Securely Managing Credentials in Databricks
by Eric Wang
Customers today leverage a variety of data sources to perform complex queries to drive business insight. For example, to better understand user behavior, an analyst might correlate click-through analytics streams from their data warehouse with customer metadata from Salesforce. The Databricks Runtime provides a variety of built-in Apache Spark™ data source connectors (AWS | Azure), serving as the perfect entry point for your data analysis needs.
However, integrating with heterogeneous systems requires managing a potentially large set of credentials, precisely distributing them across an organization. Security is an essential concern for every individual or business. In the spirit of helping our customers enforce security mindfulness, Databricks has introduced Secret Management (AWS | Azure), which allows users to leverage and share credentials within Databricks in a productive yet secure manner.
This blog post discusses the improvements that we've added and recommends new practices for securely leveraging credentials.
Secret Management
Design Principles
When we were designing Secret Management, we analyzed the existing workflows of the Databricks ecosystem. Our goal was to expand on this existing state, specifically to improve our customers' ability to connect securely to external data sources. We recognized three essential properties that any new system needs to address:
- Credential leakage prevention - Accidents happen, and sometimes users can accidentally leak credentials via log messages to notebook outputs. This puts the credentials at risk of exposure, since Databricks notebooks automatically snapshot notebook contents as part of revision-history tracking. These snapshots store both command content and cell output, so if a notebook is shared, another user could revert to an older snapshot and view the printed secret value. Any new system should strive to keep security teams at ease by preventing accidental secret leakage from occurring altogether.
- Access control management - Different teams within an organization interact with credentials for different purposes. For example, an administrator might provision the credentials, but teams that leverage the credentials only need read-only permissions for those credentials. Supporting fine-grained access control allows teams to reason properly about the state of the world.
- Auditability - Leveraging credentials is a sensitive operation. Security teams need historical usage records to meet compliance needs and enable accurate responses to security events.
Databricks built Secret Management with these core concepts in mind to improve the customer experience of using secrets in a comprehensive management solution.
Concepts
This new feature introduces the following concepts to help you organize and manage your secrets:
- Secret Scopes - The logical grouping mechanism for secrets. All secrets belong to a scope. Scopes are identifiable by name and are unique per user's workspace. Typically, the name describes its use case or ownership. Examples:
jdbcorclickstream-db. - Secrets - A key-value pair that stores the secret material. Keys are identifiable secret names, and values are arbitrary data that can be interpreted as strings or bytes.
- Secret ACLs - Access control rules applied to secret scopes. Secret scopes and their secrets can only be accessed by users with sufficient permissions. For example, an admin user can grant the
datasciencegroup read-only access to thejdbcsecret scope.
We provide a Secrets REST API (AWS | Azure) and Databricks CLI (AWS | Azure) (version 0.7.1 and above) commands to create and manage secret resources.
Example Workflow
In this example, we use Secret Management to set up JDBC credentials for connecting to our data warehouse via JDBC. All commands in this example use the Databricks CLI to manage secrets.
Set up the secret
We start by creating a secret scope called jdbc with secrets username and password to bootstrap the Spark JDBC data source.
First we create our scope:
databricks secrets create-scope --scope jdbc
Now we bootstrap our secrets: username and password. We execute the following commands and enter the secret values in the opened editor.
databricks secrets put --scope jdbc --key username
databricks secrets put --scope jdbc --key password
Use the secret in a notebook
We want to use our provisioned credentials in a notebook to bootstrap our JDBC connector. As a reminder, the canonical method for bootstrapping a JDBC connector is as follows:
import java.util.Properties
val connectionProperties = new Properties()
connectionProperties.put("user", "$YOUR_USERNAME")
connectionProperties.put("password", "$YOUR_PASSWORD")
connectionProperties.put("useSSL", "true")
connectionProperties.put("trustServerCertificate", "true")
val jdbcUrl =
s"jdbc:mysql://${jdbcHostname}:${jdbcPort}/${jdbcDatabase}"
val dataFrame = spark.read.jdbc(jdbcUrl, "my_data", connectionProperties)
Note that this snippet involves inserting your credentials in plaintext in the notebook, which potentially exposes them via notebook snapshots. The previous snippet is not a secure or recommended practice. Here's how we adjust this snippet to leverage secret management:
import java.util.Properties
val connectionProperties = new Properties()
connectionProperties.put("user", dbutils.secrets.get(scope = "jdbc", key = "username"))
connectionProperties.put("password", dbutils.secrets.get(scope = "jdbc", key = "password"))
connectionProperties.put("useSSL", "true")
connectionProperties.put("trustServerCertificate", "true")
val jdbcUrl =
s"jdbc:mysql://${jdbcHostname}:${jdbcPort}/${jdbcDatabase}"
val dataFrame = spark.read.jdbc(jdbcUrl, "my_data", connectionProperties)
In this version, the only difference is that we've replaced our plaintext credentials with invocations to dbutils.secrets.get, which securely fetches our previously bootstrapped credentials from our jdbc secret scope. We've added various helper methods for reading secrets in notebooks in the Databricks Utilities SecretUtils (AWS | Azure) library, available via dbutils.secrets.
We have now set up a DataFrame that uses JDBC to talk to our data source, authenticated using our securely managed credentials. The additional steps in our workflow are minimal but critical for enforcing a secure workspace environment.
Values fetched from a secret scope are never displayed in a notebook. If a user accidentally prints their secrets in their notebook output, the credentials are displayed as redacted and saved from exposure!

