Transparent Autoscaling of Instance Storage
Big data workloads require access to disk space for a variety of operations, generally when intermediate results will not fit in memory. When the required disk space is not available, the jobs fail. To avoid job failures, data engineers and scientists typically waste time trying to estimate the necessary amount of disk via trial and error: allocate a fixed amount of EBS storage, run the job, and look at system metrics to see if the job is likely to run out of disk. This experimentation - which becomes especially complicated when multiple jobs are running on a single cluster - is expensive and distracts these professionals from their real goals.
With Databricks’ unified analytics platform, you can say goodbye to this problem forever. The platform now allows instance storage to transparently autoscale independently from compute resources so that data scientists and engineers can focus on finding the correct algorithms rather than the correct amount of disk space. As part of the Databricks Serverless infrastructure, storage auto-scaling makes big data simple for all users.
Why is instance storage required?
When Apache Spark processes data, it needs to generate and store intermediate results for reliability and performance. Typically, they are stored in memory and when memory gets filled, they are spilled to disk. Some examples of intermediate data that are stored in memory backed by disk include:
- Shuffle: When data is exchanged between executors as the result of operations like joins and aggregations, Spark stores that data as shuffle files.
- Broadcast caching: Spark sometimes broadcasts data to different workers so that they can be stored in the worker nodes and accessed quickly when needed.
- Data caching: Spark caches data that is frequently accessed from S3 in the local disk of the cluster. This is done to boost I/O performance.
Problems with provisioning instance storage
- Hard to predict: The amount of disk space that Spark will require has an indirect relationship to the size of the data being operated on: it depends on factors like data compression, data distribution, and the number of joins, aggregates and sorts in the job. As a result, it is very difficult for end users to predict in advance how much disk space they will need. Data engineers typically spend time in trial and error to come up with the right amount of disk space for their job. This process is extremely painful as the trial and error approach can take sometimes days to get a large Spark job working without any errors. Because it is so difficult to estimate, we commonly see users "play it safe" by provisioning significantly more disk space than they think will be necessary, which increases costs.
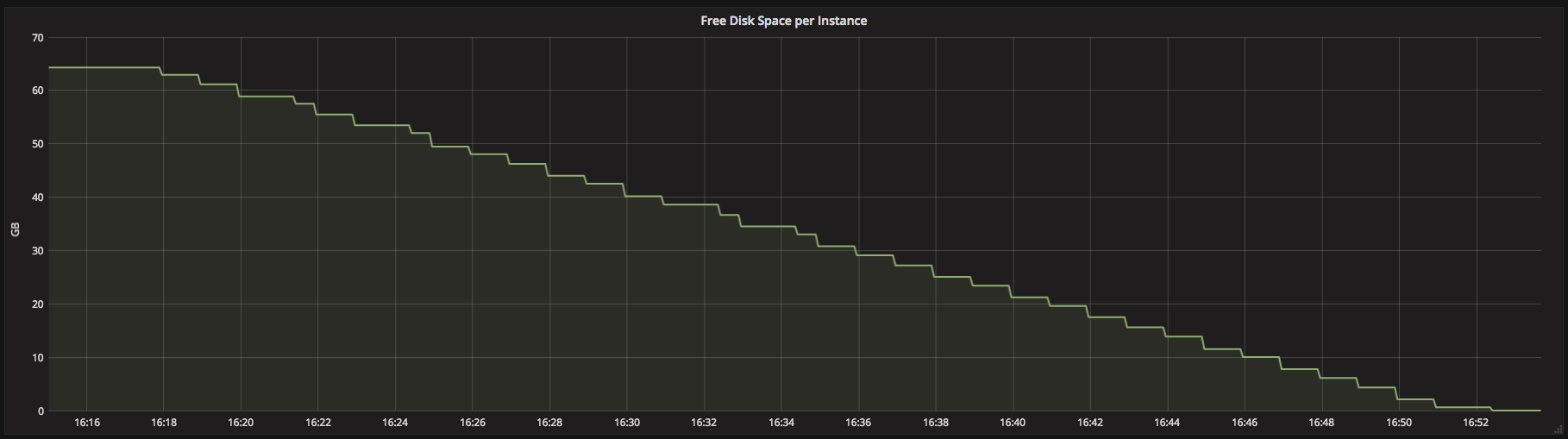
Figure 1. Graph showing the disk space for an instance getting filled. When the free disk space reaches 0, the job will fail.
- Data skew and disk utilization: Within a single job, some workers may require more disk space than others. For example, a join of two data sets may leave some workers with many more rows than other workers if the join keys are not evenly distributed. In a world of statically-allocated disk space, a data engineer must give every worker enough disk space to cover the load of the most-burdened worker. This is not optimum utilization and will be expensive when processing large volumes of data.
