How to Use MLflow, TensorFlow, and Keras with PyCharm
Simple steps to get started on your favorite Python IDE
by Jules Damji
Free Edition has replaced Community Edition, offering enhanced features at no cost. Start using Free Edition today.
At Data + AI Summit in June, we announced MLflow, an open-source platform for the complete machine learning cycle. The platform’s philosophy is simple: work with any popular machine learning library; allow machine learning developers to experiment with their models, preserve the training environment, parameters, and dependencies, and reproduce their results; and finally deploy, monitor and serve them seamlessly—all in an open manner with limited constraints.
All that is important. Equally important—no matter the philosophy or design principles—are factors that make the platform easy to use:
- Minimal effort to get started
- Easy and intuitive set of developer APIs that make developers productive
- Vibrant community, voluble documentation, and code examples to learn from.
In this blog, we will focus on one of the factors: Minimal time to get started. In upcoming blogs, we will elaborate on the other factors, albeit we’ll briefly mention them here.
Let’s consider the level of effort it takes to get started using MLflow in your favorite IDE.
Quick Start, Minimal Effort: Python and PyCharm
Python seems to be the most popular programming language for machine learning. Most common machine learning frameworks such as TensorFlow, Keras, PyTorch, and Apache Spark MLlib provide Python APIs.
As a result, many Python developers elect PyCharm as an IDE. Why? For one, it offers a Community Edition. Second, it creates a Python Virtual Environment or Conda Environment, without you having to explicitly do it. And third, if you have used IntelliJ, you are set to flow—all that counts toward minimal effort to get started.
For you to use MLflow along with your machine learning models developed with TensorFlow or Keras APIs, three simple steps will get you ready to flow.
- Download PyCharm CE for your laptop (Mac or Linux)
- Create a project and import your MLflow project sources directory
- Configure PyCharm environment.
By default PyCharm creates Python Virtual Environment, but you can configure to create a Conda environment or use an existing one.
This short video details steps 2 and 3 after you have installed PyCharm on your laptop.
MLflow Keras Model
Our example in the video is a simple Keras network, modified from Keras Model Examples, that creates a simple multi-layer binary classification model with a couple of hidden and dropout layers and respective activation functions. Binary classification is a common machine learning task applied widely to classify images or text into two classes. For example, an image is a cat or dog; or a tweet is positive or negative in sentiment; and whether mail is spam or not spam.
But the point here is not so much to demonstrate a complex neural network model as to show the ease with which you can develop with Keras and TensorFlow, log an MLflow run, and experiment—all within PyCharm on your laptop.
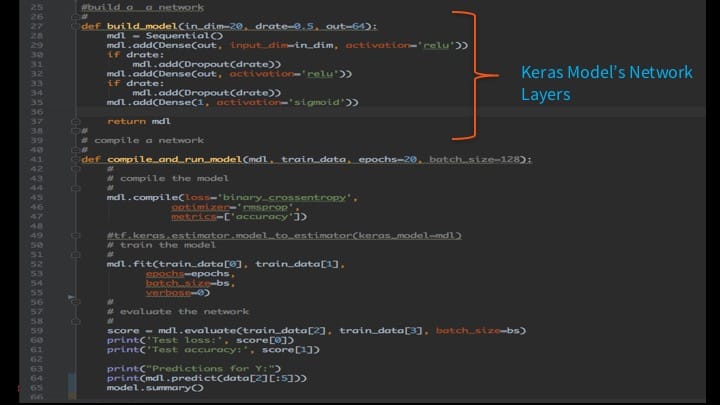
With default or user-specified tuning parameters as command line arguments, keras_nn_model.py can be executed, tracked, and experimented with MLflow in two ways: with command line or from PyCharm.
