What AWS Per-Second Billing Means for Big Data Processing
Databricks, the Unified Analytics Platform, has always been a cloud-first platform. We believe in the scalability and elasticity of the cloud so that customers can easily run their large production workloads and pay for exactly what they use. Hence, we have been charging our customers at per-second level granularity.
Until last month, billing on AWS has been based in hourly increments. Recently, they moved to per-second level billing. This move from AWS coupled with Databricks’ per-second level billing enables a huge shift in the architecture for big data processing. It eliminates the need for the unnecessary complexity brought by resource schedulers like YARN in the cloud and provides a much simpler and more powerful way to run production big data workloads.
Why are resource schedulers required in the cloud?
Because of the hourly increments in billing, users spend a lot of time playing a giant game of Tetris with their big data workloads — figuring out how to pack jobs to use every minute of the compute hour. Examples:
- If a job could be run on 10 nodes and finished in 20 minutes, it was better to run it on fewer nodes so that it would take around 50 minutes. As a result, you would pay less.
- Running two 10 node jobs that took 20 minutes in parallel would cost two times more than running them sequentially.
The above problem was compounded if there were many such jobs to be run. To handle this challenge, many organizations turned to a resource scheduler like YARN. Organizations were following the traditional on-premises model of setting up one or more big multi-tenant cluster on the cloud and running YARN to bin-pack the different jobs.
What complications do resource schedulers bring?
- Resource utilization: Understanding resource utilization of a multi-tenant cluster is very hard. Users have to spend an enormous amount of time in trial and error, and must use different profiling tools to figure out the resource utilization of the different jobs to tune them.
- Resource profile: Users cannot control the profile of the resources for a particular job in a multi-tenant cluster. For example, you cannot switch from a general-purpose instance type to a compute-optimized instance type for one particular job in a multi-tenant cluster.
- Configuration: YARN exposes hundreds of configuration parameters to control and fine tune different aspects of resource management. Things can become very unwieldy and hard to debug if they are not configured properly.
The future of big data processing in the cloud
With second-level billing, using resource schedulers like YARN on the cloud is an added layer on top of cloud compute services like EC2. In fact, we believe that it is an anti-pattern in the cloud and elasticity in the cloud removes the need for this unnecessary complexity.
Hence, at Databricks, we recommend taking full advantage of the inherent elasticity of the cloud: Let each job spin up its own cluster, run the job on this new cluster, and terminate the cluster automatically once the job finishes. In other words, you can use the resource profile that matches the needs of the job. We also take care of provisioning the resources when the job requires them with the given profile and we automatically de-provision them once the job is complete.
This simple approach to running production jobs in the cloud has tremendous benefits:
- You no longer need to play Tetris with your workloads. You can just specify the resource profiles for your jobs and let them run in a parallel manner.
- You no longer need to worry about fine tuning hundreds of resource management parameters that are proxies for cost control.
- Your jobs no longer fight for resources with other jobs on the same cluster.
- Since only one job runs per cluster, you can easily understand the resource utilization and optimize your job accordingly.
- You have the freedom to experiment with different resource profiles for your job. For example, you can easily switch from a general-purpose instance type to a compute-optimized instance type and compare your job performance.
- You can easily chargeback costs to different jobs. You can even chargeback to individual runs of a job.
There is one common misconception that users initially have with this approach: isn’t having every job run on its own cluster very inefficient as they no longer share resources? The answer is a simple no. The above approach is very similar to how an application is run on YARN. We have just removed all the other unnecessary scheduling complexities. So this approach is as cost efficient as running it on YARN.
This simple approach requires some key functionalities to bridge some gaps when not using the traditional multi-tenant clusters:
- Rapid cluster startup time: Clusters in Databricks typically start up in two minutes. The majority of our customers run their production jobs this way. If you need to run a large number of short production jobs, (say five minute jobs), the startup time of two minutes can be a concern. For such applications, we recommend to pack multiple such jobs on a single Databricks persistent cluster.
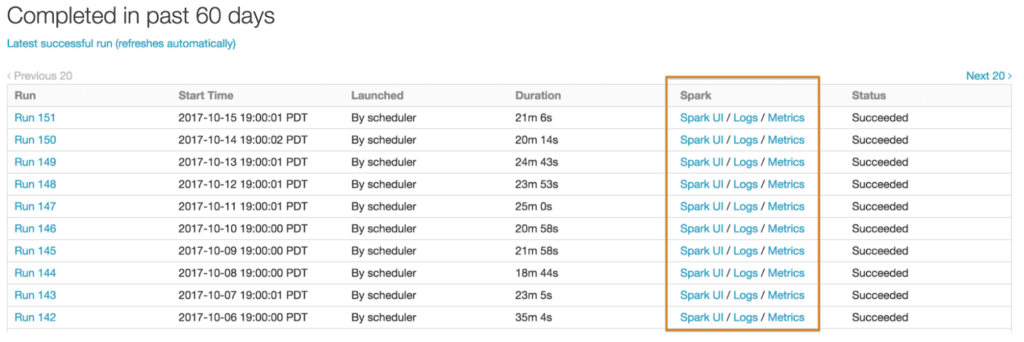
- Historical metrics and logs: After the cluster is terminated, all the logs and metrics information must be available for easy troubleshooting. In Databricks, we persist all the historical logs, Spark UI, and metrics information after the cluster is terminated and show them for every job run. We also ship the logs to an S3 bucket of your choice so that you have clear record of all the job runs.
Conclusion
With the recent announcement of AWS second-level billing, organizations can finally break the complex on-premises model of running multiple jobs on a traditional multi-tenant cluster and move towards a much simpler and more powerful model of running each production job in its own ephemeral cluster in the cloud. This model will allow data engineers and data scientists to be very productive and focus more time on working with their data instead of configuring their infrastructure for optimizing costs.
If you are interested in trying out this new model in action, you can sign up for a free trial of Databricks.
If you have any questions, you can contact us for more details.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.