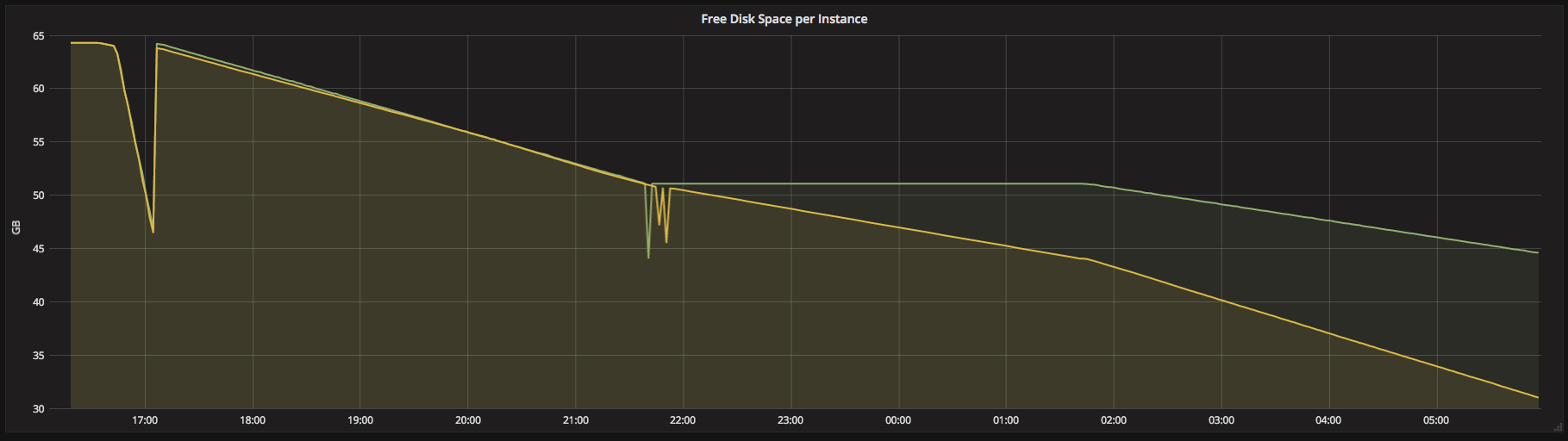
Figure 2. Graph showing the free disk space for 2 instances in the same cluster. Because of data skew, one of the instance’s disk space gets filled while the other still has disk space left.
- Encryption of data at rest: Security compliance typically requires all data at rest to be encrypted. Today, Amazon does not provide an easy way to encrypt instance local storage by default. To comply with their organization's security requirements, we typically see users provision encrypted EBS volumes and make sure Spark does not use the local disks attached to the instances. For instance types with highly-performant disks, this leads to a loss in performance.
Autoscaling Instance Storage
Databricks’ new autoscaling instance storage leverages Logical Volume Manager (LVM) in Linux and the ability to add storage resources (e.g. EBS in AWS) to running instances in order to dynamically increase available storage without adding more instances. It addresses all three of the above problems:
- Automatic Provisioning: As an instance runs out of free disk space, we will automatically provision and attach new EBS volumes to the instance (the volumes will be automatically released when the load on the cluster reduces and we spin down the instances). Users no longer need to worry about how much disk space is required for their jobs.
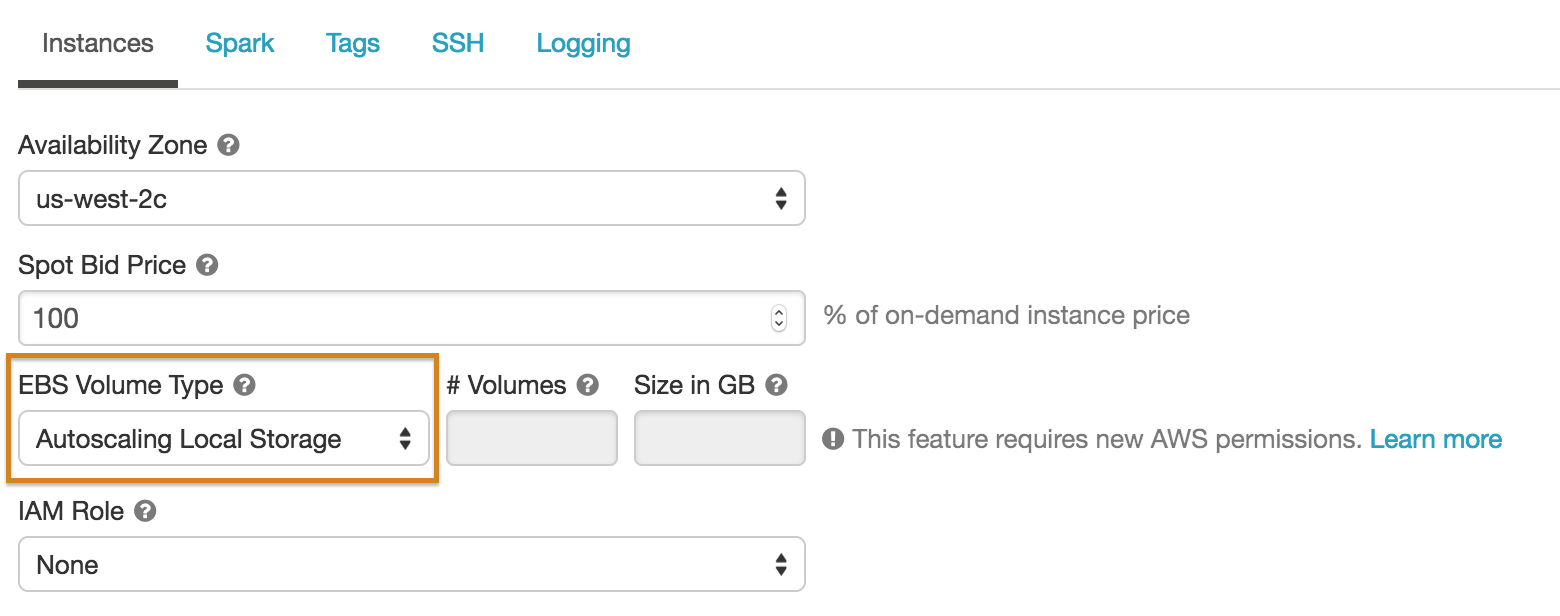
Optimal Provisioning: These EBS volumes are provisioned only for the workers that need them. For large data sets with heavy skew, attaching additional volumes only when they are needed will tremendously reduce EBS costs.