Command Line: Specify tuning parameters as arguments
python keras/keras_nn_mode.py --drop_rate=0.3 --epochs=40 --output=64 --train_batch_size=256
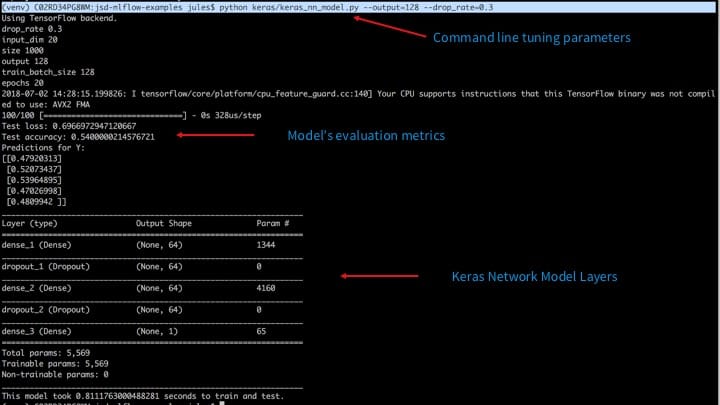
PyCharm: Specify parameters as arguments in the run configuration
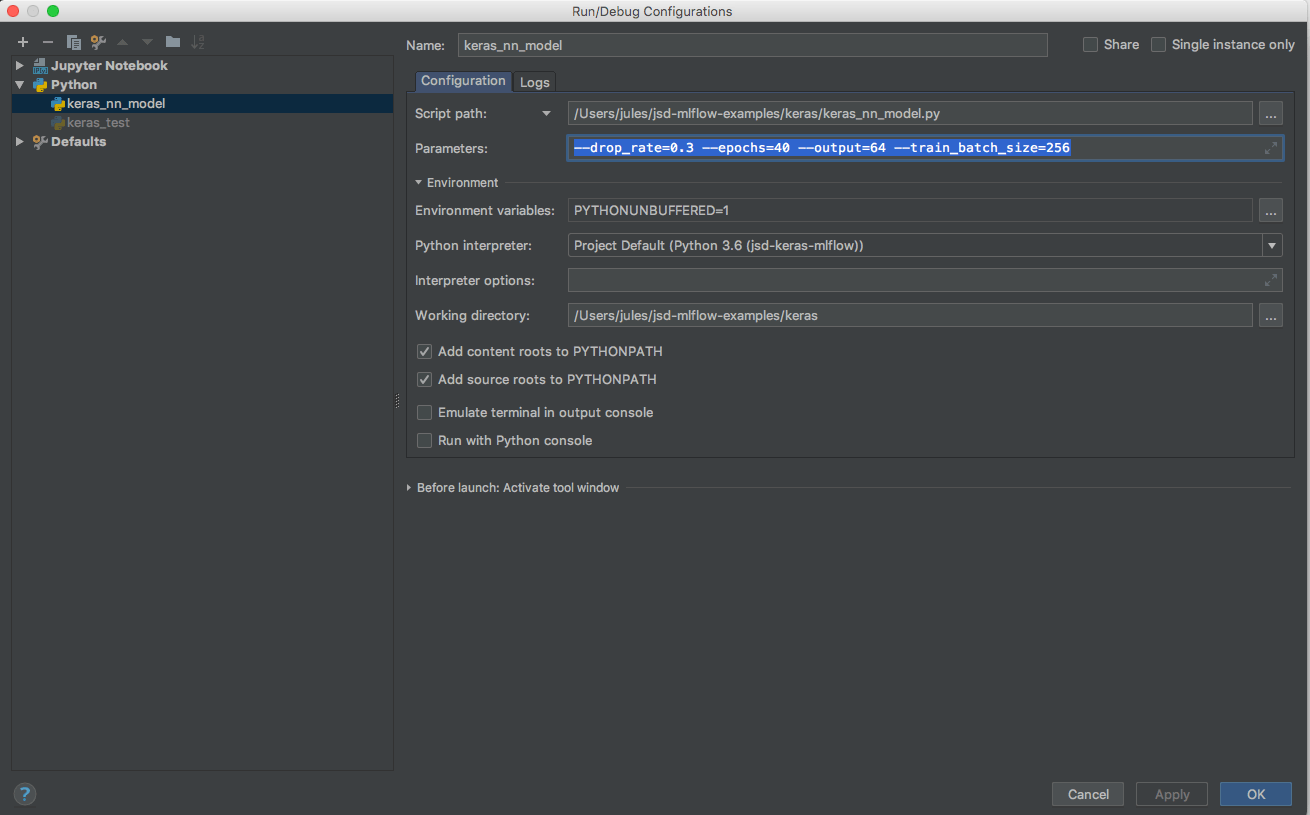
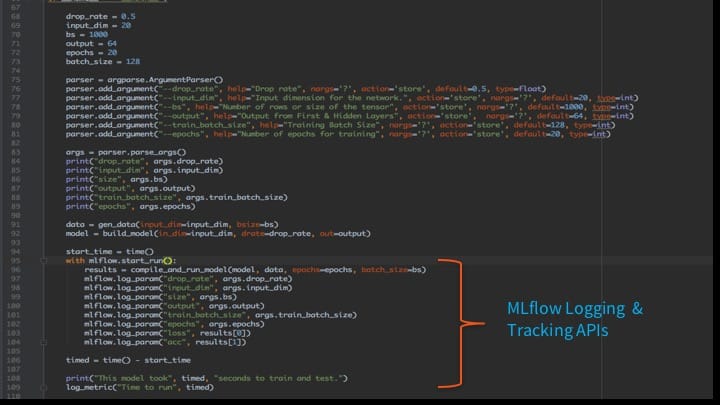
Whether run from the command line or from PyCharm, all parameters and resulting metrics are logged using the mflow.log_param() APIs as seen here:
Visualizing Your Runs in MLflow
You can repeat the experiments in either modes—command line or PyCharm—and view your results within the MLflow ui.
mlflow ui

Examining your runs and its respective metrics in the MLflow UI gives you insight into how your model performs with different tuning parameters.
