong and Tim Hunter
At the Spark Summit in San Francisco in June, we announced an open-source project Deep Learning Pipelines.
Deep Learning Pipelines provides high-level APIs for scalable deep learning in Python with Apache Spark, and the library leverages Spark for its two strongest facets:
- In the spirit of Spark and Spark MLlib, it provides easy-to-use APIs that enable deep learning in a few lines of code.
- It uses Spark's powerful distributed engine to scale out deep learning on massive datasets.
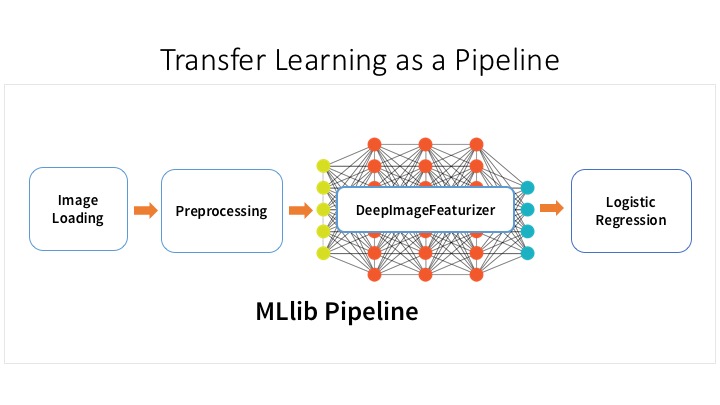
At the Spark Summit in Dublin, we will present a talk covering many aspects of Deep Learning Pipelines in a deep dive session as well as another talk on how to scale graph analytics with GraphFrames and Apache Spark. Here are our talks:
- Deep Dive into Deep Learning Pipelines
- GraphFrames: Scaling Web-scale Graph Analytics with Apache Spark
Why should you attend these sessions? If you are a data scientist or data analyst who wants to build deep learning pipelines easily and quickly or are interested in doing graph analytics at scale, then attend our talks.
Register for the Spark Summit EU today if you have not, and use Databricks code for 15% discount.
See you in Dublin!
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.