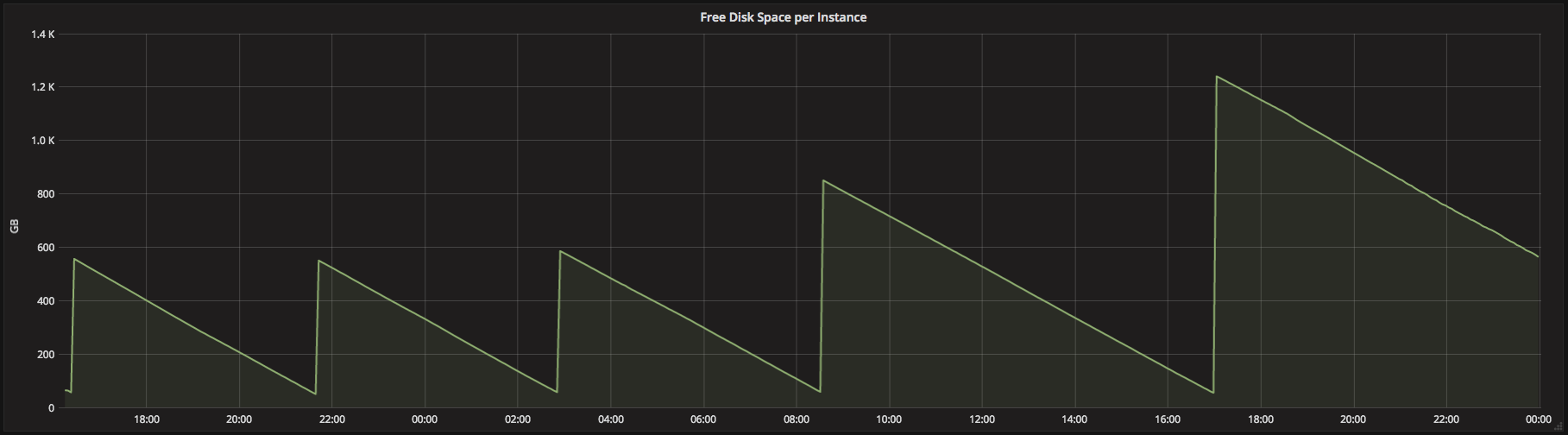
Figure 3. Graph showing the free disk space for an instance with autoscaling local storage turned on. Whenever the free disk space drops below our minimum threshold, we request another EBS volume and attach it to the instance. Subsequent requests allocate ever-larger EBS volumes until we hit a pre-configured maximum total disk space.
- Secure Provisioning: Users can optionally choose to encrypt all the data in the instance storage - both local storage and EBS volumes. This means that:
- Users no longer need to worry about meeting their security compliance requirements. All data at rest is encrypted.
- Security-conscious users can take advantage of instances with high-throughput local disks, since the data stored in the local storage will be encrypted.
Serverless and Autoscaling Instance Storage
We announced Databricks Serverless in Spark Summit in June 2017 with the goal of making it easier than ever for multiple data scientists to access the full power of Apache Spark without having to deal with cumbersome infrastructure setup. Autoscaling instance storage is automatically enabled in Serverless, which complements Serverless' auto-scaling compute resources.
Conclusion
Databricks’ autoscaling instance storage allows users to run jobs without worrying about how much disk space they will need. Autoscaling local storage takes the guesswork out of provisioning disk, adds storage only for instances that need them, and makes instance local disks available for security-conscious users by encrypting all data stored in the instance storage. The result is a simpler, cheaper, more secure way to get value from your data.
Sign up for a free trial of Databricks to see autoscaling instance storage in action. If you would like to see a demo, register here.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.