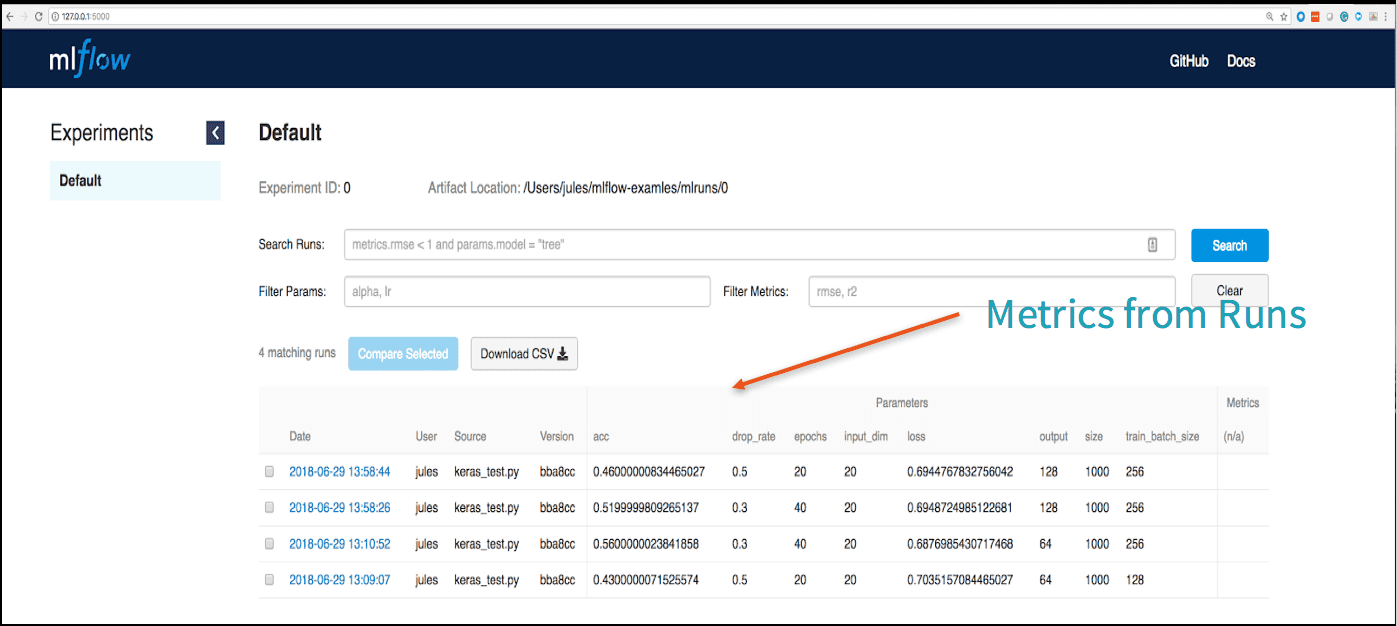
Having examined some runs, what’s next for you? You can do one of two things.
Use this dashboard as a leaderboard to compare other models and their respective runs inside your organization. Or save the model for deployment if satisfied with runs. Read the documentation to learn how to deploy MLflow models.
Easy APIs, Documentation, and Code Examples
Earlier in the blog, we noted that three factors that make a platform easier to use. We detailed the first one—easy of use. Next, we want to briefly share our core design philosophy for MLflow that contributes to the two other factors.
First, we designed MLflow with API-first principle and open-source, with Python APIs, meaning that these APIs are designed to offer developer building blocks to extend and employ MLflow’s three core components: Tracking, Projects, and Models. Along with REST APIs and Command Line Interface, these APIs enable developers to carry out complex machine learning lifecycle tasks:
- Experiment and track with parameters and log metrics locally or remotely
- Save models in default storage or custom formats for deployment in many environments (Docker, Azure ML, Databricks, or Apache Spark UDF) and reload wherever you can run Python code
- Package MLFlow projects as self-described and self-contained entities reusable and reproducible by others from GitHub repositories
And second, we have good documentation for you to get started, and we are earnestly building a community of contributors. While existing code examples will get you started, overtime this repository of samples will grow in scope with your contributions. You can start pursuing some MLflow projects at mlflow-examples and examine this blog’s Keras network model here.
So to recap, three factors affect platform’s ease of use: quick developer start time; intuitive APIs with docs and code samples; and emerging community. We touched on all three aspects, and you can help with them too.
What’s Next
Here are some ways you can learn more about MLflow or even contribute:
- Join our Google User Group, MLflow Meetup, and MLflow Slack channel
- Contribute on GitHub: https://github.com/databricks/mlflow
- Try MLflow Project Examples: https://github.com/mlflow/mlflow-apps
- Find out more at www.mlflow.org
- Read our blog: Introducing MLflow: an Open Source Machine Learning Platform
- Find out what's new in MLflow v0.2.1
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.