Grant access to another group
After we verify that the credentials were bootstrapped correctly, we want to share these credentials with the datascience group to use in notebooks for their analysis.
We grant the datascience group read-only permission to these credentials by making the following request:
databricks secrets put-acl --scope jdbc --principal datascience --permission READ
Now any member of that group can read these credentials, and we only need to manage a single set of credentials for this use case in Databricks!
Technical Details
With any security-minded feature, a primary concern is to understand how customer data is encrypted. Databricks platform and Secret Management is available on both AWS and Azure, and leverages each cloud's respective key management services, AWS Key Management Service (KMS) or Azure KeyVault, for key management and encryption. This allows us to take advantage of both providers' existing trusted solutions, with built-in security to meet compliance standards. Databricks uses a per-customer key provided by the cloud service to encrypt all secrets stored in Databricks Secret Management. The data is stored encrypted-at-rest in an isolated database managed by our control plane.
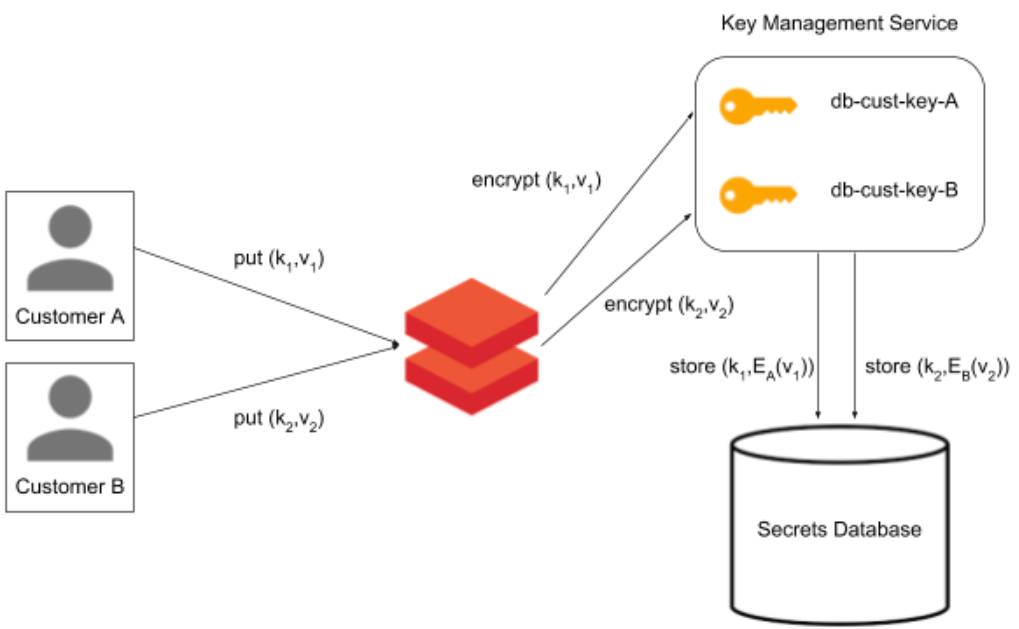
Figure 1: Example diagram of data flow of secrets when stored in Databricks Secret Management. Secrets are stored encrypted-at-rest using a per-customer encryption key.
Databricks believes in keeping security simple, so it is easy to scrutinize and validate. Our data model for secrets is straightforward, and one aspect is our design for preventing data-at-rest tampering. To protect each secret record, we store both the secret literal value and its metadata as an encrypted blob. The unencrypted metadata is stored with the encrypted blob per record, which allows us to verify that the data record has not been tampered with. If an unauthorized user were to obtain access to the database, they could not manipulate the data at rest even by swapping the secret records. When decrypted, the metadata is validated to enforce that the fetched secret matches the correct secret name, scope, and organization of the request.
| scope_name | key_name | customer_id | encrypted_blob | |
| Row 1 | sX | k1 | cA | EA(k1, sx, ca, v1) |
| Row 2 | sY | k2 | cB | EB(k2, sY, cB, v2) |
| Row 3 | sZ | k3 | cB | EB(k3, sZ, cB, v3) |
Table 1: Example schema for records stored in Databricks secret database. The secret literal value is stored encrypted with its metadata, identifying the key, scope, and organization. This information is validated during any access attempt to protect against tampering of the underlying data encrypted-at-rest.
We run a dedicated secret management service in each control plane. Only this service has sufficient permissions to make requests to the cloud provider key management service to encrypt and decrypt data. Additionally, reading secrets from the Databricks Secret Management can only be performed using the Databricks Utilities command dbutils.secrets.get, supported only from notebooks and jobs. We do not provide any API endpoints to read secrets. Storing customer secrets securely is our most important concern, and enabling users to pull secrets in a simple fashion can unfortunately become an attack vector for our customers' data.
Lastly, we provide audit log records for all access to secret management. All API requests, including failed access attempts, are tracked and delivered to the customer via the Databricks Audit Log feature (AWS | Azure). By leveraging these audit logs, customers have a comprehensive view of the lifetime of secrets within the Databricks ecosystem.
Conclusion
In this post, we introduced the Secret Management feature in Databricks, which allows customers to securely leverage and share their credentials for authenticating to third-party data sources. This feature is generally available for all Databricks platforms. The Databricks Utilities for reading secrets are available only on clusters running Databricks Runtime 4.0 and above.
For full details about this feature, take a look at the Secrets User Guide (AWS | Azure), which provides in-depth instructions for applying these security concepts. We hope to see everyone adopt our updated security practices, which will improve both product usability and security risk management.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.